
U.S. Department of Health and Human Services
Making the "Minimum Data Set" Compliant with Health Information Technology Standards
John Carter, Jonathan Evans, Mark Tuttle, Tony WeidaApelon, Inc.
Thomas WhiteNY State Office of Mental Health
Jennie Harvell and Samuel ShipleyUS Department of Health and Human Services
July 5, 2006
This report was prepared under contract between the U.S. Department of Health and Human Services, Office of the Assistant Secretary for Planning and Evaluation, Office of Disability, Aging and Long-Term Care Policy and Apelon, Inc.. For additional information about this subject, you can visit the DALTCP home page at http://aspe.hhs.gov/_/office_specific/daltcp.cfm or contact the ASPE Project Officer, Jennie Harvell, at HHS/ASPE/DALTCP, Room 424E, H.H. Humphrey Building, 200 Independence Avenue, S.W., Washington, D.C. 20201. Her e-mail address is: Jennie.Harvell@hhs.gov.
The opinions and views expressed in this report are those of the authors. They do not necessarily reflect the views of the Department of Health and Human Services, the contractor or any other funding organization.
TABLE OF CONTENTS
Health and Long-Term Care Costs
Quality
Data Comparability
Standardizing Federal Assessment Instrument Forms
Health Information Technology
USING HEALTH INFORMATION TECHNOLOGY STANDARDS TO STANDARDIZE THE MDS
MDS and Standard Vocabularies
Methods
Findings
Messaging
Discussion
Conclusion
Standardization of Assessment Instruments
Related Technical and Policy Infrastructure Issues
ATTACHMENTS
ATTACHMENT A: BIPA, Sec. 545. Development of Patient Assessment Instruments [PDF version]
ATTACHMENT B: Encoding Nursing Home Resident MDS Observation and Assessment Data Article [PDF version]
ATTACHMENT C: MDS Term Matches and Reviewer Feedback [PDF version]
ATTACHMENT D: Additional Item Matches for Sampled MDSv3 [PDF version]
ATTACHMENT E: NLM/UMLS to Maintain Links between LOINC coded Assessment Question and Answers and Codeable Vocabularies -- An Alternative [PDF version]
ATTACHMENT F: Specific Vocabulary Codes [PDF version] [Excel version]
LIST OF FIGURES AND TABLES
FIGURE 1: Section of MDSv2 Form with Highlighted Text Showing Content Not Included in Lexical Analysis
FIGURE 2: MDSv2 Example Without Inherent Content
FIGURE 3: Sample Mapping of MDS Questions and Answers for Two Items to SNOMED Codes, Showing Need for Mappings at Question, Answer, and Question+Answer Levels
FIGURE 4: Sample HL7 Fragments for Messaging Survey Data Results
TABLE 1: Representing a Sample of MDSv2 Using CHI-Recommended Vocabularies
TABLE 2: CHI Terminology Groupings and Examples of Correlating Items from MDSv2
TABLE 3: MDSv2 Sections and Emerging MDSv3 Domains, Source Sections, and Searched Terminologies
TABLE 4: TermWorks Results for adequate vision and With the Word vision Made Mandatory
TABLE 5: Matches Found for MDSv2 Section G1B: ADL Support Provided
TABLE 6: Matched Terms and Reviewer Feedback for MDSv2 Section HeadingG1B ADL Support Provided
EXECUTIVE SUMMARY
Introduction
Health Information Technology (HIT) is helping to improve the quality and continuity of healthcare and reduce unnecessary care costs. The President issued an Executive Order for the development and nationwide implementation of an interoperable health information technology infrastructure to improve the quality and efficiency of health care.1 The Secretary of the Department of Health and Human Services (HHS) has identified use of HIT as a critical part of plans to transform our healthcare system, modernize the Medicare and Medicaid programs, and advance medical research. The Secretary has committed that HHS will do its part by adopting standards and data-sharing processes for Internet-based applications that will help federal programs like Medicaid and Medicare support the use of digital and interoperable health records that are privacy-protected and secure.2 Private sector leaders convened health information experts and long-term care providers, vendors, and researchers in the first Long-Term Care Health Information Technology Summit. The Summit recommended priority action items to be undertaken by the private and public sectors including adoption of data, content, and messaging standards that support a unified language and promote interoperability and specifically recommended that federally-mandated, standard assessments/data sets must incorporate HIT content and messaging standards.3
To support implementation of the Executive Order for an interoperable HIT infrastructure, and the Secretarys vision of modernized Medicare and Medicaid programs, the Office of the Assistant Secretary for Planning and Evaluation, in collaboration with the Centers for Medicare and Medicaid Services (CMS), sponsored a study to standardize the nursing home Minimum Data Set (MDS). The MDS is one of several patient assessment tools, the use of which is required by the Federal Government as part of reimbursement and regulation. The nursing home MDS, along with other required assessment instruments, is comprised of human-readable question and answer pairs, the responses to which are computer-readable. That is, the MDS is a form that can be completed in a way that produces computer-processible data. This data is submitted to regulatory and reimbursement authorities. Linking MDS with HIT content and messaging standards is one step towards interoperability with other care processes. Federal policy makers could implement this linkage as part of larger efforts to modernize the Medicare and Medicaid programs and transform Americas healthcare systems.
This project undertook three major activities. The first activity involved examining standard vocabularies, including those endorsed through the Consolidated Health Informatics (CHI) Initiative,4 and identifying possible content matches between concepts (elements) in these vocabularies and the items (including both questions and answers) in MDS Version 2 (MDSv2) as well as a sample of MDS Version 3 (MDSv3). MDS experts were asked to review and comment on the identified vocabulary matches. The second major activity explored representing MDSv2 using the Logical Observation Identifiers Names and Codes (LOINC) standard. Clinical LOINC is a database in the public domain maintained by the Regenstrief Institute.5 It contains almost 40,000 records, including items from survey and assessment instruments. The third activity was the construction of sample Health Level Seven Version 2 (HL7v2) messages using MDSv2 content that had been linked with standardized vocabularies. HL7v2 is a messaging standard endorsed by CHI that promotes interoperability between computer systems. HL7v2 messages can use LOINC codes and concepts from standard vocabularies, thus combining the projects activities. These messages permit the electronic exchange of single and multiple standard question-answer pairs, up to and including an entire completed assessment instrument, as well as MDS-derived quality measures.
