
DISCLAIMER: The opinions and views expressed in this report are those of the author. They do not necessarily reflect the views of the Department of Health and Human Services, the contractor or any other funding organization.
TABLE OF CONTENTS
- RESULTS
- Understanding the Cohort Effects
- Uncertainty Associated with the Matching Process
- APPENDIX 1: SCHEMATIC REPRESENTATION OF MATCHING ALGORITHM
- LIST OF FIGURES
- FIGURE 1: Scatterplot of Number of Donors by Number of Targets: Cycle 1 of Imputation
- FIGURE 2: Age Profile of P[ADLs=1], Observed and Simulated
- FIGURE 3: Age Profile of P[ADLs=2+], Observed and Simulated
- FIGURE 4: Percentage Increase in Standard Error of Pr[ADLs=...] Due to Imputation
- LIST OF TABLES
- TABLE 1: Prevalence of Any Disability, by Age and Cohort: Observed and Simulated
- TABLE 2: Prevalence of ADL Disabilities in Future Waves, Conditional on Match Criterion
The following acronyms are mentioned in this report and/or appendix.
| ADL | Activity of Daily Living |
| DI | Disability Insurance |
| DYNASIM3 | Dynamic Simulation of Income Model |
| FEM | Future Elderly Model |
| HRS | Health and Retirement Study |
| IADL | Instrumental Activity of Daily Living |
| MINT | Model of Income in the Near Term |
| SE | Standard Error |
| SIPP | Survey of Income and Program Participation |
Objectives
This project investigates the use of record matching to create lifetime profiles of disability. Disability is a key factor in determining the need for long-term care services, but available data do not depict individuals' lifetime care needs. A number of policy-oriented microsimulation programs have been developed to fill this gap, all of which use some sort of econometric model to project disability levels or profiles. This project explores a simpler, model-free approach based on the creation of synthetic profiles.
Methods
Observed sequences of disability variables covering 12-year periods of peoples' lives are matched on the basis of common values of the disability indicators, within gender groups and narrow bands of age. Each of four match "cycles" adds ten more years of simulated or imputed information to the observed data, ultimately producing synthetic longitudinal data records spanning up to 52 years of experience.
Data
I used data from the Health and Retirement Survey, specifically for years 1998-2010. Disability is represented by a categorical variable distinguishing among those with difficulties in 0, 1 or 2 or more of a set of six Activities of Daily Living (ADLs).
Results
The matching algorithm produces synthetic age profiles of disability that are most readily depicted as cohort profiles. The results indicate that for each of three successive cohorts--those age 70-79 in 1998, 60-69 in 1998, and 50-59 in 1998, the prevalence of both moderate (1 ADL) or more severe (2+ ADLs) disability late in life (after the mid-80s) will be strikingly lower than what was observed directly over the 1998-2010 period. These cohort figures are not easily compared to the period projections produced by other microsimulation approaches, but they do seem to contrast sharply with the other projections. The results produced here are based on cohort differences only, whereas other microsimulation models appear to overlook cohort effects. These differences suggest needs for further refinement of both sorts of projection methods.
Introduction
Microsimulation is well established as a tool for social science research and policy analysis. Key features of microsimulation are its ability to depict outcomes at the individual level and to assign values to otherwise-unobserved future outcomes or outcomes that would be anticipated in alternative ("counterfactual") policy regimes. While widely used in the area of tax and transfer programs, microsimulation is finding growing use in the area of health and long-term care, both in the United States and elsewhere.
Several existing models have been used to simulate the population needing long-term care in the United States. These models vary with respect to the way in which they represent and project the variables that measure care needs, as well as with respect to the complexity of the model used to assign simulated outcomes. Many if not all of these models represent "activity based" needs for care, including measures of the need for help with ADLs such as mobility, eating, dressing, bathing, toileting, and transfer in or out of a bed or chair, or with Instrumental Activities of Daily Living (IADLs) such as laundry, housework, and meal preparation. Examples include the Future Elderly Model (FEM), which employs an econometrically complex 21-equation model that includes measures of ADL and IADL limitations, the Brookings/ICF model, which uses a system of equations to assign one-year transitions among four disability states, and Dynasim3, which adopts a "current status" approach when assigning disability levels to individuals simulated to be 65 and older in 2010, 2020, 2030 and 2040. In complex models such as these, it may be difficult to determine which of many elements of the model--input data, model specification, functional forms, and range of included variables--are responsible for producing predicted future levels of disability prevalence.
Paradoxically, at the same time that microsimulation projections can be criticized for their complexity, they can also be criticized for their simplicity, in particular for the simplifying assumptions that they adopt with respect to disability dynamics. Both the FEM and the Brookings/ICF models employ what is basically a first-order Markov assumption: next year's (or, next period's) value of disability depends on the current value of disability but not on any prior values of disability. In contrast, recent research on disability "trajectories" has emphasized longitudinal patterns of disability over longer periods of time in people's lives, while avoiding the need to impose strong assumptions on the underlying dynamics of disability.
This report presents an alternative to the model-based projection of long-term care needs. Rather than first estimating some sort of econometric model that explains levels or transitions in one or more need variables, it relies on matching techniques to string together partial life cycle sequences of need variables so as to produce a "complete" life history--the quotes added in recognition of the fact that due to the data used here, the life histories I produce begin at age 50. While ages 50 and older admittedly cover only part of the life cycle, they do represent a large share of the ages at which long-term care needs arise.
Data
I used data from the 1998-2010 waves of the Health and Retirement Study (HRS), a panel study that relies mainly on extensive interviews taken every two years. Individuals are distinguished by gender, a fixed characteristic, and by age and disability status in each survey wave. The disability indicator is based on a count of the number of ADLs for which the sample person is reported to have a difficulty. I code people as having 0, 1, or 2+ ADL limitations (using numeric codes 0, 1, and 2 respectively). I add a fourth category indicating the person's death. Thus the observed data for each individual consists of up to seven consecutive disability indicators along with their gender and their age at the time of each disability measurement. The measures are taken at two-year intervals, so these partial trajectories span a 12-year period in the individuals' lives.
The Matching Algorithm and Its Implementation
A key assumption underlying the matching algorithm used here is that all the observed partial trajectories come from the same population of lifetime (i.e., from age 50 onwards) trajectories. Based on this assumption, I match records that have identical ADL variable for two consecutive waves of data, while also matching exactly with respect to gender, and approximately with respect to age. To illustrate, someone initially observed at age 50, with disability indicators observed at ages 50, 52, ..., 62, would be a "target" for matching to a "donor" who was initially observed at age 60, with disability indicators for ages 60, 62, ..., 72, but with exactly the same values of the ADL indicator at ages 60 and 62, the two ages the records have in common. Matching is continued through four "cycles," each of which adds ten more years of imputed disability indicators to the original data. I repeat the entire matching program a total of five times, producing five independent and probabilistically identical synthetic-lifetime data sets. These are combined into a single global estimate using the tools of multiple imputation.
