
U.S. Department of Health and Human Services
Prescription Drug Spending by Medicare Beneficiaries in Institutional and Residential Settings, 1998-2001
Linda Simoni-Wastila, PhD, Bruce Stuart, PhD, and Thomas Shaffer, MS
University of Maryland, Baltimore, Peter Lamy Center on Drug Therapy and Aging
June 2007
PDF Version (62 PDF pages)
This report was prepared under contract #HHS-100-03-0025 between the U.S. Department of Health and Human Services (HHS), Office of Disability, Aging and Long-Term Care Policy (DALTCP) and the University of Maryland. For additional information about this subject, you can visit the DALTCP home page at http://aspe.hhs.gov/_/office_specific/daltcp.cfm or contact the office at HHS/ASPE/DALTCP, Room 424E, H.H. Humphrey Building, 200 Independence Avenue, S.W., Washington, D.C. 20201. The e-mail address is: webmaster.DALTCP@HHS.GOV. The Project Officer was Linda Bergofsky.
The opinions expressed herein are solely those of the authors and do not reflect the position or policy of any office of the Assistant Secretary for Planning and Evaluation at the U.S. Department of Health and Human Services or any other government authority.
TABLE OF CONTENTS
- I. INTRODUCTION
- III. MAJOR FINDINGS
- POLICY BRIEF 1: National Estimates of Prescription Drug Utilization and Expenditures in Long-Term Care Facilities
- POLICY BRIEF 2: A National Comparison of Prescription Drug Expenditures by Medicare Beneficiaries Living in the Community and Long-Term Care Facility Settings
- POLICY BRIEF 3: Drug Use and Spending for Medicare Beneficiaries During Part A Qualifying Skilled Nursing Facility Stays and Non-Qualifying Long-Term Care Facility Stays
- ATTACHMENT: PRICING ALGORITHM REVIEW
- LIST OF FIGURES
- FIGURE 1: Comparison of Prescription Drug Utilization and Expenditures in Community and LTCF Medicare Beneficiaries, 2001
- FIGURE 2: Total Prescription Drug Spending by Medicare Beneficiaries by Prescription Coverage Source
- LIST OF TABLES
- TABLE 1: Stability of Individual Residence by Facility Type, 1998-2001
- TABLE 2: Actual and Projected Prescription Drug Expenditures, 1998-2005
- TABLE 3: Medication Utilization and Expenditures for Medicare Beneficiaries with SNF and Other LTCF Stays, 2001
EXECUTIVE SUMMARY
Although much attention has been paid to the potential implications of the Medicare Prescription Drug, Improvement, and Modernization Act of 2005 (MMA) on prescription drug utilization and expenditures for community-dwelling beneficiaries, less attention has been paid to how Part D will affect the nearly 2.7 million Medicare beneficiaries residing in nursing homes and other long-term care facilities (LTCFs). Indeed, little is known about prescription drug utilization patterns in long-term care patients -- especially individuals residing in assisted living facilities (ALFs). This study was funded by the Office of the Assistant Secretary of Planning and Evaluation in the Department of Health and Human Services. It was motivated by the need for further information on medication use and spending in LTCFs in order to provide insight into the implications of the MMA for beneficiaries residing in institutions. As well, the programming and statistical processes required to generate these estimates provide a firm foundation for further work in medication utilization and expenditures studies by developing, for the first time, a database with medication prices that will allow pertinent policy analyses.
The study has three specific aims:
- To prepare nationally-representative estimates of drug spending in LTCFs by year (1998-2001), facility type, and other relevant factors associated with recipient characteristics and types of drugs used.
- To compare drug use and spending for beneficiaries in LTCFs to those faced by beneficiaries living in communities.
- To examine medication use and spending by short-stay skilled nursing facility residents who transition into LTCFs.
For each of these aims, project investigators at the Peter Lamy Center on Drug Therapy and Aging at the University of Maryland Baltimore (UMB) School of Pharmacy produced a Policy Brief. These are titled:
-
National Estimates of Prescription Drug Utilization and Expenditures in Long-Term Care Facilities [http://aspe.hhs.gov/daltcp/reports/2006/pdnatest.htm].
-
A National Comparison of Prescription Drug Expenditures by Medicare Beneficiaries Living in the Community and Long-Term Care Facility Settings [http://aspe.hhs.gov/daltcp/reports/2007/pdnatcom.htm].
-
Drug Use and Spending for Medicare Beneficiaries During Part A Qualifying Skilled Nursing Facility Stays and Non-Qualifying Long-Term Care Facility Stays [http://aspe.hhs.gov/daltcp/reports/2007/druguse.htm].
Data and Methods
This study employed the 1998-2001 Medicare Current Beneficiary Survey (MCBS) Cost and Use files. Prescription drug information was obtained from data extracted from the Medication Administration Records on prescription drug use in LTCFs and collected by MCBS surveyors. This file, known as the Institutional Drug Administration, is collected at the time of the general MCBS survey and then prepared as an analytic file by the University of Maryland under contract to the Centers for Medicare and Medicaid Services (CMS). This file is not part of the general MCBS survey at this time. More information on the MCBS is available online at: http://www.cms.hhs.gov/MCBS/.
A fundamental component of this study was the application of an already existing programming algorithm to estimate prescription drug expenditures in LTCFs using the MCBS data.1 This algorithm created and used by CMS was originally implemented to estimate prescription drug expenditures by Medicare beneficiaries residing in the community. Information generated by the application of the algorithm provided CMS with useful information needed for its own resources and is used by the Office of the Actuary in projecting prescription drug spending by the Medicare population.
We operationalized key medication utilization and expenditures measures. Because there are substantial differences in the mechanisms of how drug administration data are collected for community compared to institutionalized Medicare beneficairies, our measures are limited to per year and per user per year measures when comparing across residential environments. All analyses, except where otherwise noted, utilize the weights provided in the MCBS to provide national estimates of drug utilization and expenditures. All analyses were conducted using SAS Version 9.
Key Findings
-
In 2001, more than 41 million Medicare beneficiaries spent more than $55 billion on prescription drugs. Of this amount, 9.9%, or $5.4 billion, was accounted for by the 2.7 million Medicare beneficiaries living in LTCFs.
-
Mean annual prescription drug expenditure by user is markedly higher in LTCF resident than in their community-dwelling peers ($2,077 per user versus $1,571 per user, respectively).
-
In the LTCF population, Medicaid is the dominant payor of prescription drugs. The under age 65 Social Security Disability Insurance (SSDI) Medicare population is growing as a proportion of Medicare beneficiaries and also constitute a driving force behind the number and types of prescription medication expenditures. In 2001 Medicare SSDI beneficiaries spent, on average, $828 more on prescription drugs than did their counterparts qualifying for Medicare on the basis of age.
-
Psychotherapeutic drugs were the most frequently prescribed and most expensive therapeutic drug class used by LTCF beneficiaries. Much of this use was driven by disabled individuals who were dually eligible for Medicare and Medicaid.
-
Mean annual growth in prescription drug spending across all LTCFs was 11.9% over the three year period, with the greatest growth noted in ALFs.
-
Total prescription drug expenditures in LTCFs are estimated to range from $7.8-$10.5 billion in 2005.
-
Total prescription spending for the Top 10 therapeutic classes in the United States accounted for $39.9 billion, or 72.8% of total prescription drug spending. Although the Top 10 classes varied by community versus institutional populations, the proportion of total spending is equivalent.
-
On average, SSDI-eligible individuals in the community used $2,444 worth of prescription drugs, compared to per user spending of $2,775 by SSDI-eligibles residing in facilities, a mean difference of $331 per year. Within LTCFs, there were higher per user payments for SSDI beneficiaries than their aged counterparts ($2,775 versus $1,962); in the community, SSDI-eligibles also spent on average nearly $1,000 more than their aged counterparts ($2,444 versus $1,418).
Conclusion
This project provides the first detailed and national estimates of prescription drug utilization and expenditures by Medicare beneficiaries residing in LTCFs. These estimates are useful and needed benchmarks for monitoring medication use and spending patterns, especially as the MMAs prescription drug expansion enters its second year. Future work should focus on using more current data, including up to and past January 2006, and should employ multivariable methods to control for important covariates explaining variation in medication use and spending patterns.
I. INTRODUCTION
Although much attention has been paid to the potential implications of the Medicare Prescription Drug, Improvement, and Modernization Act of 2005 (MMA) on medication utilization and expenditures for community-dwelling beneficiaries, less attention has been paid to how Part D will affect the nearly 2.7 million Medicare beneficiaries residing in nursing homes (NHs) and other long-term care facilities (LTCFs). Indeed, little is known about prescription drug utilization patterns in long-term care patients -- especially individuals residing in assisted living facilities (ALFs). This study, sponsored by the Office of the Assistant Secretary for Planning and Evaluation (ASPE) under the Department of Health and Human Services (HHS), was motivated by the need for further information on medication use and spending in LTCFs in order to provide insight into the implications of the MMA for beneficiaries residing in institutions. As well, the programming and statistical processes required to generate these estimates provide a firm foundation for further work in medication utilization and expenditures studies by developing, for the first time, a database with medication prices that will allow pertinent policy analyses.
This project is important for a number of reasons. For one, it helped to build the first detailed national-level dataset on drug utilization and spending for Medicare beneficiaries in various LTC settings. Second, most studies of long-term care have excluded younger disabled persons who may be Medicare entitled. We address this unique and vulnerable population, comparing medication use and spending to their older counterparts residing in LTCFs. Third, no studies have compared drug prices in institutional and community settings. The conventional wisdom is that institutional pharmaceutical services are more expensive given the complex medication needs of the long-term care population and the strict regulatory environment in which NHs operate. We demonstrate that spending per person in institutions is significantly greater than per person spending by community-dwelling Medicare beneficiaries. Fourth, we examine differences in medication uses and spending by facility type: NHs, ALFs, and other institutions ranging from groups homes to psychiatric institutions. As well, we examine drug use and spending by beneficiaries in Medicare-qualified Part A skilled nursing facility (SNF) stays who transition into longer term nursing facilities.
The study has three specific aims:
- To prepare nationally-representative estimates of drug spending in LTCFs by year (1998-2001), facility type, and other relevant factors associated with recipient characteristics and types of drugs used.
- To compare drug use and spending for beneficiaries in LTCFs to those faced by beneficiaries living in communities.
- To examine medication use and spending by short-stay SNF residents who transition into LTCFs.
For each of these aims, project investigators at the Peter Lamy Center on Drug Therapy and Aging at the University of Maryland Baltimore (UMB) School of Pharmacy produced a Policy Brief. These are titled:
-
National Estimates of Prescription Drug Utilization and Expenditures in Long-Term Care Facilities [http://aspe.hhs.gov/daltcp/reports/2006/pdnatest.htm].
-
A National Comparison of Prescription Drug Expenditures by Medicare Beneficiaries Living in the Community and Long-Term Care Facility Settings [http://aspe.hhs.gov/daltcp/reports/2007/pdnatcom.htm].