Results in Brief Standard Content Coverage
We examined the approximately 600 MDSv2 items* (multiple-choice questions and answers) and identified a total of 537 phrases, such as Acute pain and Unpleasant mood in morning for standard vocabulary matching. These phrases were culled from all sections of the MDS, with some items contributing multiple phrases (e.g., a list of patient diseases from item I1) and others contributing none (e.g., social security number and date of birth from Section AA) when standard terminologies were not applicable. Our automated search and initial expert review of CHI-endorsed terminologies yielded a total of 2,064 standard vocabulary concepts that appeared to match MDSv2 items. After initial expert review, 743 of the 2,064 candidate matches (36%) were classified as exact matches of an MDSv2 phrase. These matches covered 250 of 537 phrases (47%). The remaining 1,321 of 2,064 candidate matches (53%) were classified as related, meaning that they were judged to be broader, narrower, or overlapping in meaning compared to the MDS phrase. There were no acceptable standard terminology matches found for 43 of the 537 MDS phrases (8%). Over a three-month period, a panel of MDS experts provided 880 written comments on a total of 245 of the 494 (50%) matched MDS phrases. While expert opinion varied on the degree to which the matched standard terms would support successful interoperation, the matches illustrate how a significant portion of the items in MDSv2 can be represented using terms from standard vocabularies. Table 1, below, summarizes the standard content coverage findings for the MDSv2. Preliminary matching and review of a sample of MDSv3 phrases suggested that the yield for MDSv3 would be similar to that for MDSv2.
Additional matches and improved precision will be achievable as the vocabulary and standards communities develop rules for combining vocabulary concepts into complex statements (e.g., the activities of HL7s TermInfo initiative show great promise in achieving this goal).
| TABLE 1: Representing a Sample of MDSv2 Using CHI-Recommended Vocabularies | |||
| Exact Match | No Match | Broader, Narrower, or Partial Match | |
| MDS Question and Answer PhrasesN = 537 | 250(47%) | 43(8%) | 244(45%) |
Clinical LOINC Representation
In parallel with the terminology matching, this project worked directly with the LOINC Committee to develop an enhanced LOINC format designed to support the computer-based exchange and re-use of interoperable survey instruments, such as the MDS. Since each MDS item is translated verbatim into the LOINC format, it is possible to reconstruct paper MDS from the LOINC representation. By unambiguously dividing MDS into items -- units -- LOINC provides a useful, near-term way of standardizing MDS. The entire text of the MDSv2 form was encoded in this format.
Construction of HL7 Messages
Together, the standard terminology matching and the MDS representation in Clinical LOINC enable the creation and transmission of useful HL7v2 messages with re-usable content. The HL7v2 standard serves as a wrapper for computer-based data sharing. The information wrapped includes MDS text segments placed in the LOINC representation and any codes identifying CHI-recommended vocabulary. HL7v2 messaging connects a wide range of computer systems in a variety of healthcare settings.
We demonstrated how three different types of HL7 messages could be constructed using a sample of MDS question and answer pairs that had been linked with codeable vocabularies and placed in an HL7 message format. We used the HL7v2 Observation/ Result (OBX) segment, in particular the OBX-3 and OBX-5 message fields, to represent the assessment results. The HL7 message types that were constructed would support the automatic generation and electronic exchange and re-use of:
- A single MDS question and answer pair.
- Multiple MDS question and answer pairs.
- Algorithmic/computer-generated computation of Quality Measures using existing and future formulas from a set of standard MDS items.
Following a similar process, the entire MDS form could be exchanged using HL7 messaging.
Discussion
This project has revealed both the potential benefits and the challenges of leveraging HIT standards in the preparation and exchange of complex survey forms such as the MDSv2. On the one hand, most MDS items are easily related to standard vocabulary concepts. On the other hand, experts consulted in this project disagreed on the current ability of these vocabulary standards to provide true interoperation by meaning, such as might be required to auto-populate the MDS from an electronic medical record or to easily compare MDS and MDS results with other surveys and survey results. Important vocabulary challenges identified include:
- accommodating the complexity and idiosyncrasies of patient assessment instruments;
- bridging coverage gaps in standard vocabularies; and
- resolving uncertainty regarding the reproducible combining of standardized vocabulary terms into compound terms intended to match certain MDS items.
Similarly, Clinical LOINC and HL7v2 provide a straightforward and proven path for standardizing question and answer pairs as found in the MDS that will permit the standards-based exchange and re-use of this content. The computing infrastructure required to exploit this path would become available to nursing homes if the government embeds this approach in future modifications of the MDS. HL7v2 messages using questions and answers coded in Clinical LOINC can be stored in publicly accessible repositories, further enabling their re-use. Increased re-use of these items supports the objective of data comparability across settings.
However, if HHS wished to standardize the exchange of the MDS using CHI-endorsed standards, HHS would need to consider modifying the software CMS makes freely available to providers to transmit the MDS using Clinical LOINC and HL7 messaging. Using HL7v2 messages and Clinical LOINC to transmit MDS content would:
- enable the secure, standards-based transmission of all or parts of the MDS form to payers, regulators, providers, and other entities;
- promote comparability and re-use of question and answer pairs across instruments;
- leverage existing software tools and support the development of new software tools, including those that could:
- identify relationships between data elements, and thus accelerate the re-use of these data elements; and
- provide clinical decision support.
Conclusion and Recommendations
The goals of this study were to make the MDS conformant with CHI-endorsed content and messaging standards, and to produce a policy relevant report that describes the issues with integrating these HIT standards into federally-required patient assessment applications. We now summarize our complete findings and recommendations, noting that some are explained more fully in the body of this report.
While this project has shown that CHI-endorsed standard vocabularies such as SNOMED CT, HL7 and ICD-9-CM nominally contain most (up to 97%) of the concepts needed to standardize the intent of MDSv2 and presumably MDSv3, it is equally clear that standardization leading to semantic interoperability will require significant work and an ongoing collaboration between HHS, the developers of patient assessment forms (in this case CMS, the owner of the MDS), and the standards development community. To promote the integration of HIT standards into federally-required patient assessment tools such as the MDS, we advance the following recommendations pertaining to: (i) standardization (using content and messaging standards) of assessment instruments; and (ii) technical and policy infrastructure issues needed to support widespread deployment and re-use of standardized assessment instruments, in conjunction with existing and emerging HIT standards.