Results
The matching algorithm produces age profiles of disability that are most readily presented in the form of cohort profiles. The resulting profiles project disability prevalence that is roughly in line with, or even slightly higher, through age 85 compared to what is observed directly in the HRS; it is only after age 85 that disability prevalence is projected to fall, rather substantially, for three cohorts (70-79, 60-69, and 50-59 in 1998). While these projected changes for the oldest-old may appear implausibly large, they can be shown to be in line with at least some recent trends. Over the roughly 2000-2040 period the results suggest average annual declines in disability prevalence on the order of 0.5%-1%, which is plausible in view of recent attempts to synthesize what is known about observed disability trends from national-level data.
Assessment and Summary
From a methodological standpoint, this study demonstrates the feasibility of applying file-matching techniques to a sample of partial trajectories--that is, "excerpts" from individuals' lifetime experience of disability--to create synthetic "unabridged" lifetime profiles. Substantively, the synthetic-lifetime disability profiles produced by matching imply a substantial reduction in the prevalence of ADL disabilities among the oldest-old through about 2040. While rather striking, these reductions turn out to be consistent with a continuation (and even some dampening) of trends found in survey data collected during the 1990s and early 2000s. However, they appear to diverge from the projections produced by both the FEM and Dynasim3 approaches, neither of which appearto recognize cohort effects. My matching approach rests on cohort effects exclusively, suggesting an area for further model development and refinement.
Microsimulation is well established as a tool for social science research and policy analysis (Orcutt et al. 1976; Gupta and Kapur 2000). The "micro" in microsimulation refers to its depiction of outcomes at the individual level, generally that of the person in policy-oriented microsimulation. The "simulation" part of the term refers to the assignment of "counterfactual" (or otherwise-unobserved) outcomes, whether they are unobserved because they were not included in the input data that underlies the analysis, or because they will occur in the future, or because they are to occur under policy regimes other than those in effect at the time or in the place where the input data were collected. Assignments are made following rules that usually include a random as well as a systematic component. While widely used in the area of tax and transfer programs, microsimulation is finding growing use in the area of health and long-term care, both in the United States (Rivlin and Wiener 1988) and elsewhere, including Italy (Baldini, Mazzaferro and Morciano 2007), Japan (Fukawa 2011) and the United Kingdom (Hancock et al. 2003; Fernández and Forder 2010).
Several existing models have been used to simulate the population needing long-term care in the United States. These models vary with respect to the way in which they represent and project the variables that measure care needs, as well as with respect to the complexity of the model used to assign simulated outcomes. Many if not all of these models represent "activity based" needs for care, including measures of the need for help with Activities of Daily Living (ADLs) such as mobility, eating, dressing, bathing, toileting, and transfer in or out of a bed or chair, or with Instrumental Activities of Daily Living (IADLs) such as laundry, housework, and meal preparation.
For example, the Future Elderly Model (FEM) described in Sullivan et al. (2013) employs an econometrically complex model with 21 endogenous variables, two of which (ADL status, coded no ADLs, 1 ADL, 2 ADLs, and 3+ ADLs; and IADL status, coded no IADLs, 1 IADL, and 2+ IADLs) are relevant here. Each of these outcomes is simulated based on an ordered Probitequation. Sullivan et al. (2013) characterizes these as models of "transitions," although strictly speaking they are models of levels (or, "current status"), each of which condition on the most recent lagged values of those same outcomes (along with all the other endogenous outcomes, plus exogenous regressors). These equations do indeed imply transition probabilities without having to explicitly represent the occurrence of transitions in the outcome space. For example, direct modeling of ADL transitions in the four-level ADL space would typically entail the estimation of four multiple-category outcome equations, one for each lagged value of the outcome variable. The FEM approach reduces these initial state-specific equations to a single equation, thus achieving a very large reduction in the number of parameters to be estimated, but at the cost of imposing numerous restrictions on the underlying model.
Another example is the Brookings/ICF microsimulation model, which uses a system of equations to assign one-year transitions among states in the set "IADL only," "1 ADL," "2+ ADLs," and "none" (i.e., no disability present). A separate equation assigns people to enter a nursing home (Kennell et al. 1992). Although few details of these predictive equations are provided, the discussion in Kennell et al. (1992) suggests that relatively few predetermined variables are used in the predictions. This, in turn, implies a substantial amount of homogeneity of long-term care needs in the overall population.
A final example of a long-term care microsimulation is the version of Dynamic Simulation of Income Model (Dynasim3) used in Johnson et al. (2007). Unlike the previous two examples, this version of Dynasim3 makes no attempt to project disability dynamics at the individual level; rather, its goal is to characterize the population with long-term care needs in cross-section in selected future years (2010, 2020, 2030 and 2040). Accordingly, the predictive equation used assigns a "current" value of long-term care needs (no disability; IADL needs only OR 1-2 ADLs; 3+ ADLs) in each forecast year that depend on predetermined (but also "current") variables that year, including the individual's nearness to death at the time. The latter variable can be used in the simulation because Dynasim3 assigns someone's time of death prior to the assignment of several other outcomes that precede death.
Microsimulation is often criticized for its complexity. In a complex model such as that built into FEM, a large number of current values of endogenous variables collectively determine next year's disability status. This dynamic process can be repeated arbitrarily many times, extending far into a hypothetical future. In the absence of calibration of predicted outcomes to an external "control" series, such a model's predicted disability prevalence may wander off in unexpected directions, and it may be quite difficult to establish which parts of the model are responsible for such results. Even in the less-complex approaches found in the Brookings/ICF and Dynasim3 simulations, there are sufficiently many predictor variables--many of which must themselves be projected forward--to make difficult the job of figuring out the sources of variation in predicted future levels of disability prevalence.
Paradoxically, at the same time that microsimulation projections such as those summarized here can be criticized for their complexity, they can also be criticized for their simplicity, in particular for the simplifying assumptions that they adopt with respect to disability dynamics. Both the FEM and the Brookings/ICF models employ what is basically a first-order Markov assumption: next year's (or, next period's) value of disability depends on the current value of disability but not on any prior values of disability. In both models, disability over longer intervals may exhibit correlations due to the inclusion of persistent "random effects" or through conditioning on fixed, or relatively fixed, covariates. Nevertheless, the Markov assumption is quite restrictive and almost certainly would be rejected in any formal test. A particular problem associated with "transition" models for disability status (such as those used in the Brookings/ICF model) is their use of pairs of "current status" variables to estimate the occurrences of transition "events" despite the fact that transitions are not explicitly represented in the data. Instead, when current disability status at time t and time t + 2 years (as in the case for the two models mentioned above) is the same, the analyst assumes that there has been no event, whereas if disability status at times t and t + 2 are different, the analyst assumes that there has been exactly one event. Research based on monthly current status data has shown that transition models based on two-year interval data can produce wildly inaccurate estimates of transition probabilities (Wolf and Gill 2009).