-
Drug Use and Spending for Medicare Beneficiaries During Part A Qualifying Skilled Nursing Facility Stays and Non-Qualifying Long-Term Care Facility Stays [http://aspe.hhs.gov/daltcp/reports/2007/druguse.htm].
This Final Report describes the processes and methods used to achieve these aims, an overview of their findings, and implications of our findings for the Centers for Medicare and Medicaid Services (CMS), Medicare beneficiaries, long-term care providers, and taxpayers. Finally, we conclude with observations about future research steps and identification of priorities that can help support the Department in its implementation and evaluation of the Part D drug benefit. The Final Report is structured as follows:
- Executive Summary that presents an overview of the study, major findings, and a brief discussion of the implications for the MMA;
- Introduction that describes the importance and policy-relevance of understanding medication utilization and expenditures in LTCFs;
- Description of the data and methodology;
- Major findings;
- Policy implications, conclusions and directions for future research; and
- Technical attachment.
In addition to this report the UMB investigators will present findings and discuss their implications for public policy to ASPE and other HHS leadership. The presentation will review the studys data, methods, and findings, and will focus on the key findings that are particularly relevant to the implementation of the MMA.
The investigators are working with ASPE to disseminate project findings to a variety of audiences. In conjunction with ASPE, we will develop a dissemination plan that will include the target audiences for reports and appropriate venues for the dissemination of results such as hard copy distribution via mailing lists, availability at ASPE, the UMB, and other web sites, presentations at policy seminars, briefings, and professional meetings, and peer-reviewed journals.
II. DESCRIPTION OF DATA AND METHODS
Data
A fundamental component of this study was the application of an already existing programming algorithm to estimate prescription drug expenditures in LTCFs using the Medicare Current Beneficiary Survey (MCBS) data. This algorithm created and used by CMS was originally implemented to estimate prescription drug expenditures by Medicare beneficiaries residing in the community. Information generated by the application of the algorithm provided CMS with useful information needed for its own resources and is used by the Office of the Actuary in projecting prescription drug spending by the Medicare population. The data and algorithm are briefly described here; detailed information can be found in Policy Brief 1.2
This analysis built upon data from the 1998-2001 MCBS Cost and Use files. Prescription drug information was obtained from data extracted from the Medication Administration Records on prescription drug use in LTCFs and collected by MCBS surveyors. This file, known as the Institutional Drug Administration (IDA), is collected at the time of the general MCBS survey and then prepared as an analytic file by the University of Maryland under contract to CMS. This file is not part of the general MCBS survey at this time. More information on the MCBS is available online at: http://www.cms.hhs.gov/MCBS/.
A key feature of this particular study was the assignment of a price to each prescription drug record in the IDA files for the four study years Pricing of drug data is usually based on the 9-11 digit National Drug Code which uniquely identifies important characteristics of the drug (e.g., strength, form, brand or generic status, and manufacturer) that allows it to be individually priced. The MCBS survey, however, does not collect this unique identifier for IDA records; rather, only drug name, dosage form, strength, and several other drug attributes are collected. Pricing of drugs for surveyed persons in long-term care settings was accomplished by applying the same algorithm used by CMS to price drugs for people in the community. The algorithm takes into account such factors as dosage form and strength (amongst other things) to produce a base price. Once a base price is produced, it is further adjusted to reflect payor discounts and dispensing fees.
Drug Use Measures
Measures of prescription drug utilization include: (1) the proportion of beneficiaries having at least one prescription medication event (PME) (community) or medication administration (LTC) facility; (2) medication administrations per person-month (LTCFs); and (3) total expenditures and expenditures per user per year (both community and LTCFs).
Prescription drug use and spending are examined in aggregate, as well as by therapeutic category. All use and spending measures are weighted to provide national estimates. All expenditures are presented in current dollars in the year analyzed. For all analyses of therapeutic class, we examined the Top 10 most commonly used or most expensive categories according to use and spending in the community. Thus, spending in LTCFs is benchmarked to that of the community.
It is important to note estimates reported here only include prescription drugs; the pricing algorithm specifically excludes the pricing of over the counter (OTC) drugs and they have been omitted from analyses Although OTC medications represent a significant component of medication utilization in LTCFs, accounting for almost a third of all administrations, they are comparatively inexpensive due to their OTC status.3
Due to fundamental differences in the way drug data are collected at the community and facility levels, comparisons of prescription drug utilization and expenditures are limited in several important ways:
-
Although the utilization of prescription drugs in institutional settings is recorded at the monthly level, drug use in the community is collected as total annual events, thereby requiring any utilization estimates to be computed at the annual level (rather than at the monthly level).
-
There are differences in the way dosage forms and strengths are recorded at the community and institutional levels. Further, these fields required considerable clean up for the institutional pricing and community analyses; thus, this information is not utilized optimally by the CMS pricing algorithms.
-
Because the CMS pricing algorithm uses drug names as collected in the PME files, differences in institutional-based drugs, as well as dosage forms and strengths not typically utilized in the community, may result in non-matching of prices for medications used in institutional settings.
Medicare Eligibility and Coverage
We consider prescription drug utilization and expenditures in the context of three primary factors: therapeutic category, Medicare eligibility, and source of prescription drug coverage. For this analysis, we considered all individuals who qualify as Social Security Disability Insurance (SSDI)-eligible (i.e., less than 65 years of age) to be Medicare-eligible on the basis of disability and all individuals aged 65 and older to be Medicare-eligible on the basis of age.
Prescription drug coverage reflects the source of coverage for the individual during the year as determined by the MCBS, which tracks coverage on a month-by-month basis. Prescription coverage is described as being through Medicaid, Other Sources, unknown prescription coverage, or evidence of no coverage. Medicaid prescription drug coverage includes Medicaid-enrolled beneficiaries, in addition to Qualified Medicare Beneficiaries (QMB)/Special Low Income Beneficiaries who come from QMB-Plus states. QMB-Plus states allow qualified individuals to receive both medical care as well as prescription drug benefits. Other sources refers to beneficiaries who have evidence of Rx coverage outside of the Medicaid program -- these sources include private plans, Medigap plans, health maintenance organization plans, Veterans Administration plans, and others. The designation of unknown prescription coverage reflects beneficiaries for whom there was no definite affirmation or denial of Rx coverage. Thus, unknown prescription coverage reflects beneficiaries for whom there was evidence of no prescription coverage or who lacked supplemental insurance coverage of any kind. It is important to remember that the data used for this analysis predates implementation of the Part D provisions of the MMA.
Residential Setting
For the purposes of a Policy Brief, LTCF residents are those who lived in any facility type, including long-term nursing facilities, ALFs, and other congregate care and residential facilities, including rehabilitation, psychiatric, group homes, congregate care, bed and board, Mental Retardation and Developmental Disability residences, and others. These facility types are not differentiated in this paper (please see Policy Brief referenced in footnote 2 for details on differences by facility types). Residential stays in SNFs after a qualifying three-day post-acute hospitalization are not considered as a NH stay. Community-dwelling individuals are all those who are not in a LTCF.
The MCBS offers the ability to establish residence in a specific facility type during a period of time. Because individuals can reside in more than one facility during the year, this presented a methodological challenge in allocating prescription medication utilization and expenditures to facility type. For this project, prescription medications were assigned to the setting the respondent was determined to be in for the month of prescription. For months where the respondent moved between several long-term settings a systematic approach was used to resolve the most likely setting to assign.
| TABLE 1. Stability of Individual Residence by Facility Type, 1998-2001 | ||||
| 1998 | 1999 | 2000 | 2001 | |
| % NH residents solely in a NH setting (N=1,832,837) | 90.9% | 88.4% | 87.4% | 87.7% |
| % ALF residents solely in an ALF setting (N=287,566) | 85.9% | 82.0% | 72.5% | 76.6% |
| % Other residents solely in OF settings (N=839,532) | 76.2% | 72.6% | 67.6% | 71.6% |
| % of residents across all settings who remain in just 1 setting | 93.1% | 91.1% | 89.3% | 90.5% |
| SOURCE: MCBS, 1998-2001 | ||||
In general, there is considerable stability in individual residence across facility types study years. Residents in NHs show highest degree of stability ranging from 88-91% of residents who remain in just that setting, followed by Assisting Living (range 76-86%). Residents of other facility (OF) settings show the highest degree of mobility across settings (Table 1).
The MCBS contains a small segment (1.6%) of individuals who spend time in both the community and in a facility setting. For the purposes of this report, this special subset of individuals, are considered facility dwelling in terms of reporting. Due to the nature of how the PME file is constructed, these individuals are also prone to have annual prescription drug expenditures imputed on their behalf instead of just for the time they remained in the community (mean time in community is 162 days). This argued for dropping their community expenditures at the cost of slight underestimation of total PME expenditures.
Methods
For all analyses, we rely on univariate, bivariate, and multivariate techniques. All findings are weighted to provide national estimates and make adjustment for the complex sampling design of the MCBS. SAS Version 9.1 was used for all analyses.
III. MAJOR FINDINGS
In this section, we briefly present highlights from each Policy Brief.
POLICY BRIEF 1: National Estimates of Prescription Drug Utilization and Expenditures in Long-Term Care Facilities[http://aspe.hhs.gov/daltcp/reports/2006/pdnatest.htm]
The aims of the first Policy Brief are twofold: (1) to produce national estimates of prescription utilization and spending in LTCFs for the period 1998-2001; and (2) based on these findings, project national prescription drug expenditures through 2005. Thus, in this Policy Brief we provide a detailed snapshot of prescription drug use and spending in 2001, the latest year for which complete data are available. For this analysis, we present summary findings of:
- Characteristics of Medicare beneficiaries residing in LTCFs, overall and by facility type.
- Total and percent of utilization of prescription drugs by Medicare beneficiaries residing in LTCFs, overall and by facility type.
- Total and per user expenditures of prescription drugs by Medicare beneficiaries, overall and by facility type.
- Comparison of prescription drug spending by Medicare beneficiaries by eligibility status (SSDI-eligible less than 65 and aged 65 and older).
- Comparison of prescription drug use and spending by Medicare beneficiaries by four payor sources -- Medicaid, private prescription with drug coverage, no drug coverage supplementation, and all other coverage with drug coverage status unknown.
For the second aim, we focused on total LTCF prescription drug utilization and spending trends from 1998-2001, overall, and by therapeutic category. Using linear and non-linear projection approaches, we project spending through 2005.
Findings. In 2001, nearly 2.7 million Medicare beneficiaries living in NHs and other LTCFs spent more than $5.4 billion on prescription drugs. In this population, Medicaid is the largest payor of prescription drugs. The under age 65 SSDI Medicare population is growing as a proportion of Medicare beneficiaries and also constitute a driving force behind the number and types of prescription medication expenditures. Indeed, in 2001 Medicare SSDI beneficiaries spent, on average, $828 more on prescription drugs than did their counterparts qualifying for Medicare on the basis of age.