Standardization of Assessment Instruments
The Federal Government could apply current and emergent HIT content and messaging standards to federally-required patient assessment tools. The work undertaken in this project on the MDS gives rise to many recommendations that could be considered in the pursuit of this goal. Specifically, the Federal Government could:
- Create standard, computer-processible versions of patient assessment tools (e.g., the MDS) based on the Clinical LOINC format developed in this project.
- Create and freely distribute software that supports use of LOINC-formatted, federally-required patient assessment tools (such as the MDS) to enable the electronic transmission of needed patient assessment data in standard form by standard means (i.e., in the case of the MDS such software would be a successor to the Resident Assessment Validation and Entry application.
- Include in the freely-available software described above, a link to the usefully related CHI terminology mappings (e.g., identified through this project) so that the developer of the patient assessment forms (in this case CMS) communicates to the public and private sectors the matching standardized terms that it believes are usefully related as such terms are identified.
- Distribute this linked software (i.e., software supporting LOINC-formatting, linked with related standardized terms) as a test set to foster development of standards-based tools and processes within the applicable provider (e.g., nursing home) and software-development communities.
- Equip developers of assessment/survey forms (e.g. refined versions of the OASIS, IRF-PAI, and other assessments required in the Deficit Reduction Act) with: (i) tools to place needed patient assessment data into a LOINC format; and (ii) convenient (e.g., Web-based) access to standard vocabularies to promote harmonization whenever possible.
- Support initial testing of such applications to validate, for example, required exchange of:
- the entire assessment forms and results, as well as
- multiple question-answer pairs needed to support
- payment, and
- quality measure/outcome reporting.
- Support pilot projects to evaluate and iteratively deploy increasingly standards-enabled assessment applications. For example, the public and private sectors could support the development of initial coding assistant applications that:
- accept standard terms that describe the patient conditions, demographics, etc.,
- suggest potential assessment results based on these descriptions,
- calculate quality/outcome measures based on responses, and/or
- collect feedback regarding utility of assistant functions.
- Engage the CHI-recommended vocabulary developers to identify and fill gaps in the content and utilization of standard vocabularies.
- Replicate the process of integrating content and messaging standards for other federally-required assessment tools and government survey instruments.
- Create and execute a multi-stakeholder governance process, based on continuous improvement principles, for the standards-enabled patient assessment tools, that will:
- Oversee and align interoperable assessment instrument construction, maintenance and deployment;
- Collaborate with standards development organizations;
- Promote public-private partnerships to leverage the cost-reduction and quality-improvement potential of assessment instruments; and
- Measure and report progress toward assessment instrument compliance with Presidential, HHS and Congressional mandates.
In the near term, we recommend the Federal Government consider deploying a process for integrating HIT content and messaging standards with the emerging MDSv3 and the assessments required in Section 5008 of the Deficit Reduction Act (DRA) as follows:
- Represent MDSv3/DRA content in LOINC using lessons learned from the LOINC representation of MDSv2; and
- Re-use the applicable MDSv2 content matches in the emerging MDSv3/DRA content, and conduct additional content matching, including needed subject matter expert review, for the MDSv3/DRA items.
Regarding item re-use across patient assessment instruments (e.g., OASIS and IRF-PAI), and best practices as new health and functional data collection tools are developed, we believe the following activities will facilitate standardization:
- Consider the development of standard information models (e.g., for pain scales, used to enhance utility of standard terminologies). Focus, initially, on items that may be re-used in other patient assessment instruments.
- Search question-answer repositories for any re-usable items.
- Consider the appropriate distribution of content between the question and answer when specifying needed content, and publish any lessons learned.
- Place needed questions and answers into a LOINC format and submit to Clinical LOINC for coding.
- Search HIT vocabularies to identify coded content (e.g., a SNOMED-CT concept) that is usefully related to the items being measured and have possible matches reviewed, as needed, by subject matter experts.
- Work with standard development organizations to address identified gaps in HIT standards.
- Create a freely and publicly available database that supports the standardized exchange of needed content using HLv2+ messaging, Clinical LOINC, and coded content (when available).
Related Technical and Policy Infrastructure Issues
More generally, given the increasing departmental and government focus on the Federal Health Architecture (FHA), the FHA could examine existing and emerging federal mechanisms to implement and maintain HIT content and messaging standards within the federal healthcare enterprise (e.g., at HHS/National Cancer Institute (NCI), Department of Veterans Affairs (VA), etc.). Such analyses could identify commonalities and differences in these processes and encourage the use of processes that maximally support interoperable health information exchange. For example, an issue identified in this study was the need to maintain links between codeable content and LOINC coded questions and answers to support interoperable exchange and re-use of information. Alternative approaches for maintaining these needed linkages that merit further consideration include the feasibility of using the National Library of Medicines (NLM) Unified Medical Language System (UMLS) to maintain and make available links between codeable content and Clinical LOINC. Other FHA partners have also been leaders on several wide-ranging HIT standardization projects has been demonstrated by some FHA partners, including the NCI Center for Bioinformatics in its caBIO, caDSR and caBIG initiatives. The FHA could consider these and other initiatives to identify mechanisms that could be re-used to support implementation of interoperable health information exchange.
This project has also highlighted several additional technical and policy issues that would benefit from review by the FHA partners (e.g., HHS, VA, and Department of Defense). For example the FHA could consider alternative methods of deploying and maintaining HIT standards and identify the methods that could be re-used by Federal Partners to maximize efficient interoperable health information exchange. Issues that the FHA could consider include:
- How will the FHA evaluate the presence of gaps and redundancies in CHI-approved HIT standards (based on this experience with standardizing the MDS and the experiences of other FHA partners)? Will the recently awarded Health Information Technology Standards Panel (HITSP) contract be used to address these issues across the Federal healthcare enterprise?
- Should links between federally-required patient assessment content (such as the MDS) and standard content in the NLM UMLS be maintained? If so, what process(es) will be used and who will maintain these links?
- How do FHA partners combine codeable content (i.e., using post-coordination (combined usage) of multiple standard vocabulary elements)? How are standard development organizations (e.g., the HL7 TermInfo effort) addressing issues related to post-coordination?
- What mechanisms support re-use of codeable content by and across FHA partners (e.g., how are definitions of codeable content maintained, and made transparent and re-usable)?
- How do FHA partners exchange and re-use codeable content using standardized messages?