In other respects, the predictive equations used in long-term care microsimulations are subject to the same criticisms that can be leveled at any statistical model: they assume some sort of functional form, which may be incorrect; they may fail to include various interactions among explanatory variables; they almost surely omit key variables; they may misspecify the stochastic components of the model; and so on. Any and all of these modeling errors can affect the conclusions based on the simulated output, and may do so in ways that are quite challenging to uncover.
This report presents an alternative to the model-based projection of long-term care needs. Rather than first estimating some sort of econometric model that explains levels or transitions in one or more need variables, it relies on matching techniques to string together partial life cycle sequences of need variables so as to produce a "complete" life history--the quotes added in recognition of the fact that due to the data used here, the life histories I produce begin at age 50. While ages 50 and older admittedly cover only part of the life cycle, they do represent a large share of the ages at which long-term care needs arise.
The importance of disability dynamics is increasingly recognized in the gerontology and long-term care literatures. The "disablement process" model (Verbrugge and Jette 1994) emphasizes the multi-staged process culminating in the onset of disabling conditions, as well as behavioral responses and interventions that may ameliorate those conditions, along with a number of feedback loops that have the potential to alter the dynamic course of becoming and remaining disabled. It seems unlikely that a simple transition between pairs of discrete disability states can adequately capture these underlying complexities.
In recent years there has occurred rapid growth in the number of published papers on disability "trajectories" (i.e., on sequences of disability or functioning indicators observed and tracked at the individual level). Among the numerous examples of such work is Ferraro et al. (1997), Dodge et al. (2006), Liang et al. (2009), Chiu and Wray (2010), Wickrama et al. (2013), and Rohlfsen and Kronenfeld (2014). A distinct advantage of these trajectory models is that they need not make any assumptions about the number and timing of disability transitions. The partial trajectory matching approach proposed here is in the spirit of these trajectory models, insofar as it makes no assumptions regarding the occurrence of transitions in the measured disability space.
The "simulation" algorithm presented here is quite simple and is easily explained. It also has the virtue of relying on no assumptions about functional form, random effects, and so on. It does, of course, require a number of assumptions, some of which are rather strong (although not, I would contend, stronger than those needed to justify the model-based approaches described above). The biggest drawback of the proposed approach, however, is that it is limited in scope. I apply it to only a single outcome--a three-category indicator of the severity of ADL difficulties--and stratify by only a single factor, gender.
Because of the heavy data requirements needed to carry out the matching algorithm, it seems unlikely that the matching approach could be extended to cover more than two or three jointly determined outcomes, unless unacceptably strong independence assumptions were imposed on the process. Nevertheless, the output produced in this exercise challenges the projections produced by several of the model-based approaches already in use, and thus seems to provide a useful addition to the suite of tools available to policy analysts.
This study uses an extract of data from the Health and Retirement Study (HRS), specifically the version "M" release of the RAND-HRS version of public use HRS data.1 The HRS is a panel study that relies mainly on extensive interviews taken every two years; details on its design and content can be found in an extensive set of online documents.2 I use data collected in the 1998-2010 surveys (called waves 4-10 in the documentation for the RAND-HRS file, a naming convention I adopt here). I use 1998 as my baseline year because that is the first year in which the HRS sample is representative of the entire population of persons aged 50 or more. Restricting the sample to those born by 1947, and who had not left the HRS sample or died by 1998, the full sample size for this analysis is 23,180.
A small number of data elements isneeded for the analysis presented here. Individuals are distinguished by gender, a fixed characteristic, and by age and disability status in each survey wave. The disability indicator is based on a count of the number of ADLs for which the sample person (or their proxy) responds affirmatively to the question "Because of a health or memory problem do you have any difficulty with ____?". The six activities included are getting across a room, bathing, eating, gettingin and out of bed, dressing, and using the toilet. Based on this count, I code people as having 0, 1, or 2+ ADL limitations (using numeric codes 0, 1, and 2 respectively). Using an "interview status" variable I add a fourth category indicating the person's death. The disability variable is coded as missing by definition in waves starting with the initial report of death. Missing values among cases not yet known to have died are rare, occurring in only 0.2% of cases (pooled over all waves, using years in which age is nonmissing). Cases with missing disability variables are, however, retained in this analysis.
THE MATCHING ALGORITHM AND ITS IMPLEMENTATION
Data augmentation by means of matching has a long history in social science research and policy analysis (Rubin 1986; Goel and Ramalingam 1989). In one form, data from two sources known to contain records on the same individuals--for example survey data and administrative records--are matched on the basis of common identifiers. Even in these "exact match" situations the data user must be mindful of the possibilities for erroneous matches. More relevant for the present exercise is the literature on techniques for matching on the basis of similarity rather than on a presumption of exactness.
If one data source contains individual level data elements X and Z, and another data source, sampled from the same population, contains individual level data elements Y and Z, then matching based on the equality of (or, the nearness of) values of Z in records found in the two files can produce a synthetic record for a hypothetical individual with characteristics X, Y, and Z. A major problem with this approach is the conditional independence assumption upon which it rests, namely that X and Y are independent conditional on Z. The typical use of this type of matching is to create synthetic cross-sectional data. The limitations on subsequent data analysis implied by this assumption are extensively discussed in Ridder and Moffitt (2007). I show how the matching approach proposed here relates to the problems associated with "data combination" that are raised by Ridder and Moffitt below.
In this study, the observed data for each individual consists of up to seven consecutive disability indicators (coded 0, 1, and 2), along with their gender and their age at the time of each disability measurement. The measures are taken at two-year intervals, so these partial trajectories span a 12-year period in the individuals' lives. Moreover, the observed partial trajectories begin (in 1998) at age 50 or older. A key assumption underlying the matching algorithm used here is that all the observed partial trajectories come from the same population of lifetime (i.e., from age 50 onwards) trajectories. Thus, although the disability patterns after age 62, for someone initially observed at age 50, are not included in the data, I assume that those post-age 62 patterns will be exactly like those exhibited by one or more of the records for people whose partial disability profiles are observed at those later ages in the data.