Overall population growth in LTCFs from 1998-2001 was nominal, spurred by growth in two sectors -- Assisted Living and Other Facilities. This increase in the OF population is primarily due to increases in the disabled population. Growth in ALFs, while notable, is driven primarily by relatively healthy Medicare-eligibles age 65 and older and still represents a relatively small proportion of total LTCF beds. The differential findings for coverage type and eligibility status suggest that these populations are very different in terms of prescription drug utilization and expenditures patterns and should be considered as such in future policy and research analyses.
The Top 10 therapeutic categories that accounted for approximately three-quarters of all prescription drug spending in LTCFs are:
- Psychotherapeutics
- Gastrointestinals
- Autonomics
- Cardiovascular
- Cardiac drugs
- Central Nervous System drugs
- Anti-infectives
- Anti-arthritic agents
- Blood modifiers
- Hormones
These categories were the most commonly used, regardless of facility type, coverage source, and eligibility status. Efforts to manage the use of and spending on prescription drugs in LTCFs most likely would focus on these classes. Psychotherapeutic agents were the most commonly utilized therapeutic class, as well as the most expensive class, accounting for more than one-quarter of all drug spending. Psychotherapeutic drug use was driven by disabled individuals who were dually eligible for Medicare and Medicaid.
Mean annual growth in prescription drug spending across all LTCFs was 11.9% over the three year period, with the greatest growth noted in ALFs. Based on the our findings of total drug spending over the four years of data observed, we projected total prescription drug expenditures in the LTCF Medicare beneficiary population using three different modeling approaches: (1) linear; (2) non-linear; and (3) a non-linear approach based on the sum of therapeutic categories.
Based on our analysis, total prescription drug expenditures in LTCFs are estimated to range from $7.8-$10.5 billion in 2005 (Table 2). The different types of projections of prescription drug spending for 2005 illustrate the large differences the modeling assumptions can create. For example, projected 2005 expenditures using a linear projection model shows expenditures at $7.8 billion while the non-linear total expenditure projection estimate is $9.4 billion, and the non-linear projections based on the sum of individually trended therapeutic classification rises still further to $10.5 billion.
| TABLE 2. Actual and Projected Prescription Drug Expenditures, 1998 2005 | ||||||||
| Projected Expenditures byDifferent Projection Models($ in millions) | % Increasefrom 2001 Estimates | |||||||
| 2002 | 2003 | 2004 | 2005 | 2002 | 2003 | 2004 | 2005 | |
| Linear | 5,918 | 6,547 | 7,175 | 7,803 | 9.0% | 20.6% | 32.2% | 43.8% |
| Non-linear, total $ | 6,141 | 7,087 | 8,180 | 9,441 | 13.1% | 30.6% | 50.7% | 73.9% |
| Non-linear, Sum of Therapeutic Categories | 6,252 | 7,381 | 8,780 | 10,524 | 15.2% | 36.0% | 61.8% | 93.9% |
| SOURCE: MCBS, 1998-2001 | ||||||||
POLICY BRIEF 2: A National Comparison of Prescription Drug Expenditures by Medicare Beneficiaries Living in the Community and Long-Term Care Facility Settings[http://aspe.hhs.gov/daltcp/reports/2007/pdnatcom.htm]
In the second Policy Brief, we examined differences in socio-demographic and drug utilization and expenditures characteristics of Medicare beneficiaries residing in LTCFs and those residing in the community. We focused in particular on several factors thought to differ markedly by residential status: Medicare eligibility status, payor source of prescription drug coverage, and therapeutic drug class. As in the first Policy Brief, we continued to see differences in prescription drug use and spending patterns between individuals who are Medicare-eligible on the basis of SSDI versus those who are eligible on the basis of age (65 and older). These differences are due to the heterogeneity of the two populations in terms of disease burden, severity-of-illness, and types of prescription medications required to treat their medical conditions. We found that source of prescription drug coverage also varied by residential setting, with more Medicaid-dual eligibles and Medicare-only populations residing in institutions. Finally, differences in types of illness, as well as severity-of-illness and polymorbidity, drives differences in the types of prescription drugs used by community versus institutionalized beneficiaries.
The aim of this particular project was to produce national estimates of prescription drug use and spending patterns by Medicare beneficiaries residing in LTCFs and the community for 2001. To this end, we provide a snapshot of prescription drug use and spending in 2001, the latest years for which complete community and LTCF drug data are available. For this analysis, we present summary findings of:
- Characteristics of Medicare beneficiaries residing in LTCFs and the community.
- Overview of prescription drug utilization and expenditures, overall and by therapeutic category.
- Prescription drug expenditures by prescription coverage source and eligibility status.
Findings. In 2001, more than 41 million Medicare beneficiaries spent more than $55 billion on prescription drugs. Of this amount, 9.9%, or $5.4 billion, was accounted for by the 2.7 million Medicare beneficiaries living in LTCFs. Mean annual prescription drug expenditure by user is markedly higher in LTCF resident than in their community-dwelling peers ($2,077 per user versus $1,571 per user, respectively).
Total prescription spending for the Top 10 therapeutic classes in the United States accounted for $39.9 billion, or 72.8% of total prescription drug spending. The Top 10 spending therapeutic categories accounted for 73.0% of total spending in the community ($36.1 billion), and 72.2% of spending in LTCFs ($3.8 billion).
| FIGURE 1. Comparison of Prescription Drug Utilization and Expenditures in Community and LTCF Medicare Beneficiaries, 2001 |
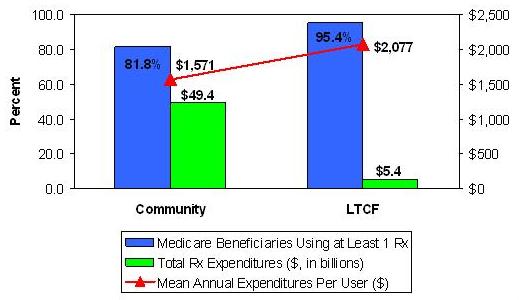 |
| SOURCE: MCBS, 2001. |
Spending for prescription drugs varied markedly by therapeutic category, prescription drug coverage source, and eligibility status, both within and across residential setting types. In the absence of any diagnostic or functional assessment, prescription drug spending is largely driven by coverage source, with Medicaid being the dominant payor of prescription drugs for beneficiaries residing in facility settings, and private coverage paying the lions share for community beneficiaries.
Much of this variation is likely related to the health status of individuals within residence setting. Indeed, beneficiaries residing in LTCFs are likely more frail, have greater comorbidities, and greater severity-of-illness than their community-residing counterparts. It also is likely that health status varies markedly with prescription coverage source as well; individuals with private coverage are likely to be healthier than those with Medicaid coverage and those without any drug benefit. In depth examination of health status differences was not a mandate of the proposed research; however, future work, using multivariate analysis to control for such differences, may shed light on this issue.
Variation in drug spending, also within and across residential settings, also occurs by eligibility status. Individuals who qualify for Medicare on the basis of disability are likely to have greater physical and psychiatric comorbidities, thereby accounting for higher total and per user drug expenditures. On average, SSDI-eligible individuals in the community expended $2,444 for of prescription drugs, compared to per user spending of $2,775 by SSDI-eligibles residing in facilities, a mean difference of $331 per year. Within LTCFs, there were higher per user payments for SSDI beneficiaries than their aged counterparts ($2,775 versus $1,962); in the community, SSDI-eligibles also spent on average nearly $1,000 more than their aged counterparts ($2,444 versus $1,418).
Coverage for prescription drugs varied by residence setting as well; private plans accounted for nearly two-thirds of total prescription drug spending by Medicare beneficiaries (Figure 2). Medicaid spending for prescription drugs accounted for less one-fifth of drug spending, while at 16.9% of drug spending by Medicare beneficiaries was paid for out-of-pocket.
| FIGURE 2. Total Prescription Drug Spending by Medicare Beneficiaries by Prescription Coverage Source |
 |
| SOURCE: MCBS, 2001. |
In LTCFs, drug spending by Medicaid-covered beneficiaries accounted for the greatest proportion of drug expenditures by Medicare beneficiaries (52.3%, or $2.81 billion, of total prescription drug expenditures). In the community, however, Medicaid paid for only 14.3% of total drug spending by Medicare beneficiaries. Indeed, community-dwelling beneficiaries drug spending is primarily driven by coverage from other, non-Medicaid private and public prescription drug sources, which pay for 68.8% of prescribed medications. Medicare beneficiaries, regardless of residential setting, spent nearly $9.3 billion out-of-pocket (or from other prescription drug coverage sources not accounted for by the MCBS) for prescribed medicines. The proportion of out-of-pocket drug spending was higher in LTCFs than in the community (22.0% versus 16.4%, respectively). Some of the institutional drug spending may be paid for by the facility.
In general, the Top 10 therapeutic categories accounted for approximately two-thirds of all prescription drug spending in LTCFs and in the community. There was little variation in Top 10 spending when further stratified by eligibility status and prescription coverage source. However, there is significant variation in the drug classes which comprise the Top 10 use and spending by residential setting. Once again, these differences reflect the unique population residing in LTCFs.
POLICY BRIEF 3: Drug Use and Spending for Medicare Beneficiaries During Part A Qualifying Skilled Nursing Facility Stays and Non-Qualifying Long-Term Care Facility Stays[http://aspe.hhs.gov/daltcp/reports/2007/druguse.htm]
Prior to the introduction of the Part D prescription drug coverage expansion in 2006, Medicare beneficiaries in LTCFs relied on various payment sources to cover their medication costs, including Medicaid, Medicare (for Part B specialty drugs and Part A SNF stays), private insurance, and out-of-pocket payments. However, with the implementation of the Part D drug benefit, beneficiaries in LTCFs now have the same broad selection of prescription drug plans (PDPs) and Medicare Advantage plans available to their community-residing counterparts. Part D, however, does not alter Part A coverage for drugs during qualified SNF stays, which raises the question: how are drug utilization patterns affected for beneficiaries who transition between SNF episodes and non-qualifying LTCF stays?
To address this question, we examined three specific aims:
- To characterize Medicare-qualified SNF stays in relation to other episodes of long-term institutional care that beneficiaries experience.
- To learn more about medication use and spending patterns during SNF stays.
- To compare prescription drug use and costs during SNF and non-qualified LTCF stays for Medicare beneficiaries who experience both types of episodes.
Findings. The relationship between SNF episodes and other long-term care stays is heterogeneous and involves complex transition patterns between the community, hospital, SNF, and OF stays. Among beneficiaries with both SNF and other long-term care stays, nearly one-third (27%) of their person-months contained at least one SNF stay, 54% were facility-only months, 7% were SNF-only stays, and the remaining months were spent in the community.