- How do FHA partners integrate HIT content and messaging standards into various patient assessment and survey instruments?
- What role(s) could the NLMs UMLS serve in addressing these and related issues?
In summary, this study has identified:
- a feasible method to integrate HIT content and messaging standards into federally-required patient assessment tools such as the MDS;
- steps that the Federal Government could use to integrate HIT content and messaging standards into patient assessment tools; and
- cross-cutting technical and policy issues that would enhance the infrastructure needed to exchange and re-use information.
Implementation of these recommendations would promote the use of interoperable HIT applications that could improve caregiving and increase administrative efficiencies, (e.g., improving quality monitoring, supporting data re-use, etc.). In addition, this study highlights several issues that the FHA could considered as a part of a larger Continuous Quality Improvement that, if implemented, would efficiently promote data standardization, exchange, and re-use.
BACKGROUND
Health and Long-Term Care Costs
The U.S. healthcare system represents one of the fastest-growing sectors of the economy. In 2004, national health expenditures in the U.S. were approximately $1.8 trillion, or about 15.8% of the gross domestic product (GDP).6 Centers for Medicare and Medicaid Services (CMS) estimates that, by 2013, U.S. national health expenditures will reach approximately $3.4 trillion and account for 18.8% of the GDP. In 2002, Medicare and Medicaid expenditures accounted for more than 25% of total personal healthcare expenditures, second only to the percentage of expenditures attributed to private health insurance.7 The dominance of the Medicare and Medicaid programs as payers of health services is even more pronounced in long-term care (LTC); in 2003, these two programs paid for 65% of formal LTC services delivered in the U.S.8
In testimony before the House Energy and Commerce Committee, the Government Accountability Office (GAO) concluded that the aging of the baby boom generation will lead to a sharp growth in federal entitlement spending that, absent meaningful reforms, will represent an unsustainable burden on future generations [and] is virtually certain to overwhelm the rest of the federal budget.9
Health Information Technology (HIT) is increasingly recognized as one of the tools that can be deployed to help control healthcare spending and transform the Medicare and Medicaid programs.
Quality
Despite the significant investment in healthcare, the Institute of Medicine (IoM) has estimated that between 44,000 and 98,000 people die each year from medical errors, including preventable medication errors.10 These errors not only highlight opportunities for quality improvement but also opportunities to reduce the healthcare costs that arise from them. A recent study reported that 80% of errors were caused by miscommunication (e.g., missed communication between physicians), incorrect information in medical records, mishandling of patient requests and messages, inaccessible records, mislabeled specimens, misfiled or missing charts, and inadequate reminder systems.11
Healthcare in the U.S. is highly fragmented across payers, providers, and time. This fragmentation is particularly troublesome for the chronically ill and disabled whose health and functional status are characterized by fluctuations in health and increasingly complex conditions, and who are cared for by multiple healthcare specialists and providers. Further, reimbursement complications are encountered when providers are funded through combinations of diverse payer sources ranging from local government, Federal Government, and private sectors (including out-of-pocket payments by patients) to charitable donations. Coleman has authored several papers on the vulnerabilities of the chronically ill elderly as they transition across the healthcare delivery system. In one paper, Coleman observes that patients with complex and continuous needs are seen by multiple healthcare providers within and across multiple sites of care, and are vulnerable to several types of errors given the failure to exchange needed information in a timely and complete way. He states that implementation of technology is central to facilitating the transfer of information across settings, particularly because it has been shown that improved communication between physicians can result in better patient outcomes.12
Quality in long-term care, particularly in nursing homes, has garnered significant public policy attention over the last twenty years. In 1986, the IoM issued a report entitled Improving the Quality of Care in Nursing Homes recommending several steps to improve nursing home quality. The recommendations included the need for standard health and functional status assessments of nursing home residents to support care planning, monitor quality of care and outcomes, and support the development of case-mix adjusted payment methods.13
Statutory nursing home reform requirements were enacted through the Omnibus Budget Reconciliation Act of 1987 (OBRA 87) and included requirements that Medicare and Medicaid-certified nursing facilities complete a comprehensive, accurate, standardized reproducible assessment of each residents functional capacity and medical problems based on a uniform minimum data set specified by the Secretary.14 OBRA 87 required that a Minimum Data Set (MDS) be used for care planning. In 1990, the Department of Health and Human Services (HHS) published the first version of the MDS (MDSv1) including, as required by statute, the core data elements, common definitions, and guidelines for its use. In 1995, HHS required that nursing home providers use the MDSv2. Since then, the uses of the MDS have expanded. It is the main data source for Medicare skilled nursing facility payment (and in some instances Medicaid nursing facility payment) and the foundation for the construction of quality measures and quality indicators in these settings.
Despite the promulgation of regulations to implement the nursing home reform requirements of OBRA 87, nursing home quality problems persist. In 1998, based on reports in the Los Angeles Times that many Californian nursing home residents were dying from preventable conditions, the GAO concluded that unacceptable care continues to be a problem in many homes.15 The concern of serious quality problems in nursing homes has been echoed in several reports.16
Data Comparability
CMS requires patient health and functional assessment instruments in many settings, including nursing facilities, home health agencies (HHAs) and in-patient rehabilitation facilities (IRFs). The MDS preceded the setting-specific tools now used in HHAs and IRFs to support payment, quality measurement, and care activities. HHAs are required to use the Outcome and Assessment Information Set (OASIS), and IRFs are required to use the IRF Patient Assessment Instrument (IRF-PAI).
While much of the information in the MDS, OASIS, and IRF-PAI is similar, this common information is not directly comparable in terms of content or format. The lack of comparable health and functional status information across settings creates obstacles to caring for often fragile patients. The lack of data comparability prohibits re-use of previously collected data, even if the separate assessments were completed within a relatively short time period of each other. MedPAC reports that in 2002 approximately 30% of Medicare beneficiaries discharged from hospitals go on to receive some type of post-acute care service within one day of hospital discharge, and 4% of these patients use multiple post-acute care providers.17
In response to concerns regarding lack of comparability of data and assessments, in 2000 Congress passed Section 545 of the Benefits Improvement Protection Action (BIPA). BIPA §545(a)(2) requires that the Secretary of HHS submit a report to Congress on the development of standard instruments for the assessment of the health and functional status of patients and design such instruments such that elements that are common may be readily comparable and are statistically compatible (see Attachment A).