The specific matching criteria used here are that matched records agree exactly with respect to the ADL variable for two consecutive waves of data, while also matching exactly with respect to gender, and approximately with respect to age. To illustrate, consider someone initially observed at age 50, with disability indicators observed at ages 50, 52, ..., 62 corresponding to waves 4, 5, ..., 10. This person is a "target" for matching to a "donor" who was initially observed at age 60, with disability indicators for ages 60, 62, ..., 72. In order to be matched, the target and donor records must have exactly the same values of the ADL indicator at ages 60 and 62, the two ages the records have in common. For the target record, the disability match variable is defined using the ADL summary variables for wave 9 and wave 10. For the donor record, the disability match variable is defined using wave 4 and wave 5.
To illustrate, let D50, D52, ..., D62 be the sequence of disability indicators for person A, who is age 50, ..., 62 during the HRS observation period. Person B, who was 60 when first observed, has sequence D60, D62, ..., D72. To place this in the context of Ridder and Moffitt (2007), for purposes of matching A is part of the "base" sample and B is part of the "supplemental" sample. In the matching algorithm used here, A and B will be matched if D60 and D62 are identical in the two samples. The sequence D50, D52, D54, D56, and D58 correspond to "X" (observed only in the base sample), while D64, D66, D68, D70, and D72 (observed only in the supplemental sample) correspond to "Y." The common (matching) variables D60 and D62 correspond to "Z" and are of substantive interest here (which is not true in all matching exercises). Ridder and Moffitt are concerned primarily with the identification of parameters that require either {X, Y} or {X, Y, Z}; they point out that file-matching is not required because bounds on parameter estimates (which in some cases may vanish if exogenous information or identifying assumptions can be imposed) can be derived without matching.
After matching, the donor's ADL values for ages 64, 66, ..., 72 will be imputed to the target, who now has a 22-year simulated disability profile. The same procedure can be applied a second time for ages 70 and 72, which will extend the simulated disability profile to age 82, and so on. I carry out four such cycles, producing simulated disability profiles that extend 52 years beyond the 1998 baseline year (i.e., the 12 observed years plus four cycles of ten-year simulated increments to this span of time).
In order to carry out a cycle of matching, I first place all eligible donor records in a "donor pool." Each donor record is characterized by the disability matching criterion, coded "00," "01," "02," ..., "20," "21," and "22"--that is, the nine possible sequences of the three-category ADL summary variable--using wave 4 and wave 5, as described above. They are also characterized by their gender and their age. In order to have a sufficiently large pool of donors at each age, I have expanded the donor pool as follows: for ages 60-84, the donor pool for age "a" uses sample records with ages a - 1, a, and a + 1. For ages 84-94, the donor pool is expanded to include those with ages within two years of the target age, and for ages 95 on it is expanded to include those with ages within three years of the target age. In all cases the wave 4 age is used to create this pool. Thus the matching allows for a sort of "distance" metric to be used in the match. A more sophisticated version of this algorithm would assign inverse distance weights to those whose age is 1, 2, or 3 (and, with an expanded donor pool, even more) years different from that of the target record's age. Note also that any data record in the original extract which has a missing value for the ADL summary variable in wave 4 or wave 5 will be excluded from the donor pool.
The second step of a match cycle entails the creation of a "target pool," containing sample records characterized by their disability matching criterion (coded 00, ..., 22 as above, but now using wave 9 and wave 10 to define that criterion), gender, and age (at wave 9). As is the case for the donor pool, data records with missing values for the ADL summary variable in wave 9 or wave 10 will be excluded from the target pool. In each cycle of the match, those records excluded from the target pool due to missing values on the match criteria are reserved, and placed in a "nontarget" sample. After each match cycle is completed, the target and the nontarget samples are once again concatentated, so that the full sample of cases is always retained for purposes of producing summary statistics.
The matching process is facilitated using SAS's PROC SURVEYSELECT with its stratified sampling option. First, I produce a three-way cross-tabulation, using the records in the target pool, of the variables disability match criterion, gender, and age. The youngest age found in the target pool is 60; therefore with ages 60, ..., 109 (the oldest age found in the sample), there are as many as 50 (ages) × 2 (genders) × 9 (disability match criteria) = 920 distinct "strata" in the target pool. In practice, there are no more than 597 nonzero cells in the stratification table because many of the potential combinations do not appear in the data.3 Then, a single call to PROC SURVEYSELECT can produce a sample of donor records that contains the necessary number of records in each cell of the stratification table. I use simple random sampling with replacement to produce these samples of donor records. At this point, the matching process is completed by merging the target and donor files on the basis of disability match criterion, age, and gender. However, because I repeat the series of match cycles multiple times, treating the matching (simulation) process as a form of multiple imputation, I randomly reorder the donor sample within strata prior to file merging. This is because PROC SURVEYSELECT's output records are in the same order each time (although they do not contain exactly the same set of records each time). The random reordering is used to ensure full randomization when donor and target records are matched. A somewhat more complete depiction of the matching-merging sequence is shown in outline form in Appendix 1.
The feasibility of record matching depends in part on the adequacy of sample size in each cell of the joint distribution of matching variables. In particular, there must be sufficient numbers of records in the donor pool to supply the matching records needed in each cell of the stratification table. In the present case, feasibility is enhanced by the use of a modest number of integer-valued matching variables. Matches that use continuous variables as matching criteria, such as income or earnings, may deal with the cell size problem by creating categorical income or earnings variables for purposes of matching, or defining their donor "cells" with respect to (continuous) distance metrics rather than a multiway contingency table.
Figure 1 is a scatter diagram showing the number of cases in each cell of the donor pool against the corresponding number in the target pool. For reference purposes, the dashed line represents equal numbers in both pools (with a slope much less than 45 degrees, reflecting the difference in scale of the two axes).4 It is clear that a great many of the target pool cell sizes are very small (1-3 cases) and that the corresponding donor pool cell sizes are considerably larger in nearly all cases. In only three cases are there fewer donor than target records, and this shortage is handled by the use of the "sampling with replacement" option. Alternatively, the donor pool could be expanded in size, possibly by loosening the distance criterion used for matching on age. Note also that a record in my HRS sample can appear in both the donor and the target subsamples, although on any given match cycle the age variable that locates them in the stratification table will be different in their "donor" role from what it is in their "target" role.