We compared drug utilization patterns between SNF-only months, SNF + facility months, and facility-only months (Table 3). Drug utilization rates were similar across all three residential situations, with medication use (prescriptions and/or OTC) was recorded in virtually all the resident months (92%-94%). The average beneficiary with both SNF and other LTCF exposure was administered 9.2 unique medications per person-month, with little variation by residential situation. Medication rates for prescription drugs were somewhat higher during SNF + LTCF months (6.7 unique medications per month) compared to SNF-only and LTCF-only months (6.3 unique medications per month). Medication administrations per month, however, showed a reversed pattern, with SNF + LTCF-only months having 196 medication administrations per month compared to 249 medication administrations per month in LTCF-only months.
| TABLE 3. Medication Utilization and Expenditures for Medicare Beneficiaries with SNF and other Long-Term Care LTCF Stays, 2001 | |||
| Medication Measures Per Patient Month | Residential Situation | ||
| Months with only SNF Daysa | Months with SNF and LTCF Daysa | Months with only LTCF Daysa | |
| Number of months with residential situation | 195 | 433 | 1,610 |
| Mean potential LTC therapy days per month | 30.2 days | 24.2 days | 29.3 days |
| Percent of months with medication use | 94.4% | 91.5% | 94.3% |
| Mean number of unique medications (se) | |||
| OTC drugs | 2.9 (0.16) | 2.7 (0.10) | 2.8 (0.5) |
| Prescription-only drugs | 6.3 (0.30) | 6.7 (0.20) | 6.3 (0.09) |
| Total drugs | 9.2 (0.37) | 9.4 (0.25) | 9.1 (0.12) |
| Mean number of drug administrations (se) | |||
| OTC drugs | 99.5 (7.1) | 79.4 (4.3) | 109.4 (2.5) |
| Prescription-only drugs | 237.3.8 (12.0) | 195.7 (7.2) | 248.8 (4.0) |
| Total drugs | 336.8 (15.4) | 275.1 (9.9) | 358.3 (5.4) |
| Mean monthly expense for prescription-only drugs (se) | $264 (15.8) | $224 (11.3) | $246 (5.2) |
| Mean expense per prescription | $41.90 | $33.43 | $39.05 |
SOURCE: MCBS, 2001.
| |||
Mean estimated monthly expenditures for prescription-only medications ranged from $224 per month (SNF + LTCF months) to $264 (SNF-only months). Similarly, SNF-only months had the highest per script expense ($42 per script) compared to SNF + LTCF months ($33 per script) and LTCF-only months ($39 per script).
In multivariable regression analyses, we found that controlling for other factors, including potential long-term care therapy days, has a relatively small impact on measured differences in drug use by residential situation. There are significant differences between months with SNF + LTCF days and those with LTCF-only days. In the former situation, beneficiaries are prescribed significantly more unique prescription drugs but receive fewer monthly drug administrations; the difference washes out when comparing monthly prescription drug costs. The only other significant findings are slightly lower rates of prescription and total drug administrations in SNF-only months compared to facility-only months. However, these differences are not associated with significantly lower drug spending during SNF months.
IV. POLICY IMPLICATIONS, CONCLUSIONS, AND DIRECTIONS FOR FUTURE RESEARCH
This series of studies provides the first national estimates of prescription drug utilization and expenditures by Medicare beneficiaries residing in LTCFs. In addition to quantifying prescription medication spending by this population, it also provides details on how prescription drug spending varies by residential setting (NH, ALF, and other institutions), prescription drug coverage source and type, Medicare eligibility status, and therapeutic drug class The analysis also presents prescription drug utilization and spending by LTCF beneficiaries in context of total Medicare prescription drug utilization and spending. Finally, this research provides a first glimpse at an elusive population: individuals who transition between SNF episodes and non-qualifying LTCF stays.
Findings from this study are useful for a number of reasons. Perhaps most significantly, they provide benchmark for future prescription medication spending by Medicare beneficiaries residing in LTCFs. While our data precede the MMA enactment by five years, our projection estimates suggest the growing importance of prescription medications in long-term care institutions. These results also demonstrate the need for careful consideration of important covariates, as our analyses show that Medicare beneficiaries who qualify on the basis of SSDI.
Of course, as the Policy Brief illustrates, there is variability in which categories are most frequently used; these differences are most notable when examined by facility type, coverage source, and eligibility status because these groups embody different medical conditions and needs. What is not examined here is how clinical variability, in terms of actual diagnoses as well as severity-of-illness, influences drug spending. Under the MMA, Medication Management Therapy services are provided to individuals with a high disease and/or drug burden, which may end up altering drug spending patterns in the future.
Even though the most recent estimates provided here are from 2001, it is likely that psychotherapeutics will constitute a large proportion of LTCF drug spending under the MMA. Indeed, under the Part D provisions, most psychotherapeutic pharmacologic classes, including antidepressants, antipsychotics, and anticonvulsants (many of which are used to treat mental health conditions) enjoy special protections including the provision that all drugs in each class be excluded from PDP formularies. These protected classes, however, may still be subject to prior authorization and differential copayments, which may influence utilization patterns. Thus, the psychotherapeutic agents remain a broad therapeutic category to monitor as the MMA unfolds. Gastrointestinal agents are the second most expensive therapeutic class in LTCFs, and account for another one in ten prescription drug dollars. The next three most expensive therapeutic classes warrant scrutiny in the future: the autonomic agents, comprised of some antihypertensive agents (e.g., beta-blockers) and drugs used to treat Parkinsons disease, cardiovascular drugs, and the central nervous system drugs, which include the anticonvulsant agents such as lamotrigine and gabapentin.
Medicare Part D is now undergoing its second year of implementation. These findings provide a useful benchmark for use and spending of prescription drugs in the Medicare population. Most significant, it considers the LTCF and SSDI-eligible Medicare subpopulations, both of which are of considerable interest to policy-makers. This project suggests these two populations, of which there is considerable overlap, may warrant further attention. The LTCF population uses markedly different medications, and spends considerably more. As well, NHs and other LTCFs have higher per beneficiary medication expenditures, most likely reflecting the frailer and sicker populations who reside in them.
Our research also points out the differences in the community-dwelling and institutionalized beneficiary populations. Not only are LTCF beneficiaries sicker than their community-residing peers, they also use dramatically different therapeutic classes. Therapeutic differences also abound by eligibility status, with SSDI-eligible beneficiaries using different therapeutic classes than beneficiaries who qualify on the basis of age. Thus, considerations to formulary guidance should consider intra-population differences among Medicare beneficiaries.
Study Limitations
Mastery of the 70-plus individual computer program algorithm used by CMS to generate community drug prices took considerable effort, as the drug data available in the MCBS for facility beneficiaries is collected and formatted very differently than seen with community beneficiaries. As the only non-governmental users of the MCBS IDA files, UMB researchers were challenged on many different fronts with this data and algorithm, including the challenge of working with different dosage forms not commonly used by community-dwelling individuals, the assignment of drug names and therapeutic classes for unusual medications, and generally fitting the data into the algorithm that allowed the algorithm to produce reliable estimates. In addition, once raw unadjusted prices are generated by the algorithm, further adjustment by payor source was required. We discovered that these adjustments are in need of updating.
Other study limitations included:
-
Findings are generalizable to Medicare beneficiaries only, as the MCBS does not include information on non-Medicare-eligible individuals.
-
Findings are generalizable to certain types of LTCFs, namely those that are Medicare-eligible facilities with 24/7 continuous nursing care and centralized medication management. Thus, findings of prescription drug use and spending in assisted living and other facilities are likely underestimated.
-
Due to differences in how medication data is collected, maintained, and analyzed, it is very difficult to make meaningful utilization comparisons between community and LTCF beneficiaries. Spending estimates, however, are comparable.
-
Projection models are inherently sensitive to assumptions, as evidenced by the wide variability of total growth estimates ranging from 44% to 94%, depending upon model and when referenced to 2001 spending. The projection of prescription spending into the future is always sensitive endeavor and subject to cumulative influences of the assumptions behind the growth models.
Future research could use more recent data. Public-use MCBS data are available for 2004; 2005 and 2006 IDA data have been collected. However, the programming and analytic files construction for IDA data for these years have not yet been conducted. Once the IDA analytic files are developed, and the associated drug dictionary is updated, then results for 2004-2006 could be made quickly available. Future analyses could also employ multivariable methods to control for the covariates examined in these three Policy Briefs, as well as those not considered. In particular, measures of comorbidity and severity-of-illness are key to our understanding of prescription drug utilization and expenditures in the community and institutionalized Medicare beneficiary population.
Other potential research opportunities identified as part of this project might include:
-
A refined analysis of spending projections in LTCFs, controlling for key covariates such as payor source, eligibility status, and severity-of-illness.
-
Comparison of projected estimates with actual estimates of prescription drug spending once Part D data become available.
-
Analysis of spending trends over time, stratified by facility type, payor source, severity-of-illness, eligibility status, and therapeutic class. Trends could span the pre and post-Part D implementation period.
-
Simulations of changes in preferred drug use and how changes in drug use within class may affect total expenditures for prescription medications.
-
Examination of potential offsets in utilization of and expenditures for health care services, such as emergency department visits, hospitalizations, and transitions into and out of LTCFs, given changes in formulary changes.
In summary, this project provides the first detailed and national estimates of prescription drug utilization and expenditures by Medicare beneficiaries residing in LTCFs. These estimates are useful and needed benchmarks for monitoring medication use and spending patterns, especially as the MMAs prescription drug expansion enters its second year. Future work should focus on using more current data, including up to and past January 2006, and should employ multivariable methods to control for important covariates explaining variation in medication use and spending patterns.
LIST OF REPORTS
Prescription Drug Spending by Medicare Beneficiaries in Institutional and Residential Settings, 1998-2001
HTML version: http://aspe.hhs.gov/daltcp/reports/2007/pdspend.htm
PDF version: http://aspe.hhs.gov/daltcp/reports/2007/pdspend.pdf
POLICY BRIEF #1: National Estimates of Prescription Drug Utilization and Expenditures in Long-Term Care Facilities
HTML version: http://aspe.hhs.gov/daltcp/reports/2006/pdnatest.htm
PDF version: http://aspe.hhs.gov/daltcp/reports/2006/pdnatest.pdf
POLICY BRIEF #2: A National Comparison of Prescription Drug Expenditures by Medicare Beneficiaries Living in the Community and Long-Term Care Facility Settings
HTML version: http://aspe.hhs.gov/daltcp/reports/2007/pdnatcom.htm
PDF version: http://aspe.hhs.gov/daltcp/reports/2007/pdnatcom.pdf
POLICY BRIEF #3: Drug Use and Spending for Medicare Beneficiaries During Part A Qualifying Skilled Nursing Facility Stays and Non-Qualifying Long-Term Care Facility Stays
HTML version: http://aspe.hhs.gov/daltcp/reports/2007/druguse.htm
PDF version: http://aspe.hhs.gov/daltcp/reports/2007/druguse.pdf
ATTACHMENT: PRICING ALGORITHM REVIEW
EXECUTIVE SUMMARY
The implementation of the Centers for Medicare and Medicaid Services (CMS) community-based Pricing Algorithm to the drugs found in an institutional setting marks the first time pricing of drugs for this population using the existing algorithm has been tried. The algorithm itself is comprised of approximately 3,000 lines of code and required only mild modifications to accommodate the new data source. While referred to as an algorithm, there are actually a three primary functions performed by this code which, in their totality, allow any input drug records to be priced.