In an effort to help frame the response to Congress, the Office of the Assistant Secretary for Planning and Evaluation (ASPE) partnered with CMS and conducted a focused review of the issues that arise from non-comparable data and strategies for achieving comparability. Particular focus was directed towards nursing homes, HHAs, and IRFs, the program objectives for which required data is intended to address, and the solutions that could be applied to make common data elements comparable. Findings from this review show that advances in, and deployment of, health information technology and healthcare terminology standards will be essential for:
- making data that is common across Medicare providers comparable and compatible, and
- improving the quality of healthcare.
Research has found that failure to embed clinical content needed to measure quality and use HIT standards in federally-required assessment forms has limited the development and use of HIT systems that capture and re-use data collected at the point of care.18 In addition, the idiosyncratic and non-comparable content of federally-required patient assessment tools has been found to limit electronic information exchange.19
Policy makers are increasingly interested in comparing costs and outcomes across Medicare post-acute care (PAC) providers, including nursing homes, home health, and in-patient rehabilitation facilities. However, because patient assessment data presently required across these settings is not comparable, such comparisons are not currently feasible. As a result, in 2006, Congress passed the Post-Acute Care Payment Reform Demonstration Program. in section 5008 of the Deficit Reduction Act (DRA). Section 5008 of the DRA requires the Secretary of HHS to establish a demonstration program that provides for the following patient assessments:
- a comprehensive assessment on the date of hospital discharge of individuals needs and diagnostic clinical characteristics for the purpose of determining the appropriate PAC placement;
- a standardized patient assessment across all PAC sites to measure functional status and other factors during treatment and at discharge; and
- an additional comprehensive assessment at the end of the episode of care.
The intent of this provision is that implementation of such assessments would permit comparisons of costs and outcomes across PAC settings and provide necessary information to develop Medicare PAC payment methods that align payments with the cost and outcomes of services provided in these settings.
Standardizing Federal Assessment Instrument Forms
Federally-required assessment forms (e.g., MDS, OASIS, and IRF-PAI) address similar clinical domains (e.g., activities of daily living, pain, cognitive status, etc.) and contain similar data elements. However, the wording and/or placement of similar items (multiple-choice questions and answers), although frequently sharing intent, do not share:
- a similar presentation (e.g., placement, formatting, order) across forms;
- supporting detail (for example, on the forms or in manual instructions) describing the content/intent of each question and answer pair;
- instructions regarding the sources of information that can be used to complete each item; and
- severity/frequency response scales that are comparable across instruments.
According to Survey Theory,20 variables collected via surveys have conceptual, operational, and variable definitions. The conceptual definition specifies which construct is being assessed. The operational definition is typically the wording of the question. The variable definition specifies the data type, validation criteria, and when appropriate, the enumerated list of answer options.
In addition, according to Psychometric Theory,21 the meaning of data collected from survey and assessment instruments is highly dependent upon how the questions are posed, the allowable answer options, and characteristics of the questioner and respondent. Even minor changes in the wording, order, or presentation attributes (such as italics or bolding) of a question can significantly alter how subjects interpret and answer it. Moreover, for a given question, the method used to answer it (e.g., free text, Likert scales, standard gamble) can alter the reference range of the variable. Finally, studies have shown that subjects respond more honestly to stigmatizing questions when they are posed by a computer, rather than a human.
Thus, the meaning of assessment items cannot be determined solely by the text of the question or the text of the answer. Instead, the meaning requires knowledge of both the question and selected answer, and may also require information about the context of the question (e.g., the order within an instrument, and references to recent instructions) and metadata describing who asked the question. Any attempt to link federally-required assessment forms with HIT standards requires consideration of all key attributes that comprise the context and meaning of each assessment item.
Health Information Technology
Standardized health information technology is recognized as a tool that can help improve the efficiency, cost-effectiveness, quality, and safety of healthcare. The scientific evidence of the impact of implementing health information technology is generally limited to selected HIT applications (e.g., computerized physician order entry) in large medical centers (such as the Department of Veterans Affairs (VA) health delivery system, Partners/Brigham and Womens Hospital, the Regenstrief Institute, Intermountain Healthcare, and Kaiser Permanente).22 Economic models suggest, however, that significant benefits will accrue when there is widely interoperable health information exchange (e.g., net savings to the U.S. healthcare delivery systems exceeding $77 billion per year).23
The Commission on Systemic Interoperability recently released a report concluding that the problems of poor quality, medical errors, inefficiencies, and high costs are well addressed by a connected system of healthcare information, one that is interoperable.24 The Commission advanced several recommendations that would collectively create a connected nationwide system of health information. These recommendations state that:
The Secretary of HHS should act with urgency to revise or eliminate regulations that prevent healthcare entities from working together to create and adopt interoperable healthcare information systems, and
HHS should ensure broad acceptance, effective implementation, and ongoing maintenance of a complete set of interoperable, non-overlapping data standards that function to assure data in one part of the health system is, when authorized, available and meaningful across the complete range of clinical, administrative, payment system, public health, and research settings.25
Experts have long recognized the need for and value of standardized content and messaging formats to support electronic health information exchange and re-use (i.e., interoperation). In 2000, the National Center for Vital and Health Statistics (NCVHS), an advisory body to the Secretary of HHS, issued a report recommending that HHS accelerate the development and implementation of a national health information infrastructure. The report discussed the importance of having comparable health information and the role HIT content standards could play in achieving comparability:
Comparability requires that the meaning of data is consistent when shared among different parties. Lack of comparable data can directly impact patient care. A simple example is the use by physical therapists of a pain scale that ranges from 1 to 4, and another used by nurses that ranges from 1 to 10. Obviously, pain designated level 3 carries vastly different meanings to these professionals Standard healthcare vocabularies would assure that data shared across systems are comparable at the most detailed level Further, this lack of standard vocabularies makes it difficult to study best practices and develop clinical decision support.26
In August 2005, over 125 thought leaders and stakeholders were convened by the private sector, and recommended priority action items for the private and public sectors to promote health information technology in LTC. These priorities included the adoption of data content and messaging standards that support a unified language and promote interoperability across care settings and specifically recommended that existing and new federally-required standardized assessments and data sets must incorporate HIT content and messaging standards.27
Health Information Technology Standards and the Consolidated Health Informatics Initiative
In 2001, the Consolidated Health Informatics (CHI) Initiative was launched as part of the Presidents e-Gov initiative. The goal of the CHI Initiative is to adopt standards that enable interoperability across the federal healthcare enterprise. In CHI Phase I, workgroups identified and made recommendations for standards that address federal health information needs in specific domains. Through CHI, 20 standards were endorsed for use in the federal healthcare enterprise. The endorsed standards include standards to support the:
- electronic transmission of clinical content. The endorsed messaging standards included the Health Level Seven Version 2 (HL7v2+) as the standard to send coded clinical information electronically, and
- encoding of clinical content. The endorsed content standards included the Systematized Nomenclature of Medicine Clinical Terms (SNOMED-CT) for nursing content, HL7 vocabulary for demographics, and several standards for medications, including RxNorm.