FIGURE 1. Scatterplot of Number of Donors by Numb
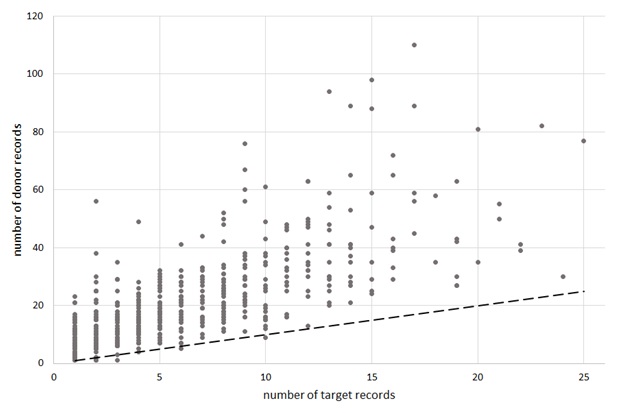
The number of cells in the target population becomes smaller for each cycle of the matching algorithm, because the number of ages covered under each successive matching cycle is fewer: in the first cycle of matching, ages 60 and older are used; in the second, only ages 70 and older are needed, and so on; in the fourth and final cycle of matching only ages 90 and older are used.
Finally, as indicated earlier I repeat the entire matching program a total of five times, each of which uses an independently-selected sample from the donor pool at each stage of the matching, producing five independent and probabilistically identical synthetic-lifetime data sets. I combine the results from each into a global estimate using the tools applicable to the analysis of multiply imputed data (Raghunathan 2004).
Because there is only a single simulated outcome in this exercise--the ADL summary variable--the results can be displayed quite simply in graphical form. Figure 2 and Figure 3 show the main results of the matching algorithm. Figure 2 plots age profiles for the proportion at each age with 1 ADL problem, and Figure 3 shows the corresponding profiles for the proportion with 2+ ADLs. In each case, the observed age profile, based on pooling of input data for all waves and all ages, is shown for reference purposes. I also show simulated profiles for three cohorts: those aged 50-59 in 1998, those aged 60-69 in 1998, and those aged 70-79 in 1998. The results are rather dramatic, although only at advanced ages (from mid-80s onward), and especially so for the more severe category (2+ ADLs, shown in Figure 3).
FIGURE 2. Age Profile of P[ADLs = 1], Observed and Simulated
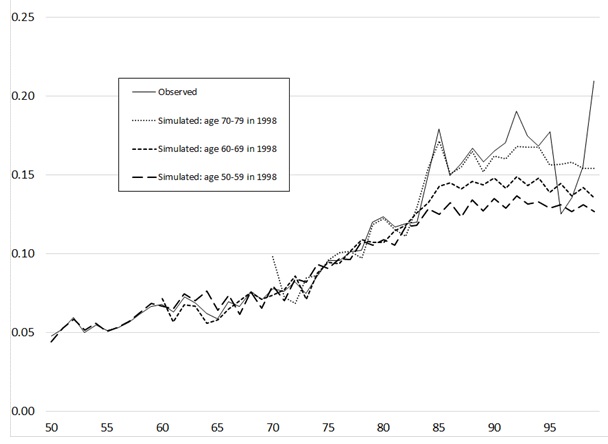
The same results are also shown, in more aggregated form, in Table 1. The data are grouped into ten-year cohorts and summary indicators (here, for "any disability," combining the 1 ADL and the 2+ ADL categories) are shown for selected points in the life cycle. The ages shown (55, 65, 75, and so on) are attained in different years for members of each cohort. For example, some of those aged 50-59 in 1998 are 55 in 1998, some are 55 in 1999, some in 2000, and so on. The years shown in brackets in Table 1 are, roughly, the average year in which the respective cohort passes through the indicated age. Consistent with what is shown in Figure 2 and Figure 3, the prevalence of disability is actually slightly higher through age 85 than what is observed directly in the HRS; it is only after age 85 that disability prevalence is projected to fall.
FIGURE 3. Age Profile of P[ADLs = 2+], Observed and Simulated
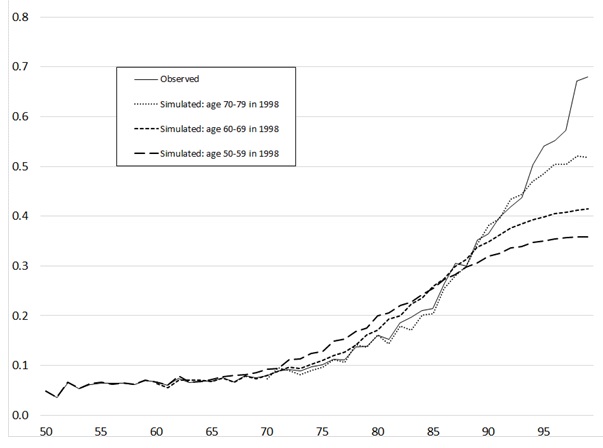
While these projected changes for the oldest-old may appear implausibly large, further reflection suggests that they are in line with at least some recent trends. We can determine the average annual change in prevalence needed to bring about these projected changes by solving for r in the formula Prev2 = Prev1(1 + r)t, where Prev1 and Prev2 are the baseline and out-year prevalence figures, t is the number of years in the interval, and r is the annual rate of change. Using the simulated numbers shown in Table 1, we discover that the implied average annual rate of change in disability prevalence is between -0.005 and -0.01 (i.e., from 0.5% to 1% decline) for the three cohorts shown. To put these numbers in context, note that Freedman et al. (2004) concluded that available evidence from a number of different national-level surveys supports a conclusion that the prevalence of having ADL difficulties showed declines in the 1%-2.5% range during the mid-1990s to late-1990s. The projected annual rates of change implied by my simulated ADL profiles is at or below this range. In a later paper that updated the 2004 findings, Freedman et al. (2103) noted that the percentage of the older population with activity limitations remained flat during the 2000-2010 decade. Yet the latter paper also found evidence of continuing declines in ADL limitations for the oldest-old groups. The projections presented here, therefore, are consistent with a continuation of the trends documented in past empirical studies.
TABLE 1. Prevalence of Any Disability, by Age and Cohort: Observeda and Simulated
| Baseline Age Group [1998] | Prevalence at Age [in year] ... | ||||
|---|---|---|---|---|---|
| 55 | 65 | 75 | 85 | 95 | |
| 50-59 | 0.116 [2000] | 0.135 [2010] | 0.219 [2020] | 0.380 [2030] | 0.479 [2040] |
| 60-69 | 0.125 [2000] | 0.205 [2010] | 0.402 [2020] | 0.537 [2030] | |
| 70-79 | 0.193 [2000] | 0.375 [2010] | 0.641 [2020] | ||
| 90-99 | 0.702 [2000] | ||||
| |||||
Understanding the Cohort Effects
The intercohort differences depicted in Figure 2 and Figure 3 are not based on an explicit model of disability dynamics, but rather reflect hypothetical age profiles produced through the application of a data-matching process. For intercohort change to emerge, it must be the case that there are between-cohort differences in the distribution of ADL severity. To see that this is in fact the case, I show two sorts of evidence.