The implementation using drugs delivered in the nursing home (NH) itself did not attempt to change the method by which drugs are priced. Some modifications of the code were required to accommodate some of the data found in the institutional (or IDA) drugs. A few minor programming bugs were also uncovered in the process of auditing results or investigating processing exceptions. The result of the implementation was to have an output file that had 98% of the prescription drug events priced. Analyses of the 2% of records that remained un-priced show that these records to be for select sub-sets of particular forms of drugs and fully explicable in terms of the algorithm.
The complexity involved with the description and performance of the algorithm requires a slightly specialized vocabulary. Some of the broader processes and overview of the algorithm programs are briefly sketched out in the first part of the following document. More detailed looks at its performance are found in the second half. Finally, comparisons between community and institutional drugs are discussed in the third. The document concludes with some observations on the process of pricing drugs in using the IDA files and making a fair comparison to those in the community setting.
Special care has been made to keep the language at a largely non-technical level so that a specific knowledge of programming or pharmaceuticals is not required. However, this document is about the implementation of a series of computer programs involving prescription medications so some specifics cannot avoid being mentioned.
The Algorithm Works
The implementation of pricing prescription medications in the institutional setting was successfully priced the input drug records. The data requirements of the algorithm itself were largely met by the IDA input file resulting in 99.9% of PILLS to be given a price and 92% of NON-PILLS to be given a price. The balance of the NON-PILLS (~8%) that could not be priced was almost exclusively due to an algorithmic decision not to price drugs with quantities less than five.
The One Difference -- IDA lacks Package Size information
This implementation of pricing prescription medications in the institutional setting uncovered only one serious data flaw between the two different input datasets (i.e., community and institutional). Because this difference is based on the actual survey instrument used to collect data, this difference was not reconcilable. In the community setting there are two questions asked of non-pill medications that are not asked in the institutional setting.
This difference meant that for non-pill forms of drugs (approximately 15% of all prescription medications that could be priced), the algorithm did not have enough input information to make a successful direct match. As a result, for these medications the algorithm provided a best guess concerning the missing information (i.e., amount of drug) and priced the record according. There appears to be evidence that a high degree of similar best guesses is also done in the community setting as well, so while the data is collected, it is not in a value that the algorithm considers to be legitimate.
Price Comparisons
The solution of the problem of pricing medications that do not include unique National Drug Codes that identify (and indeed, are associated with) specific prices is a big challenge. The necessary compromises and decomposition of the problem into more tractable solutions as done by the current algorithm have been shown to be implementable to the IDA drugs records largely as-is. Use of an external Prescription Drug Claims File (in this case MAX data) to help guide the selection of drugs when input data is incomplete, missing, or erroneous ensures that larger systematic problems (such as the IDA files lack of non-pill amounts) are corrected by algorithms determination of new values that reflect values which exist in the real world. As far as an algorithm goes, the test of the functionality is the ability to provide it different data sources and have it work with minimal changes having to be made. This was accomplished on a technical basis and further audits of what was driving the cases where things did not go as planned resulted in fully expected explanations.
Comparisons of the costs of prescription medications between community and institutional settings are complicated by challenges to the casual assumption that drugs is drugs. The number of equivalent medications between these two settings was not as great as presumed and varied considerably by both specific medication and dosage form and reflects the differences in the constituent communities being surveyed. Fair comparisons need to keep in mind that specific medications are not used equally across these two populations. It remains an analytic and programmatic decision whether to report aggregate pricing at higher levels such as therapeutic classification.
PRICING ALGORITHM PREAMBLE
The Pricing algorithm is a series of separate programs that take an input drug file and match entries to a universe of drugs, and from them determine a price for the input drug. If there is a direct match, then a price is assigned to the drug. If there is not a direct match, then there are some attempts to fill in the blanks and determine a reasonable value for any values that are missing, or may not be in agreement with the range of values that the algorithm considers its universe of drugs (i.e, First DataBank).
The Pricing algorithm itself can be considered a Legacy Program. It was developed a number of years ago and has not been changed since its initial creation. It is through inspection of the original source code that the determination of the logic of its inner workings was made and allowed the ability to perform modifications to the code itself. The challenge of providing priced drug records for an input drug file that contains no NDCs is a complicated affair and the solution offered by the set of programs that make up the algorithm has withstood the test of time. This set of programs has proven to be robust.
Being a Legacy Program, there were no attempts made to modify or alter any of the logic that made up the programs. Some mild coding bugs were uncovered and some hard-coded lists of drug forms were made, but essentially the implementation of the algorithm using a new Input Drug File is faithful to that performed using the Community Prescription Medication Event (PME) file of the Medicare Current Beneficiary Survey (MCBS).
ALGORITHM VOCABULARY
There is a specialized vocabulary that comes with description of the PME pricing algorithm. There is a glossary at the end of this document that serves as a formal definition of all terms that may be considered specialized and not obviously intuited.
The words required to get an immediate handle on the large components involved in the algorithm are:
INPUT and FINAL PRICE FILE CMS CROSS-REFERENCE FILE ROLLUP FILES (DOSAGE FORM, STRENGTH, and PACKAGE SIZE) INPUT DRUG FILE (aka IDA File) FINAL PROCESSED FILE
The words required to get a handle on the three processes of the algorithm are:
FINAL PRICE FILE CONSTRUCTION ROLLUP FILE CREATION MATCHING PROCESS
These terms contain the essence of the pricing algorithm and will allow one hours and hours of conversation with any of the original developers of the programs.
This preamble is not intended to suggest that the reader has an insufficient vocabulary to understand that algorithm itself but rather more of an admission that the author is a little unsure of how to adequately describe the abstractions and processes contained therein without going into unnecessary pages and pages of text.
PRICING ALGORITHM REVIEW
The pricing algorithm was originally developed to price drugs used in the community portion of the MCBS survey (hereafter referred to as PME Drugs). Implementation of this algorithm to the institutional setting had never been attempted before and so no direct comparisons were available as benchmarks.
A simplified schematic of the entire process is found below and forms a useful template for further discussions. By necessity it is a simplified depiction and elaborations on pertinent details are included as required in the following discussions.
| The 3 Primary Processes of the Pricing Algorithm | |
 |  |
 | |
 | |
The PRICE FILE Process
The PRICE FILE process takes a collection of individual drug price records and creates a final price file by adding additional information in the form of:
- Weights based on an external data file (e.g., MAX data).
- Alternate names for the drug that reflect the names that will be encountered in the input drug File (e.g., CMS x-reference File).
The resulting FINAL PRICE FILE is used as input to the ROLLUP FILE process.
The ROLLUP FILE Process
The ROLLUP FILE process takes the final price file and from it creates three individual Roll-up files that contain unique combinations of Dosage forms, Strengths, and Packages Sizes. These three individual roll-up files are then recombined into a FINAL COMBINED ROLLUP FILE which is used as the Master File to which input drugs are matched in order to be priced.
The MATCHING Process
The Matching Process is where the actual pricing of a drug record occurs. It involves first locating a matching record in the FINAL ROLLUP FILE, and then either:
- Locating a matching strength and unit data structure if a PILL.
- Locating a matching strength and Package Size if a NON-PILL.
If no direct matches are found, then:
- Replacement values for missing or erroneous values are selected by the algorithm based upon weighted probabilities of possible combinations for the specific Drug Name.
Drug Pricing and Event Pricing
Upon the successful location of a matching Rollup data structure, the associated price for the drug is used which is then:
- Multiplied by the amount of the tablets if a PILL.
- Multiplied by the number of packages if a NON-PILL.
Both of these mathematical extensions of prices for PILLS and NON-PILLS result in a final EVENT PRICE for the drug record.
Algorithm Processing Exceptions
Because the algorithm itself contains the necessary logic to determine replacement values for missing or erroneous information, actual processing exceptions are minimized. For example, if only an input record containing only a Drug Name were supplied to the algorithm, an event price could be determined on behalf of the algorithm. This self-correcting feature of the algorithm is not considered a processing exception, per se.
Bad Names
Input Drug File records with Drug Names that do not match any found in the COMBINED RULL-UP FILE are a legitimate processing exceptions and these drug names are output to a separate output file where they may be looked at during a later time for resolution.
Event Prices of 0.00
There are instances where an input Drug File record may be matched with an FINAL COMBINED ROLLUP FILE record and be given an EVENT PRICE of $0.00. This apparently contradictory result is not a processing aberration or program flaw but rather can reflect:
- The underlying constituent pricing records having no price.
- The algorithm consciously not pricing records due to its own internal logic.
- Over-the-counter (OTC) drug.
While prices of $0.00 may be an undesirable end result, the algorithm assigns this price either because it thinks that the unit price for the drug truly *is* $0.00 (hence the extended Event Price is $0.00), or because it has internal rules regarding the pricing of drugs. A price of $0.00 indicates, from a processing point of view, that a match was made and thus successfully priced.
Priced Output File
The end result of the pricing algorithm is the creation of a file that is very similar to the input file. This file contains a drug name, strength and unit, package size, unit price and extended Event Price. Because the algorithm can replace values for the input values of strength and unit, these replaced values are also retained. Lastly, there are some internal flags that contain codes that reflect the results of processing.
Summary
The three processes briefly mentioned above describe the three overall processes contained within the larger pricing algorithm. These three processes are discussed in further detail in the rest of the document, but the essence of the algorithm is captured by the sequence of:
- Creation of a FINAL PRICE FILE which is then;
- Converted into a FINAL COMBINED ROLLUP FILE which is then;
- Matched to the INPUT DRUG FILE by Drug Name.
What follows then are a number of detailed explanations of the components of these processes.
ALGORITHM BASICS
The overall structure of the pricing algorithm is to build a Master File of drug names and their prices (e.g., Price Files) and then converts them into a special format (e.g., ROLLUP FILES) which is then matched to a file of input drugs (e.g., IDA or PME drugs) for price determination. This simple sounding process is complicated by a lack of a unique identifying code for drugs (or NDC) that can specifically identify not only the dosage and strength of a drug but also the manufacturer and packaging.
NO NDC = NO EXACT PRICE
There is no NDC code captured as a part of the either community/PME or institutional/IDA data collection process and, as a result, prices for drugs cannot be made on a specific NDC-based FDB records. Instead, input drug records are matched by Drug Names and, after a drug name is located, searches are made on the behalf of the pricing algorithm based on the strength or package size of the drug.