Reports of all domains examined during CHI Phase I and the domains for which standards were endorsed can be found at: http://www.hhs.gov/healthit/chiinitiative.html. Table 2 provides a summary of the CHI recommendations along with MDS-specific examples and notes.
| TABLE 2: CHI Terminology Groupings & Examples of Correlating Items from MDSv2 | |||
| CHI Category | An Example MDSv2 section is | CHI- recommended terminology & terminology examined in this project | Discussion/Notes |
| Resident Anatomy | J3 pain site (also embedded throughout the MDSv2) | SNOMED-CT | |
| Laboratory Result Names | I2 Infections: does not explicitly reference lab tests, but provides an example where HIT may use them (HIV, Hepatitis, STDs, UTI) | LOINC | Not expected for explicit use in MDS (e.g., a blood sugar reading) |
| Laboratory Result Contents | I2 Infections: does not explicitly reference lab tests, but provides an example where HIT may use them (HIV, Hepatitis, STDs, UTI) | SNOMED-CT | Not expected for explicit use in MDS (e.g., a blood sugar reading of 200) |
| Resident Demographics | - AA, Identification Information (race/ethnicity, gender) -AB Demographics Information (language) | HL7v2.4 | Includes Age, Race/ Ethnicity, Gender; includes Special Populations in the context of medication use |
| Diagnosis/Problem List Entries | I1, I3, Diseases/Other Diagnoses (e.g., asthma, depression, diabetes) | SNOMED-CT (CHI-recommended); ICD-9 (supplemental analysis) | |
| Non-laboratory Interventions and Procedures | Section P: Special treatments and procedures (Occupational Therapy, Physical Therapy, medical or nursing procedures (suctioning, ostomy, dialysis, medical evaluation)) | SNOMED-CT | Actions/Interventions or procedures are not constrained to any single section of the MDS |
| Immunizations | NA | HL7v2.3.1+ | Not explicitly included in the MDS version at the start of this project |
| Units of Measure | Section K6: Parenteral or Enteral Intake (e.g., total calories consumed, and average fluid intake (measured in ccs)) | HL7v2.x+ | Specifically, units used to express a result (e.g., lab result), not units of time (last 7 days). Seldom expected in MDS |
| Laboratory Test Names | NA | LOINC | Not expected for explicit use in MDS (e.g., a blood sugar test) |
| Medications (Clinical Drug) | NA | RxNorm SCD | Not a federally required component of the MDS |
| Drug Classifications | O4: Days received the following medication (e.g., antidepressant, antipsychotic, diuretic) | NDF-RT | Includes Mechanism of Action and Physiologic Effect |
| Drug Dose Form | NA | FDA/CDER tables | Not expected for explicit use in MDS |
| Medication Ingredients | NA | FDA Established Name/UNII Code | Not expected for explicit use in MDS |
| Medication Package | NA | FDA/CDER | Not expected for explicit use in MDS |
| Drug Product | NA | FDA National Drug Codes | Not expected for explicit use in MDS |
| Nursing Terms | Found throughout the MDS. Including Section V, Rap problem area (e.g., falls, communication, psychosocial well-being); J2b.2, Moderate Pain | SNOMED-CT | This is a broad CHI category. Nursing terms such as observations, evaluation, and interventions are found throughout the MDS. |
The CHI Disability Workgroup concluded that no standardized vocabulary provided sufficient coverage for disability terms needed by the Federal Government. On December 9, 2003, the Workgroup presented its findings to the NCVHS Subcommittee on Standards and Security.28 The NCVHS discussion addressed several topics, including:
- the laudable, longer-term objective of developing patient assessment and survey instruments that could be automatically populated by data collected by clinicians and entered at the point of care; and
- a shorter-term strategy to support the sharing of data in the current environment by:
- utilizing standardized terminology when feasible, and
- using HL7 messages to exchange patient assessment/survey information and thus retaining the context of the items which is inherent in the structure of each items question and answer.
- The NCVHS recommended that:
- the content of core terminologies be expanded to include needed terms;
- Logical Observation Identifiers Names and Codes (LOINC) be considered as a mechanism to support messaging while retaining the question-answer format; and
- standardized terminologies be analyzed for coverage of, and linked to, the answers.
Work in CHI continues under Phase II, where domain specific examination for HIT content and messaging is being expanded from Phase I, with the addition of use-case scenarios. Specifically, Phase II looks at the disability domain, focusing on a use-case of MDS/HIT content and messaging standards integration.
HIT Content Standards
While CHI Phase I identified several HIT content standards for use in the federal healthcare enterprise, implementation of standardized vocabularies will require that several issues are addressed. In 1998, Cimino articulated several principles for re-usable and shareable vocabularies.29 These principles include the need for hierarchical arrangements of codeable content, formal definitions of controlled vocabulary terms, and the ability to reproducibly combine and re-use atomic concepts.
Standard vocabularies are composed of data elements called concepts, which are often given narrative and/or structured descriptions to help convey their intended meaning. The concepts which are explicitly included in a vocabulary, and assigned an explicit code, are said to be pre-coordinated (i.e., established before the vocabulary is published). For example, SNOMED-CT contains pre-coordinated concepts representing myocardial infarction and severe. Those two concepts can be used together to represent severe myocardial infarction. When multiple concepts are combined to represent a desired meaning (after the vocabulary is published), the combination is said to be post-coordinated. Terminologies can be designed to facilitate post-coordination by sanctioning appropriate types of combinations (e.g., a disorder qualified by a severity). Post-coordination can mitigate a so-called combinatorial explosion of pre-coordinated concepts which are exhaustively enumerated in an attempt to anticipate every conceivably useful combination, but which result in a terminology too large to manage effectively. However, post-coordination is also challenging (e.g., given the desire to somehow sanction all useful combinations while proscribing all meaningless combinations). Vocabulary providers and other standards experts are currently developing rules for reproducibly post-coordinating concepts and situating them in data structures such as HL7 messages, but that work is not yet mature. At present, policy makers, health informaticists, and HIT vendors recognize that there are gaps in coverage, definition, and implementation of content and vocabulary standards.