First, Table 1 shows the differing futures of individuals at each level of the disability matching criterion, with respect to the proportion with 1 ADL (top panel of Table 1) and the proportion with 2+ ADLs (bottom panel of Table 1). This table averages over all ages in the sample. For example, someone coded "00" on the match criterion (i.e., with no ADLs in two successive waves) has a very low chance--ranging from 0.05 to 0.06--of having either level of ADL difficulties one, two, three, four, or five waves later. At the other end of the severity distribution, someone coded "22" (i.e., with 2+ ADLs in two successive waves of data) or "21" has rather high (but declining) chances of having 2+ ADLs one, two, three and even four waves later. These merely confirm the well-known persistence of severe disability levels over time.
Table 2 provides information that helps explain the intercohort differences shown in Figure 2 and Figure 3. Table 2 allows us to compare the prevalence of each level of the disability match criterion between donor groups and target groups, at comparable ages. For example, those in the age 60-69 donor group were 60-69 in 1998, while those in the 60-69 target group were age 50-59 in 1998, and 60-69 in 2008. Table 2 shows that in many instances the target groups exhibited higher prevalence rates for low-risk disability match criteria, and (at least for the oldest age groups) higher rates of low-risk disability match criteria. For example, match criterion value "21" (shown in Table 1 to predict high rates of subsequent levels of 2+ ADLs) is less prevalent in all ages of the target group than in the donor group. In contrast, match criterion value "00"--strongly predictive of low levels of later disability--is noticeably more prevalent in the target sample for ages 80-89 and 90-99 than in the donor group. The differences at ages 80 and above seem particularly relevant in view of the end-of-life divergence in disability prevalence shown in Figure 2 and Figure 3.
TABLE 2. Prevalence of ADL Disabilities in Future Waves, Conditional on Match Criterion
| Match Criterion | Pr[ADLt = 1 | match criterion] | ||||
|---|---|---|---|---|---|
| t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | |
| 00 | 0.05 | 0.05 | 0.06 | 0.06 | 0.05 |
| 01 | 0.19 | 0.15 | 0.14 | 0.09 | 0.08 |
| 02 | 0.16 | 0.10 | 0.08 | 0.08 | 0.09 |
| 10 | 0.18 | 0.17 | 0.15 | 0.11 | 0.07 |
| 11 | 0.25 | 0.19 | 0.17 | 0.14 | 0.11 |
| 12 | 0.14 | 0.12 | 0.12 | 0.08 | 0.04 |
| 20 | 0.18 | 0.14 | 0.11 | 0.14 | 0.12 |
| 21 | 0.23 | 0.16 | 0.14 | 0.12 | 0.07 |
| 22 | 0.10 | 0.07 | 0.05 | 0.05 | 0.03 |
| Match Criterion | Pr[ADLt = 2+ | match criterion] | ||||
|---|---|---|---|---|---|
| t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | |
| 00 | 0.03 | 0.04 | 0.05 | 0.05 | 0.06 |
| 01 | 0.15 | 0.16 | 0.16 | 0.16 | 0.14 |
| 02 | 0.35 | 0.28 | 0.21 | 0.16 | 0.13 |
| 10 | 0.11 | 0.14 | 0.13 | 0.14 | 0.14 |
| 11 | 0.26 | 0.20 | 0.19 | 0.16 | 0.15 |
| 12 | 0.43 | 0.34 | 0.23 | 0.22 | 0.18 |
| 20 | 0.22 | 0.20 | 0.17 | 0.15 | 0.16 |
| 21 | 0.35 | 0.37 | 0.30 | 0.24 | 0.26 |
| 22 | 0.53 | 0.36 | 0.28 | 0.20 | 0.17 |
Uncertainty Associated with the Matching Process
As noted before, the results shown in Figure 2 and Figure 3 are averages over five independent "runs" of the matching algorithm. The age-specific prevalence figures plotted in the figures are averages across the five runs. Each age-specific prevalence has a standard error, one that reflects both the sampling variability present in the HRS data and the between-run variability associated with the independent random-matching process. Standard multiple imputation tools can be used to compute these standard errors (SEs) and to show the degree to which the random-matching process inflates these SEs. Figure 4 plots the "percentage increase in SEs due to imputation" for each of the age-specific disability prevalence measures shown above. As in any forecasting or projection exercise, we would expect the precision of estimates to decline as we move farther and farther outside the observed range of data. Figure 4 shows that this is true here as well: Figure 4 pertains only to the cohort originally aged 50-59, and thus represents the longest projection period used here. Note also that there is no imputation variance until age 64, because that is the youngest age for which simulated values are assigned in this cohort. Although the year-to-year pattern of imputation variance is quite erratic in Figure 4, there is a clear upward trend from age 64 through age 99.
FIGURE 4. Percentage Increase in Standard Error of Pr[ADLs = ...] Due to Imputation
![FIGURE 4, Line Chart: This graph shows 2 lines; the solid line represents the “percentage increase in standard error of P[ADLs = 1] for ages 64-99, for the cohort of people age 50-59 in 1998. SEs reflect a combination of sampling variability and multiple-imputation variability, the latter produced by the random matching/prediction algorithm used in these simulations. The dashed line represents the corresponding series for P[ADLs = 2+]. Each series shows a few spikes (e.g., for the ADLs = 1 series there are spikes at ages 73, 87, and 91; for the ADLs = 2+ series there is a spike at age 77). Otherwise, for ages 64-75 the percentage increase in SEs is generally below 50, while for ages 76 onward it is usually between 50 and 100.](/sites/default/files/private/images-reports-basic/108401/traject-fig4.JPG)
This study is of both substantive and methodological interest. From a methodological standpoint, it demonstrates the feasibility of applying file-matching techniques to a sample of partial trajectories--that is, "excerpts" from individuals' lifetime experience of disability--to create synthetic "unabridged" lifetime profiles. The approach used here could be applied in a backwards direction as well as the forwards direction illustrated here: for example, the otherwise-unobserved experience from ages 50-79 of someone age 80 in 1998 could be imputed using exactly the same record-linkage tools used here.
The matching algorithm is, in effect, based on a "distance" metric, but one in which the distance between donor and target with respect to disability and gender is zero. The distance between donor and target with respect to age may be as much as three years, but no differentiation of match quality with respect to distance in the age dimension is recognized here. As noted above, the matching algorithm could be modified to incorporate this refinement. My use of a fully discrete set of match criteria allows me to make use of SAS's stratified random sampling procedure, so that I can select a complete set of donor records to be matched to the target records using a single call to PROC SURVEYSELECT. This surely speeds up the matching program, in comparison to listwise processing, but I have made no attempt to quantify this gain in efficiency.