ROLLUP FILES AS KEEPERS OF DETAILED DRUG INFORMATION
Matches attempted by the algorithm are thus made on a Drug Name alone and this requirement brings an additional complication since many drugs come in multiple strengths (e.g., GLYBURIDE has three tablet strengths of 1.25, 2.5, and 5 mgs). The presence of ROLLUP FILEs are the algorithmic solution to this dilemma and they contain the unique combinations for the various dosage forms and strengths and package sizes that are possible for a given drug name.
The pricing algorithm divides all input drug records into PILLS and NON-PILLS based upon the kind of dosage form that is found with the input record. PILLS and NON-PILLS go through a similar logic in the effort to assign prices, but different Roll-up files are used to look up the information.
Only a handful of data elements are required to determine prices. The data elements required by the algorithm are summarized shown below. Prices are not assigned to OTC drugs.
Data Requirements By
| PILLS | NON-PILLS | |
| Drug Name | X | X |
| Dosage Form | X | X |
| Strength & Unit | X | X |
| Amount (Package Size) | X |
Trans Process Universal Items
Before the Three Processes are discussed in further detail, some other terms are best defined now since they commonly used or are fundamental
FIRST DATABANK (FDB)
This is actually is the name of the Company who provides what is considered by many to the industry standard of electronic drug information. In the context of the algorithm it is used to refer to a datafile that contains individual price records for individual drugs, each identified by an NDC. In addition to variety of drug prices (there are seven types of prices), there are also a number of other variables that indicate other characteristics of the drug (obsolete date, strength and unit, dosage form, etc.). The algorithm creates a subset of only a few variables that are required for pricing. This is considered the comprehensive list of all drugs currently available.
LEGEND AND OVER-THE-COUNTER DRUGS
The FDB records contain categorizations of all drug records into drugs it considers requiring a Prescription for dispensation and those that do not. The term LEGEND is used to describe drugs that can be obtained only through a prescription. The term OVER-THE-COUNTER (OTC) is used for drugs (or other agents) that are freely purchased without a prescription.
It should be noted that the algorithm prices only LEGEND drugs and leaves OTC drugs unpriced.
DRUG FORMS -- PILLS and NON-PILLS
The algorithm divides all drugs into PILLS and NON-PILLS depending on the Dosage Form contained in the FDB database. PILLS refer to solid and collectively discrete forms of administrations that are swallowed and so refer to capsules, tablets, caplets, lozenges, etc. Patches (e.g., nitroglycerin) are a lone exception and also included in this grouping. For PILLS, the strength and unit of the drug is considered in pricing.
NON-PILLS refer to drugs that are non-solid in form, generally speaking. The largest groups are liquids, injectables, creams, and aerosols, and powders (there are 11). For NON-PILLS, the strength and unit AND amount of drug in the container are considered. The amount of drug in the container is also known as the PACKAGE SIZE. This generally reflects the volume or amount of the drug in the tube, vial, or bottle. This is an important consideration for the institutional side of the process as will noted later on.
Drug Names
The raw FDB Price File contains three types of drug names: LABEL Name, BRAND Name, and GENERIC Name. LABEL names are best thought of as Name + Strength + Drug Form (e.g., ZYRTEC, 10mg Tablet or ZYRTEC, 1mg Vial). BRAND names are often the same name but with strength and Dosage Form removed (e.g., ZYRTEC). GENERIC names are often the name of the active chemical compound found in the medication, though not necessarily (e.g., Cetirizine HCL is the active ingredient of Zyrtec). This presents any process that relies on matching drug names a variety of possibilities since up to three different names may be used to identify a drug.
Illustrative examples of the three types Drug Names are shown below:
| FDB LABEL NAME | FDB BRAND NAME | FDB GENERIC NAME |
| AMITRIPTYLINE HCL 100mg TAB | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| AMITRIPTYLINE HCL 10mg TAB | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| AMITRIPTYLINE HCL 150mg TAB | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| AMITRIPTYLINE HCL 25mg TAB | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| AMITRIPTYLINE HCL 50mg TAB | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| AMITRIPTYLINE HCL 75mg TAB | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| AMITRIPTYLINE HCL POWDER | AMITRIPTYLINE HCL | AMITRIPTYLINE HCL |
| ELAVIL 100mg TABLET | ELAVIL | AMITRIPTYLINE HCL |
| ELAVIL 10mg TABLET | ELAVIL | AMITRIPTYLINE HCL |
| ELAVIL 10mg/ml VIAL | ELAVIL | AMITRIPTYLINE HCL |
| ELAVIL 150mg TABLET | ELAVIL | AMITRIPTYLINE HCL |
| ELAVIL 25mg TABLET | ELAVIL | AMITRIPTYLINE HCL |
| ELAVIL 50mg TABLET | ELAVIL | AMITRIPTYLINE HCL |
| ELAVIL 75mg TABLET | ELAVIL | AMITRIPTYLINE HCL |
| ENDEP 10mg TABLET | ENDEP | AMITRIPTYLINE HCL |
| VANATRIP 50mg TABLET | VANATRIP | AMITRIPTYLINE HCL |
| AMIGESIC 500mg TABLET | AMIGESIC | SALSALATE |
| AMIGESIC 750mg CAPLET | AMIGESIC | SALSALATE |
| ARGESIC-SA 500mg TABLET | ARGESIC-SA | SALSALATE |
| DISALCID 500mg CAPSULE | DISALCID | SALSALATE |
| DISALCID 500mg TABLET | DISALCID | SALSALATE |
| DISALCID 750mg TABLET | DISALCID | SALSALATE |
| MONO-GESIC 750mg TABLET | MONO-GESIC | SALSALATE |
| SALFLEX-500 TABLET | SALFLEX | SALSALATE |
| SALFLEX-750 TABLET | SALFLEX | SALSALATE |
| SALSALATE 500mg TABLET | SALSALATE | SALSALATE |
| SALSALATE 750mg CAPLET | SALSALATE | SALSALATE |
| SALSALATE 750mg TABLET | SALSALATE | SALSALATE |
In this typical example using two generically named drugs (Amitriptylene HCL and Salsalate), there are 28 LABEL names that resolve down to ten BRAND Names. The 2001 FDB Pricing files contains 106,861 unique FDB drug records that were in effect during the time window allowed. These unique FDB drug records also represent:
- 34,842 unique LABEL NAMES.
- 18,989 unique BRAND NAMES.
- 4,664 unique GENERIC NAMES.
The pricing algorithm uses the BRAND NAME as the distinguishing Drug Name for organizational purposes and from there uses the Strength+Unit, Dosage Form and Package Size (as is seen in the LABEL NAME) to build more detailed hierarchical data structures that are contained in ROLLUP Files which identify specific Strengths + Units, and Package Sizes and associated prices.
PRICING PROCESS FILES
The pricing process as shown below uses three separate input files to develop the final price file.
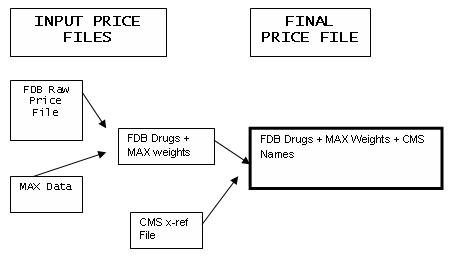
FDB Raw Price File
Drug prices for specific drug, dosages and dosage forms are contained in records that come from First Data Bank (FDB), a large national source of drug information. Year-specific price files are created because the FDB database maintains historic prices for up to seven prior prices. A Raw Price File is constructed from all FDB drug records that had active NDCs for a time window that matches the year of drugs to be priced. The window is defined as a two-year window that ends in July 15th of the year being priced. This means that pricing for drugs in 2001 would be based on all FDB records that showed an NDC that was active from July15th, 199 to July 15th 2001. This time window is defined by the algorithm itself.
The use of a time window ensures that the pricing algorithm uses only drug records that were in effect at the time. This year-specific drug file is just a subset of the FDB Universe of all possible drugs and is taken from the FDB database with no further process.
MAX Rx Data -- Drug Weights
This is file that is a consolidation of MAX prescription drug claims by NDC that result in a weighting file that keeps count of the number of claims found in the original MAX data for every unique NDC. The weights are actually the number of claims found for any given NDC.
The FDB RAW DRUG PRICE File is then matched to this weighting file by NDC to establish a weighting scheme that is used to help guide the selection of a specific drug if not enough input data are present. This method then offers a way to discriminate between many different FDB drug records that have the same strength for a given drug. Both the FDB RAW DRUG FILE and MAX data are organized by NDC and thus able to be matched at a very specific level.
For example, a 10mg tablet of Zyrtec in the 2001 FDB RAW PRICE FILE is actually associated with 14 different unique NDCs across six different manufacturers and varies in price from $1.86 to $2.63 per tablet. The addition of MAX drug claims as weights can be used to indicate which of the 14 NDC codes is the most commonly form paid for based on the number of claims per NDC. Please not that the actual weighting scheme is a little more complicated than this since these 14 different NDCs would be combined into just one price record for a 10mg tablet of Zyrtec. This process is described in fuller detail under the ROLLUP FILE section.
For this implementation, Medicaid MAX files from 1999 were used as the external weight file, but any source of NDC-based Rx claims would work as well. Use of these weights in the selection of specific drugs is described elsewhere.
Historic Cross Reference File
A special cross reference file has been kept and maintained by CMS that essentially is a cross-reference between LABEL and BRAND Names. This cross-reference file is required since during data collection in the field, drugs are referred to as their simplified BRAND Name instead of the more detailed LABEL Name. This cross reference file is cumulative in nature and forms the bridge between the PME or IDA world which use BRAND NAMES and the PRICE FILE which contain drug prices but are organized by LABEL NAME. This cross-reference file is the mechanism by which a PME drug gets channeled into the proper ROLLUP File entry that contains more detailed information.
This type of crosswalk creates a natural tension between a specific LABEL Name and various drugs that are connected to it. In this sense the Label Name used by the Rollup Files is merely a placeholder since more detailed dosage information is contained within the hierarchical data structures within that record.
FINAL Price File
This file is essentially a copy of the RAW FDB PRICE File to which some matching weights (i.e., claim counts) and x-reference filenames have been attached.
This file contains:
- All active FDB NDCs (and pertinent drug info (e.g., Drug Names, strength + unit, price, etc.).
- Counts of the number of paid Medicaid Rx MAX claims for this NDC.
- Matching cross-reference name for use with IDA (or PME) names.
This file is the simple concatenation of three source files. The FDB Prices (file 1) and MAX Claims data (file 2) are joined by NDC. This file is then joined over the CROSS-REFERENCE File (file 3) by LABEL NAME. It is in this state that the Final Price File is condensed and summarized into ROLL-UP FILES.