Recently, HHS awarded a $3.3 million contract to the American National Standards Institute to convene the Health Information Technology Standards Panel (HITSP). The HITSP is composed of representatives from U.S. Standards Development Organizations and other stakeholders, and is tasked to develop a process to address variations and gaps in HIT standards that hinder interoperability.30 The need for a reproducible method for recognizing and filling gaps in codeable vocabularies may be an issue considered by the HITSP. In addition, HHS awarded contracts totaling $18.6 million to four groups to develop and implement prototypes for the National Health Information Network and information exchange that may also address these gaps.
SNOMED-CT
SNOMED-CT is internationally recognized as a robust, comprehensive healthcare terminology, and is the largest controlled biomedical terminology available in the U.S. Built from the merger of SNOMED-RT (a description logic-based vocabulary developed by the College of American Pathologists) and the Clinical Terms Version 3 (developed for use in primary care information systems by the British National Health Service), SNOMED-CT currently contains over 361,800 healthcare concepts, 975,000 descriptions of the concepts (synonyms), and approximately 1.47 million semantic relationships. SNOMED-CT was recommended by CHI Phase I as the vocabulary standard for several clinical domains (see Table 2). In 2003, the Federal Government acquired a license to freely distribute SNOMED-CT in the U.S. through the Unified Medical Language System (UMLS).31
Clinical Logical Observation Identifier Names and Codes (LOINC)
LOINC32 is a database in the public domain maintained by the Regenstrief Institute, with support by or under contract with the National Library of Medicine (NLM) in HHS. It includes almost 40,000 coded concepts. LOINCs original focus was on laboratory results. In 2001, the LOINC framework was extended to support the codification of nursing instruments by adding the text of the questions and the source of the question within existing instruments.33, 34, 35 Several organizations have submitted their nursing surveys for inclusion in and encoding by LOINC (e.g., the Home Health Care Classification Survey, OMAHA Survey, etc.). Renamed Clinical LOINC to reflect its expanded focus, the modified framework now closely mirrors the needs of survey theory.
HIT Messaging via Health Level 7
Messaging standards serve as the means by which computer systems exchange clinical and administrative information. Although multiple messaging standards exist, HL7v2 is of primary importance to MDS standardization.
HL7v2 specifies an extensive collection of standard messages and exchange protocols for electronic healthcare data exchange. Messages consist of a group of required or optional message segments in defined sequences, which together convey specific types of information such as admission/discharge/transfer, financials, pharmacy reporting, orders, observations, and so on. Certain message segments can be re-used in many different types of messages to transmit data for a particular domain (e.g., results of observations).
CHI Phase I endorsed the HL7v2+ standard for use across the federal healthcare enterprise to support the electronic transmission of clinical information. NCVHS recommended that the use of HL7v2 and LOINC, in conjunction with standard vocabulary, be considered as a way to enable unambiguous sharing of data.
Integrating MDS with HIT Content and Messaging Standards
LOINC, SNOMED-CT and HL7v2 are intended to work together. In this project, we identified codeable terms from standardized vocabularies and a representation of the MDS using the Clinical LOINC database to enable standards-based completion, transmission using HL7v2 messages, and analysis of MDS data.
USING HEALTH INFORMATION TECHNOLOGY STANDARDS TO STANDARDIZE THE MDS
In 2003, ASPE contracted with Apelon to conduct a pilot project examining the feasibility of integrating HIT content and messaging standards with the MDS. As a result of this work, Apelon concluded that terminology and messaging standards supported many MDS features and that the standards development organizations were interested in addressing gaps between the standards and MDS.
Based on that pilot work, ASPE initiated a partnership with CMS and contracted with Apelon to standardize the MDS using applicable CHI-endorsed HIT content and messaging standards. The projects scope grew from a subset of MDSv2 and the emerging MDSv3 to include all of MDSv2.
This section describes the methods and findings for the work undertaken in this project related to:
- Standard vocabulary coverage analysis;
- Representing MDSv2 in Clinical LOINC; and
- Using Clinical LOINC codes and standard vocabulary concepts to construct HL7 messages.
MDS and Standard Vocabularies
Methods
The MDS data used in this project came from multiple sources. The government provided Apelon with the MDS form and associated documentation in Adobe Portable Document Formant (PDF) format along with an Excel spreadsheet containing all MDSv2 Resource Utilization Groups (RUG) items, and a Microsoft Word document of a sample of MDSv3 items. Later, Apelon received an Access database containing the MDSv2 questions and answers in a computable format, although the Access version contained differences from the MDS text previously received. Apelon identified the items from the initial focus related to drugs, diseases, and diagnosis.
MDSv2 contains nearly 600 distinct items organized into 23 sections. Nearly all these items are formatted as a multiple-choice question with from just a few to more than 20 possible answers. Many items also include headings and explanatory material such as instructions and examples. Our first objective was to determine the extent to which CHI-recommended standard vocabularies described the same subject areas as these items.