The creation of synthetic data through exact or probabilistic matching is, of course, not at all new. However, I am aware of only one prior application of the stringing together of sequences of longitudinal data into a more complete lifetime profile, and that is the "splicing" approach taken in the Model of Income in the Near Term (MINT), described in Toder et al. (2002). MINT extends partial histories of earnings, disability insurance (DI) status, and mortality of younger people observed in Survey of Income and Program Participation (SIPP) data through matching with longer histories available for older people also found in the SIPP data. MINT's splicing uses a hot-deck matching method, but the cited report does not state how close two records must be (i.e., the distance requirement) for them to be considered adequate for purpose of matching. The other procedural differences between MINT's approach and mine is MINT's use of listwise processing (which I infer from the fact that hot-deck matching is employed) and the use of only a single rather than multiple matching to reflect imputation uncertainty.
The synthetic-lifetime disability profiles produced by matching imply a substantial reduction in the prevalence of ADL disabilities among the oldest-old through about 2040. While rather striking, these reductions turn out to be consistent with a continuation (and even some dampening) of trends found in survey data collected during the 1990s and early 2000s. The projected disability prevalence figures nevertheless appear to be quite different from those produced by current model-based microsimulation programs. Comparisons are not straightforward due to the cohort perspective adopted here, with observed data pooled over a number of years, while the alternative microsimulations typically adopt and age + period orientation in their presentation of results. For example, using figures shown in Figure 1 of Johnson et al. (2007), the Dynasim3 projections show a prevalence of "any disability" (which includes any IADLs as well as any ADLs) of 28.1% in 2010, 25.6% in 2020, 26.5% in 2030, and 28.1% in 2040. In other words, late-life disability prevalence is projected to fall slightly to 2020 and then rise slightly to 2040. This projection is roughly consistent with the "baseline" projection results found in Sullivan et al. (2013), in which "any disability" includes those in nursing homes as well as community-dwelling individuals with any IADLs or any ADLs. The baseline FEM projection indicates that the percentage disabled among the 65-plus population is about 28% in 2010, 21% in 2020, 18% in 2030, 20% in 2040 and 22% in 2050.5 Like the Dynasim3 projections, this shows a period of gradual decline in late-life disability prevalence, followed by a small increase in prevalence; the difference between the two series is mainly in the timing of the reversal in trend. Thus the results of my matching approach challenge the findings produced using considerably more complicated models and methods, at least for the few comparisons that are possible. It is worth noting that the "trends" suggested by my approach can only come from intercohort differences, and that both the FEM model and Dynasim3 appear to neglect cohort differences--at least, "cohort" is not used as a regressor, and between-cohort differences are recognized only indirectly, insofar as different cohorts might turn out to have different distributions of the explanatory variables that do appear in the respective models.
There are many ways in which the matching approach taken here could be extended and, one must assume, be improved. For purposes of long-term care policy analysis, the three-level ADL variable used as an outcome is far too simplistic. It overlooks not only IADL difficulties, but also cognition problems, the latter of which generally are included for purposes of establishing eligibility for programmatic benefits.
The conditional independence assumption that plagues all forms of probabilistic record matching could also be addressed. By requiring an exact match on the ADL variable for two successive waves, this matching method relaxes the first-order Markov assumption adopted in much of the disability dynamics literature. But serial dependence of disability measures undoubtedly extends over more than two successive waves of panel data. A three-wave or even a four-wave exact match criterion could be imposed, but this would greatly expand the number of cells in the stratification table, and would surely lead to a situation in which there are no available "donor" records to go with many of the cells of the "target" sample.
An acknowledged limitation of the approach used here is its strong reliance on data from observed cohorts only. Accordingly, the youngest cohort that can be tracked consists of those aged 50-59 in 1998; this group, however, is 90 and older in 2038. Period-to-period comparisons of broader groups (e.g., 65 and above in future years) are therefore ruled out. It also seems likely that the type of matching employed here is practical only for use with a small number of outcome dimensions (i.e., matching can only be done for one or a small number of traits at a time). The "splicing" method used in MINT tackles only three dimensions, and one (death) is an absorbing state while another (DI status) is highly stable (once someone goes on DI they almost never go off). Nevertheless, matching along a key outcome dimension can be used--as it has been used here--to develop a relatively model-free set of projections that can be compared to the more intensively model-based approaches more commonly used in microsimulation, as a sort of consistency or sensitivity test of the more usual approach.
Finally, as Ridder and Moffitt (2007) point out, thanks to the conditional independence assumption the joint distribution of the "X," "Y," and "Z" vectors (as defined before) is not identified, which severely limits the inferences that can legitimately be drawn from matched data. What this means is that the synthetic profiles produced here should not, for example, be used as input data for a growth curve model. However, summary statistics based on marginal distributions (e.g., age-specific means, of the sort shown in Table 1, Figure 2 and Figure 3) do not depend on the joint distribution, and are therefore more strongly justified.
Baldini, Massimo, Carlo Mazzaferro, and Marcello Morciano, 2007. "Assessing the implications of long term care policies in italy: A microsimulation approach." Società Italiana di Economia Pubblica. Online at https://www.researchgate.net/publication/46459341 (accessed August 6, 2014).
Chiu, Ching-Ju, and Linda A. Wray, 2010. "Physical disability trajectories in older Americans with and without diabetes: The role of age, gender, race or ethnicity, and education." The Gerontologist, 51, 51-63.
Dodge, Hiroko H., Yangchun Du, Judith A. Saxton, and Mary Ganguli, 2016. "Cognitive domains and trajectories of functional independence in nondemented elderly persons." Journals of Gerontology: Medical Sciences, 61A, 1330-1337.
Ferraro, Kenneth F., Melissa M. Farmer, and John A. Wybraniec, 1997."Health trajectories: Long-term dynamics among black and white adults." Journal of Health and Social Behavior, 38, 38-54.
Fernández, José-Luis, and Julien Forder, 2010. "Equity, efficiency, and financial risk of alternative arrangements for funding long-term care systems in an ageing society." Oxford Review of Economic Policy, 26, 713-733.
Fukawa, Tetsuo, 2011. "Household projection and its application to health/long-term care expenditures in Japan using INAHSIM-II." Social Science Computer Review, 29, 52-66.
Freedman, V.F., E. Crimmins, R.F. Schoeni, B.C. Spillman, H. Aykan, E. Kramarow, K. Land, J. Lubitz, K. Manton, L.G. Martin, D. Shinberg, and T. Waidman, 2004. "Resolving inconsistencies in trends in old-age disability: Report from a technical working group." Demography 41:417-41.