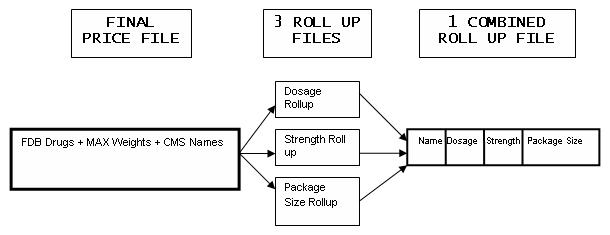
Roll-up Process Files
The ROLLUP process as shown below uses one input file to develop three separate intermediary files which are combined to make a final file.
ROLL-UP FILES
The different combinations of strengths and units and dosage forms for a given drug name can be extensive. The cross tabulation of all drug strengths and units by dosage form into a more manageable file for pricing is done by the pricing algorithm and is called a Roll-up file. There are three forms of these ROLLUP files, each of which is organized by Drug Name. Note that the Drug Name used is the BRAND NAME.
- The first rollup File contains all possible Dosage Forms for the given Drug Name.
- The second Rollup File contains all known Strengths + Units for a given PILL form of a drug.
- The third Rollup File contains all known Strengths + Units for each given PACKAGE SIZE for a given Dosage Form for NON-PILLs.
These three Rollup Files contain a final price that will be associated with a particular drug name, strength + unit, and package size. These three Rollup files are summarized below:
| Dosage Form Rollup | Strength Rollup | Package Size Rollup | |
| Used to Price | Pills and NON-PILLS | PILLS Only | Non-Pills Only |
| # of Dosage Forms | 13 | 2 (PILLS & PATCHES) | 11 |
| # of Package Sizes | n/a | n/a | 3 |
| # of Strengths and Units | n/a | 10 | 3 |
The Rollup files are created by the algorithm and are the foundation used for drug prices. It is very important to note that these summary files that are not NDC-based and that the very act of creating a Rollup File eliminates all NDC-based differences.
How ROLL-UP Files Work
The function of the rollup files is to contain all the Strength + Unit variations for a particular Drug Name. This information is kept in the three types of Rollup Files with only two of the three files being used to actually price a drug. The Dosage Rollup File is not used to price a drug and is instead just used as a reference.
The Strength and Package Size Roll-up Files contain hierarchical data structures that provide places for the different Strength + Unit information to be kept. These structures are searched during the Matching process to locate the price for an input drug record.
What follows are brief descriptions of these files.
Dosage ROLLUP File
The DOSAGE ROLLUP FILE simply lists all the dosage forms available for a particular drug name. As is shown in the following table, approximately 70.7% of all the drugs in the 2001 IDA File have just a single dosage form and 99% of the Drugs have four or fewer dosage forms.
| DOSAGE FORM ROLLUP FILE SUMMARY | ||||
| Dosage Forms | Freq | Percent | Cumulative Frequency | Cumulative Percent |
| 1 | 18410 | 70.68 | 18410 | 70.68 |
| 2 | 4747 | 18.22 | 23157 | 88.90 |
| 3 | 2298 | 8.82 | 25455 | 97.73 |
| 4 | 400 | 1.54 | 25855 | 99.26 |
| 5 | 132 | 0.51 | 25987 | 99.77 |
| 6 | 41 | 0.16 | 26028 | 99.93 |
| 7 | 13 | 0.05 | 26041 | 99.98 |
| 8 | 5 | 0.02 | 26046 | 100.00 |
| 10 | 1 | 0.00 | 26047 | 100.00 |
Strength ROLL-UP File
The STRENGTH ROLLUP FILE is used to price PILLS only and contains up to 10 unique strength & unit combinations for a given Drug Name. This file contains all possible different strengths for PILLS and PATCHES which are kept in two distinct piles. Distributions of the PILLS contained in this Rollup file show that a significant portion of the drugs (27%) do not any strength associated with them. This is not a data anomaly and instead reflects things like multi-vitamins and mineral replacements where strength has no particular meaning.
Of all the FDB Drug Names in the Rollup File with no strengths present, further analysis uncovered that 92% were OTC and 8.2% were LEGEND. And of the Legend Drug Names that had no FDB strengths, approximately 66% of them are for Cough and Cold (29.2%) and Vitamins (24.5%) and Herbals (12.9%). Approximately 54% of the records in the Strength Rollup File have one unique strength and almost 70% have three or fewer.
PILLS:
| Number of Unique Strengths | Freq | Percent | Cumulative Frequency | Cumulative Percent |
| 0 | 2232 | 27.49 | 2232 | 27.49 |
| 1 | 4396 | 54.14 | 6628 | 81.64 |
| 2 | 801 | 9.87 | 7429 | 91.50 |
| 3 | 381 | 4.69 | 7810 | 96.19 |
| 4 | 152 | 1.87 | 7962 | 98.07 |
| 5 | 69 | 0.85 | 8031 | 98.92 |
| 6 | 43 | 0.53 | 8074 | 99.45 |
| 7 | 19 | 0.23 | 8093 | 99.68 |
| 8 | 12 | 0.15 | 8105 | 99.83 |
| 9 | 4 | 0.05 | 8109 | 99.88 |
| 10 | 10 | 0.12 | 8119 | 100.00 |
Drugs whose Dosage Form is a Patch show a similar distribution:
PATCHES:
| Number of Unique Strengths | Freq | Percent | Cumulative Frequency | Cumulative Percent |
| 1 | 36 | 56.25 | 36 | 56.25 |
| 2 | 8 | 12.50 | 44 | 68.75 |
| 3 | 9 | 14.06 | 53 | 82.81 |
| 4 | 5 | 7.81 | 58 | 90.63 |
| 5 | 5 | 7.81 | 63 | 98.44 |
| 6 | 1 | 1.56 | 64 | 100.00 |
PACKAGE ROLL- UP File
The PACKAGE ROLL-UP File is used only or NON-PILLS and contains up to 11 dosage forms for a given Drug Name and for each dosage form, there can be up to three package sizes and, for each unique package size there can be up to three strengths. This makes for a complex file structure to easily summarize, but a distribution of the number of different Package Sizes per Drug Name shows that 63% of all Drug Names contain only one package size and that 97.8% of all Drug names contain three or fewer Package Sizes. Within these package sizes, there quite often are multiple strengths (data not shown).
| Number of Unique Pkg Sizes | Freq | Percent | Cumulative Frequency | Cumulative Percent |
| 1 | 11963 | 63.02 | 11963 | 63.02 |
| 2 | 4371 | 23.02 | 16334 | 86.04 |
| 3 | 2231 | 11.75 | 18565 | 97.79 |
| 4 | 298 | 1.57 | 18863 | 99.36 |
| 5 | 84 | 0.44 | 18947 | 99.81 |
| 6 | 26 | 0.14 | 18973 | 99.94 |
| 7 | 8 | 0.04 | 18981 | 99.98 |
| 8 | 2 | 0.01 | 18983 | 99.99 |
| 9 | 1 | 0.01 | 18984 | 100.00 |
| note bene: It is important to note that the ROLLUP Files contain summaries of the constituent FDB Drug records and while data anomalies do exist in the source FDB records, if an input drug does not involve these drugs, then many of the anomalies are a moot point. These types of drugs are overwhelmingly OTC drugs that contain no strengths. | ||||
FINAL COMBINED ROLL- UP File
This is the file that is used to price all input drugs. It is the simple concatenation of the three individual rollup files by Drug Name and so offers all the possible information for a given Drug in just one file but with three different sections. This creates a very wide file (over 1,200 variables) needless to say. These various sections are searched by the algorithm during the Matching Process.
Individual Drug Prices a slight misnomer
Traditionally, Drug Prices are associated with individual drugs via the unique code that identifies a drug, its manufacturer and strength, form, and packaging. This unique 11 or 13-digit code is known as an NDC. Drug prices are thus connected to NDCs and not a drug in general. It is the price of the individual NDC that a payor reimburses. There are approximately 13 gazillion of them, needless to say.
The pricing algorithm, as-is, does not take this approach of determining a price by an individual NDC. The process of rolling up really refers to collapsing many individual NDCs that can represent different Dosage Forms, Strengths + Units into a larger record identified by a Drug Name alone. Individual Strengths + Units for these drug names are safely contained in a hierarchical data structure within the record but it means that the individual prices for drugs of the same Dosage Form, Strength and Unit are thus pooled into a common data structure and their price individuality thus lost.
A Drug Price is an Average Weighted Price
The way this data processing dilemma is resolved is to take a weighted average of all the components of all individual drug records that make up the unique Strength + Unit combination. This means that drugs with different NDCs but identical Drug Names (e.g., THEOPHYLLINE) and Strengths + Units are collapsed into a common record, and their individual price is added into a collective Total Price bucket along with Total Unit bucket. These prices and units are weighted by the number of Rx claims (if there are any) for a specific NDC. Constituent Drug records that have no Rx claims are assigned a weight of 1.
This sounds more complicated than it actually is and is best illustrated as follows:
When this Drug Name is finished being rolled up the two buckets are used to develop the final price. Stated as a formula, it would look like this:
Average Weighted Drug Price = Total Accumulated Price / Total Accumulated Units
Note that depending on the degree of variation in individual NDC prices, the average price can be different than any individual NDC that contributed to the average price.
So to reiterate, the drug price contained within the Rollup Files is not an AWP but instead is more technically stated an average weighted AWP of the drugs with the same name, dosage, strength and unit and weighted by the number Rx claims for the NDC. This process weights the overall price towards those NDCs that contribute most to the Rx claims.
This condensation of many NDCs into a single ROLLUP FILE representative drug is also the reason why individual NDCs cannot be easily associated with input drug records.
RECORD MATCHING
The process of assigning a price to an input drug record is then a matter of matching the input drug name to the CMS-based Drug name found in the Rollup File. Once this match is made, then the embedded data structures are searched to locate entries that match the input drugs records strength and units. Upon the discovery of a successful match, the price associated with that entry is used.
The matching process may not work smoothly however due to the contents of the input drug record. If the input drug records associated strength or units do not match those contained within the Rollup Files data structures, the algorithm then starts a process of making best guesses based on the information available for that which is known about the drug name.
Essentially for DOSAGE FORMS, the input Dosage Form is verified against all known FDB Dosage Forms for the Specific Drug name. This check is made for both PILLS and NON-PILLS.
For STRENGTH, input STRENGTH and UNITS are made against all known FDB Strengths and Units for the Specific Drug Name. First verifications are made against both Strength and Unit, then Strength Alone, and finally Units alone. Matches made with any of the three choices use the matched values for:
- OTC Status.
- Therapeutic Code.
- Price.
- STRENGTH as text.
- DOSAGE as text and as Code.
This check is made for PILLS only.
For PACKAGE SIZE, if there is not a valid Dosage Form then one is randomly selected based upon available input Amount or Units information. Once Dosage Form is established, the arrays of Package Sizes (up to three) are then searched for entries that match that of the input record. Package Size arrays are then searched for Amount + Unit, just Amount, or finally just Unit depending what data is available. Upon a match to a package size, a random strength is selected from the available strengths for the package size. Values for all applicable variables are used from the match record.
THE GENERATE ROUTINE
The algorithms logic for making matches is based on successively broader generalizations. In the case of Pills, Strength + Units are considered, then failing that, just Strength alone, and then finally by Unit alone. NON-PILLS are similar. If these increasingly broad hierarchical searches for matches still result in no match, or if the input Dosage Form is noted as being Unknown, then a special flag is set. This flag then instructs the algorithm to generate a values for the input drug. The logic flow for input records is:
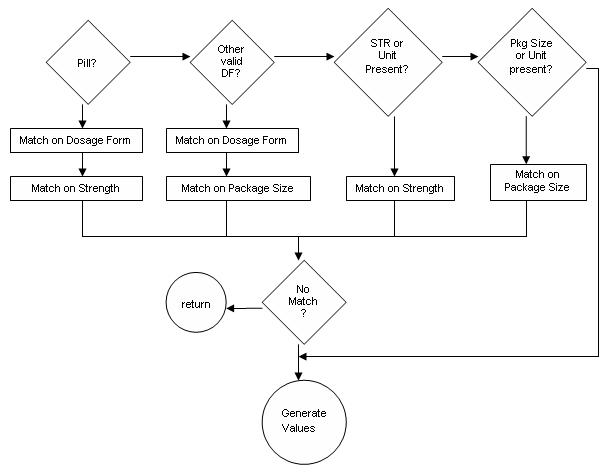
The actual Generate Routine simply calls the appropriate Match Routines for the dosage form in question and lets them to the final reassignment:
The values in any of the match routines is selected based upon the most commonly found examples of the drug as determined (or weighted) by the external Rx Claims. The intent of using this file is to establish a guide to select values that reflect those most commonly encountered in the real world as exemplified by this file (in this case MAX files).
The results of these matches determinations can result in the assignment of values that are different than the input record as is discussed in the next section.
IMPUTATION/RE-ASSIGNMENT
A drug record, upon processing within the algorithm, works similarly for PILLS and NON-PILLS but via different routes within the program and with different Rollup Files. For all drugs a match is made by the drug name initially and then upon a successful match by name, drugs are next processed by the other variables that are applicable for there type:
- Strength and Unit for PILLS; and
- Package Size and Unit for NON-PILLS.
The specific values of these variables are compared to those collected in the appropriate ROLLUP FILE. If exact matches are found, then a price is assigned. This is all done via the Record Match process described previously.
If, however, an exact match is not found, then a series of decisions are made on part of the algorithm to determine values for the non-matching entries. The new values thus determined may be made for any of the pertinent input variables of Dosage Form, Strength and Unit, or Package Size and Unit. Since this reassignment is dynamic, input drug information can change in the following ways:
- Drugs that come in one form may turn into another form (e.g.,Pills into Liquids) based upon.
- Strengths and Units may be reassigned.
- Package Size and Unit may be reassigned.
- Strengths and Units and Package Size may all be reassigned.
This reassignment process is synonymously referred to as imputation. For purposes of this document there will be a formal distinction between the two terms and will not be treated synonymously:
- Imputation will refer to the creation of values where none existed previously.
- Reassignment will refer to replacement of values for various fields.
This allows for distinctions where there is no data (and thus imputation) and those where the supplied data was not considered good although it was provided. These are two different ways of describing the data quality of the input file.
This algorithmic ability to re-assign pertinent values based upon information contained within the Roll-Up File data structures really reflects the degree of discordance between the input variables and that of the FDB universe which the algorithm considers as its gold standard. Re-assigned and imputed values are kept in separate variables and so do not overwrite the original values. It is for this reason that levels of reassignment may be determined in the final processed file.
The presence or non-presence of imputation or re-assignment is itself not an inherently bad thing. The imputation and replacement of values for those that are missing, indeed, can be considered a good way of using data that normally would be not available. Excessive levels of missing data can be a sign of larger data collection or processing problems, however. Similarly, large amounts of re-assignment on the part of the algorithm can signal data collection or data entry problems. Levels of imputed (or missing) and re-assigned values are found in the second section.
PRICING INDIVIDUAL AND EVENT PRICE
The pricing of a drug is the use of the price that is associated with a specific Drug Name and associated values for PILLs or NON-PILLS in one of the ROLLUP Files. As mentioned in the previous ROLLUP Section, this price is not an AWP which can be connected with an individual NDC. The rollup Files really contain Average weighted AWPs. There and two prices that are determined in the final processed file. The first is the unit price for the drug and the second is the event price which is the product of the unit price and the number of units used:
Event Price = Unit Price * Number of units
NON-PRICED RECORDS
On occasion, individual input drug records are not priced. This can be due to several factors, the largest of which is that of OTC drugs which the algorithm excludes from pricing. Other reasons for non-pricing include another algorithmic-based rule of not pricing NON-PILLS with quantities less than five (!), and no pricing information available from the root FDB records. Overall, these are a small part of the successfully processed records.
PROCESSING EXCEPTIONS
Processing exceptions are really those input records whose Drug Names cannot be found in the ROLLUP FILES. These are placed in a separate file so they may be researched and resolved. In the case of the IDA Files, 97% of these bad names are for OTC drugs. Early runs of the implementation uncovered a small number of input LEGEND names that were simply Generic Names. Once these names were converted to brand names, these problems were resolved as far as the very small number of generic names suggests that not many of these drug name are being captured in the data collection process.
The final arbiter of cross-walking input drug names into ROLLup File Drug Name equivalents (aka the CMS Cross-reference File) treats generic Drug Names in the same manner.
SUMMARY
The Pricing algorithm is actually a collection of individual functions that collectively are used to assign a price to an input Drug Name along with Strength and Units for PILLS and PACKAGE SIZE and PKG UNIT for NON-PILLS. These functions include:
- Creation of three separate ROLLUP FILES from a single FDB Price File. These three files form the basis of assigning a price.
- The inclusion of an external drug-based utilization file that is used as a gold standard to resolve which particular combination of strength and units (and/or package size and Unit) to use in those instances where input values do not coincide with values contained in the Rollup File.
- Actual matching input drug names and associated values to the appropriate ROLLUP File.
- Outputting drug names that do not match.
Actual performance of the algorithm with use of the IDA files will be discussed next.
PRICING ALGORITHM RESULTS
The Pricing Algorithm when applied to the IDA data yields priced IDA records. These priced records can be the result of use of the original information as-is or as the result of re-assignment or imputation. The degree of these last two conditions offers some insight into the data quality of the input records. In an ideal world, all records would be used exactly as-is with no reassignment or imputation. Data in the real world, however, is rarely so clean.
Presentation of statistics is complicated by the numerous ways that a denominator can be defined. The denominator of total records in this case can be the entire IDA file, or some subset within it. Because the Pricing Algorithm works with pricing only LEGEND/Rx records, that will be default denominator. There are other times when the entire file needs to be considered as the denominator. The choice of denominator can dramatically changed the apparent effect of the statistic and so in cases where percentages are presented, the denominator will be shown as well.
As a reference, the raw IDA file and final processed IDA file is comprised of the following strata:
| Record Type | RAW IDA FILE | Processed IDA File | Comments |
| Legend | 65,726 (66.9%) | 62,889 (64.0%) | |
| OTC | 26,778 (27.3%) | 25,232 (25.7%) | |
| Both | 5,712 (5.8%) | ||
| -blank- | 1,933 (2.0%) | Unassigned | |
| 8,162 (8.3%) | Bad Names* | ||
| Total Records | 98,216 (100%) | 98,216 | |
| * Kept in separate file. | |||
During the processing, a number of things happen and the results presented above are used to show the results of this processing. Ideally, the results in the Unassigned and Bad Names should have no numbers indicating no problems. These results nicely illustrate some of the IDA and Algorithm peculiarities and so will be discussed first.
UNASSIGNED RECORD TYPES
The Pricing Algorithm itself assigns all drugs a status of LEGEND or OTC as a matter of course during processing. This designation is determined by the FDB record that an input Drug Name is matched up with. There is a particular instance when the source FDB records do not have strengths associated with them. This lack of strength information results in a Rollup File record with no reported strengths and this results in a unmatched input Drug Record.
These unassigned records are disproportional across PILLS and NONPILLS and are split out thus:
PILLS: 5% of Unassigned Records
- All are due to the source FDB records having no strength listed for the LEGEND version of the Drug Names.
- These PILLS are further divided into 99.2% being OTC and largely in the form of vitamins.
NON-PILLS: 95% of Unassigned Records
- 29.2% of these records had no strength listed and hence were imputed.
- 70.8% of these records had their strength re-assigned based on available FDB information.
NOTE: there is an apparent bug in the code involving the assignment of LEGEND/OTC codes for NON-PILLS that have multiple strengths within multiple package sizes. The nature of the bug involves re-assignment where the results of the random selection chooses an array element that is improperly selected LEGEND/OTC and Therapeutic arrays. This affects 93% of the NON-PILL unassigned records.
The solution to the bug has not been implemented.
BAD NAMES
Approximately 8% of the input Drug Names were not able to be matched to the existing universe of FDB names. The split between Legend and OTC Drug names is 61% vs 39%. Of the LEGEND drugs, the primary reason for non-matching is due to the non-presence of a matching CMS Cross Walk File entry.
This Master File contains a historical record of FDB names and their standardized Name for this processing. Because the list was built for community-based drugs, the nature of the records in the BAD NAME File are those drugs used in the NH but not found in the community. Addition of these Drug Names to the file results in successful matches and subsequent pricing.
UNPRICED RECORDS
While the function of the pricing algorithm is to price input drug records, there are instances where prices are not assigned. This happens at a low level overall, (~2%) and when looked at in detail, is not common across all records and instead concentrated in a few algorithmic details.
PILLS: These are all instances where there was a match to a Rollup File entry, however, the matched entry had a price of 0.00.
PATCHES: Here a bug was discovered in the original code involving an incorrect method of looking at the possible ranges of package sizes. This resulted in 100% rejection of pricing for this particular dosage form. Once corrected, a small percentage were priced but the remaining records were still outside the range of acceptable package sizes. This circumstance would still exist in the community-version.
NON-PILLS: There is a hard-coded restriction within the original pricing algorithm against pricing records that have five or fewer units. 95% of the NON-PILL records are not priced for this reason. The remaining are due to matching Rollup File records having a price of 0.00.
NOTES
-
This effort was undertaken in cooperation with CMS.
-
Simoni-Wastila L, Shaffer T, Stuart B. National Estimates of Prescription Drug Utilization and Expenditures in Long-Term Care Facilities. October 25, 2006. [http://aspe.hhs.gov/daltcp/reports/2006/pdnatest.htm].
-
Simoni-Wastila L, Stuart B, Shaffer T. Over-the-Counter drug use by Medicare beneficiaries in nursing homes: implications for practice and policy. Journal of the American Geriatrics Society. 2006;54:1543-1549. Available online August 3, 2006 (http://www.blackwell-synergy.com/doi/abs/10.1111/j.1532-5415.206.00870).