Freedman V.A., B.C. Spillman, P.M. Andreski, J.C. Cornman, E.M. Crimmins, E. Kramarow, J. Lubitz, L.G. Martin, S.S. Merkin, R.F. Schoeni, T.E. Seeman, and T.A. Waidmann, 2013. "Trends in late-life activity limitations in the United States: An update from five national surveys." Demography, 50(2), 661-71.
Goel, Prem K., and T. Ramalingam, 1989. The Matching Methodology: Some Statistical Properties. New York, NY: Springer-Verlag.
Gupta, Anil, and Vishnu Kapur (eds.), 2000. Microsimulation in Government Policy and Forecasting. Elsevier.
Hancock, Ruth, Adelina Comas-Herrera, Raphael Wittenberg, and Linda Pickard, 2003. "Who will pay for long-term care in the UK? Projections linking macro- and micro-simulation models." Fiscal Studies, 24, 387-426.
Johnson, Richard, Desmond Tooley, and Joshua M. Wiener, 2007. "Meeting the long-term care needs of the Baby Boomers: How changing families will affect paid helpers and institutions." Retirement Project Discussion Paper #07-04. Washington, DC: The Urban Institute. Online at http://www.urban.org/UploadedPDF/311451_Meeting_Care.pdf (accessed July 11, 2014).
Kennell, David L., Lisa Maria B. Alecxih, Joshua M. Wiener, and Raymond J. Hanley, 1992. Brookings/ICF Long-Term Care Financing Model: Model Assumptions. Washington, DC: U.S. Department of Health and Human Services. Online at http://aspe.hhs.gov/daltcp/reports/modampes.htm (accessed August 8, 2014).
Liang, Jersey, Xiao Xu, Joan M. Bennett, Wen Ye, and Ana R. Quiñones, 2009. "Ethnicity and changing functional health in middle and late life: A person-centered approach." Journal of Gerontology: Social Sciences, 65B, 470-481.
Orcutt, Guy, Stephen Caldwell, Richard Wertheimer III, Steven Franklin, Gary Hendricks, Gerald Peabody, James Smith, and Sheila Zedlewski, 1976. Policy Exploration Through Microanalytic Simulation. Washington, DC: The Urban Institute.
Raghunathan, T.E. (2004). "What do we do with missing data? Some options for analysis of incomplete data." Annual Review of Public Health, 25, 99-117.
Ridder, Geert, and Robert Moffitt, 2007. "The econometrics of data combination." Handbook of Econometrics, Volume 6B, 5469-5547. Elsevier B.V.
Rivlin, Alice M., and Joshua M. Wiener, 1988. Caring for the Disabled Elderly: Who Will Pay? Washington, DC: The Brookings Institution.
Rohlfsen, Leah S., and Jennie Jacobs Kronenfeld, 2014. "Gender differences in functional health: Latent curve analysis assessing differential exposure." Journals of Gerontology, Series B: Psychological Sciences and Social Sciences, 69, 590-602.
Rubin, Donald B., 1986. "Statistical matching using file concatenation with adjusted weights and multiple imputations." Journal of Business and Economic Statistics, 4, 87-94.
Sullivan, Jeffrey, Pierre-Carl Michaud, Desi Peneva, and Dana P. Goldman, 2013. Details of the Future Elderly Model: Online Supplement. Online at http://content.healthaffairs.org/content/suppl/2013/09/30/32.10.1698.DC1/2013-0052_Goldman_Appendix.pdf (accessed July 11, 2014).
Toder, Eric, Lawrence Thompson, Melissa Favreault, Richard Johnson, Kevin Perese, Caroline Ratcliffe, Karen Smith, Cori Uccello, Timothy Waidmann, Jillian Berk, Romina Woldemariam, Gary Burtless, Claudia Sahm, and Douglas Wolf, 2002. Modeling Income in the Near Term: Revised Projections of Retirement Income Through 2020 for the 1931-1960 Cohorts. Washington, DC: The Urban Institute. Online at http://www.urban.org/retirement_policy/url.cfm?ID=410609 (accessed August 14, 2014).
Verbrugge, Lois M., and Alan M. Jette, 1994. "The disablement process." Social Science and Medicine, 38, 1-14.
Wickrama, K.A.S., Jay A. Mancini, Kyunghwa Kwag, and Josephine Kwon, 2013."Heterogeneity in multidimensional health trajectories of late old years and socioeconomic stratification: A latent trajectory class analysis." Journal of Gerontology Series B: Psychological Sciences and Social Sciences, 68, 290-297.
Wolf, Douglas A., and Thomas M. Gill, 2009. "Modeling transition rates using panel current-status data: How serious is the bias?" Demography, 46, 371-386.
APPENDIX 1: SCHEMATIC REPRESENTATION OF MATCHING ALGORITHM
(2) Code disability matching criterion for donors
(3) Define current population = initial population
(4) Begin matching cycle (with "increment" = 0 waves [to control number of cycles])
(4.1) Set wave to use for matching = w* = 9 + increment
(4.2) Define matching age = age in wave w*
(4.3) Define "target" subsample of current population:
(4.4) Define "nontarget" subsample of current population
(4.5) Define "donor" subsample appropriate to current poplation; (re)define ADL(w*) = ADL(4); ADL(w* + 1) = ADL(5); ...
(4.6) Randomly sample (with replacement) from donor subsample, with sample counts given by stratification table; randomly reorder donor sample within sampling strata
(4.7) Merge target subsample with random sample from donor subsample
(4.8) (Re)define current population as concatenation of nontarget subsample with merged sample
(4.9) Add 5 to increment [i.e., sequence of w* is 9, 14, 19, 24, ...]
(4.10) If w* = 29 go to end; otherwise go to (4)
(5) End
-
The number of cells in the stratification table shrinks in each successive match cycle, as successive cycles cover progressively narrow age ranges.
-
Cell sizes greater than 25 (in the target pool) are not shown--there are 58 such cells--because the range of cell sizes becomes quite large, reaching a maximum of 268. For all target pool cell sizes greater than 25, the corresponding target pool cell sizes are much larger.
-
The prevalence figures for FEM are only approximate, because they are read from a graph (Exhibit S2 of Sullivan et al. 2013) rather than transcribed from a table.
This report was prepared under contract #HHSP23337029T between the U.S. Department of Health and Human Services (HHS), Office of Disability, Aging and Long-Term Care Policy (DALTCP) and the Urban Institute. For additional information about this subject, you can visit the DALTCP home page or contact the ASPE Project Officers, John Drabek and Hakan Aykan, at HHS/ASPE/DALTCP, Room 424E, H.H. Humphrey Building, 200 Independence Avenue, S.W., Washington, D.C. 20201. E-mail: John.Drabek@hhs.gov.