| TABLE 3. MDSv2 Sections & Emerging MDSv3 Domains, Source Sections, and Searched Terminologies | ||
| MDSv2 Domains and MDSv3 Items | MDS Section Location Code | Terminologies Analyzed for Coverage |
| Identification Information/Background Information | AA, A | SNOMED-CTHL7V3 |
| Demographic Information | AB, A | SNOMED-CTHL7V3 |
| Customary Routine | AC | NA |
| Face Sheet Signatures | AD | NA |
| Cognitive Patterns | B | SNOMED-CT |
| Communication/Hearing Patterns | C | SNOMED-CT |
| Vision Patterns | D | SNOMED-CT |
| Mood and Behavior Patterns | E | SNOMED-CT |
| Psychosocial Well-Being | F | SNOMED-CT |
| Physical Functioning and Structural Problems | G | SNOMED-CT |
| Continence | H | SNOMED-CT |
| Disease Diagnoses | I | SNOMED-CTICD-9-CM |
| Health Conditions | J | SNOMED-CTICD-9-CM |
| Oral/Nutritional Status | K | SNOMED-CT |
| Oral/Dental Status | L | SNOMED-CT |
| Skin Condition | M | SNOMED-CT |
| Activity Pursuit Patterns | N | SNOMED-CT |
| Medications | O | SNOMED-CTNDF-RT |
| Special Treatments and Procedures | P | SNOMED-CT |
| Discharge Potential and Overall Status | Q | SNOMED-CT |
| Assessment Information | R | NA |
| Therapy Supplement for Medicare PPS | T | NA |
| Memory | B2, MDSv2 (modified for MDSv3) | SNOMED-CT |
| Cognitive Skills for Daily Decision Making | B3, Option 2, MDSv2 | SNOMED-CT |
| Symptoms (Problem Conditions) | J1, MDSv3 | SNOMED-CT |
| Goals for Remainder of Stay | DRAFT MDSv3 Item | SNOMED-CT |
| Prognosis | DRAFT MDSv3 Item | SNOMED-CT |
| Advanced Directives | DRAFT MDSv3 Item | SNOMED-CT |
| Depression | E1A | SNOMED-CT |
| Behavioral and Psychotic Symptoms | B6, MDSv3 | SNOMED-CTICD-9-CM |
| Delirium | DRAFT MDSv3 Item | SNOMED-CT |
| Active Diagnoses | DRAFT MDSv3 Item | SNOMED-CTICD-9-CM |
| Falls | J4 | SNOMED-CT |
| Pain | DRAFT MDSv3 Item | SNOMED-CT |
| Pain Management | DRAFT MDSv3 Item | SNOMED-CT |
Standardized vocabularies all serve specific purposes, as in the use of ICD-9-CM for administrative and billing classification of diagnosis, or National Drug Codes to transmit prescriptions. CHI recognized this specialization in its recommendations by choosing different vocabularies for different healthcare domains or purposes. The MDS sections do not correspond exactly to the domains identified by CHI. For example, the MDSv2 demographics section (AB) contains the subsections Mental health history (AB9) and Conditions related to MR/DD status (AB10), outside the conventional definition of demographics. Conversely, while MDS does not contain any section named Anatomy to correspond with CHIs recommendation to use SNOMED-CT for anatomy terms, MDS items frequently include an anatomical component. Of all the CHI-endorsed vocabularies, SNOMED-CT offers the only large-scale collection of findings concepts. It was also endorsed for use in the CHI initiative to describe nursing concepts (as well as other clinical domains), and since nurses generally complete the MDS, again SNOMED-CT was the primary vocabulary examined in this study. However, Apelon also determined whether other CHI-endorsed vocabularies would be appropriate to examine for each section of the MDS. Table 3 shows the MDSv2 sections and MDSv3 items covered in this project along with the terminologies that Apelon evaluated for coverage. Certain MDS sections do not include items appropriate to terminology matching; these are marked NA in the table.
Generally, Apelon searched SNOMED-CT for coverage in all MDS domains. We performed additional searching using the CHI recommendations for guidance; therefore, some sections utilized more than one terminology (e.g., HL7v3 was used for pertinent demographics-related items). We evaluated vocabulary coverage using vocabulary versions current as of November 2004.
ICD-9-CM coverage evaluation for diagnoses and problems was performed after the initial SNOMED-CT work finished, due to the use of ICD-9-CM in other federally-required assessment instruments. NCVHS, although recommending SNOMED-CT for use in problem lists and diagnoses, stipulated the need for mappings from ICD-9 to SNOMED-CT with its recommendations in the following January 2004 report to HHS Secretary Thompson:
No terminology is complete, but SNOMED-CT is sufficiently complete in the areas of diagnoses and problem lists, especially in comparison to other available terminologies. However, it is essential that accurate mappings exist between SNOMED-CT and other administrative code sets and terminologies including ICD-9.36
The terminology coverage analysis, the requirement to include feedback from experts distributed around the country, and distribution of the results in multiple formats required us to develop an information technology infrastructure. Apelon used its Distributed Terminology System (DTS)37 to facilitate:
- integration of the multiple sources of MDS and related data,
- development of a hierarchical MDS structure,
- Web-based terminology searching and browsing, and
- development of a unified database of MDS items, matched standard terminology and expert feedback.
DTS includes vocabulary server software that facilitates the integration of standardized vocabularies, including local enhancements, into healthcare enterprise applications such as clinical data repositories and data warehouses, electronic health record (EHR) systems, Web information retrieval systems, decision support systems, guideline authoring, guideline management systems and electronic data capture applications.
DTS provided the base needed to present and interlink MDS and the standard terminologies. DTS database technology allowed arbitrarily complex queries against the MDS, the standard terminologies, and the feedback obtained from expert reviewers. Our integrated DTS database included the following components:
- hierarchical representation of all the selected MDSv2 and MDSv3 items;
- item definitions from the MDSv2 form and Users Manual (2000);
- identification of item uses, including payment, quality indicators and/or quality measurement;
- searchable, browsable standard vocabularies;
- links between standard vocabularies and MDS items; and
- expert feedback on vocabulary links and MDS items.
This project utilized a hybrid lexical (based on words and word forms) and semantic (based on meaning) matching approach to perform the vocabulary coverage analysis: a clinical informaticist derived search phrases from MDS (including both questions and answers) and submitted the phrases to a lexical search tool with access to the requisite standard terminologies. Resulting candidate terminology matches were reviewed and iteratively refined by the informaticist to uncover the standard vocabulary terms that most closely matched the intended meaning of each such MDS phrase. A final component of the project included review by persons with expertise in the MDS. This process is described in detail in the following paragraphs.
First, Apelon exported the MDS headings, questions, and answers from the DTS database into a Microsoft Excel spreadsheet. Then, we used Apelons TermWorks software (http://apelon.com/literature/datasheets/TermWorks.pdf) to identify standard vocabulary concepts that matched the MDS items. TermWorks provides sophisticated lexical search capabilities via the familiar Excel interface. The software compares every word in the search term (an MDS heading, item, or response) against every available concept in a selected standard vocabulary. When more than one standard concept matches a search term, TermWorks returns a rank-ordered set, with the most similar matches first.
Because TermWorks looks for any of the words in the search term in any of the standard vocabulary concepts, shorter search terms tend to retrieve a more focused set of results. This notion is similar to that employed by most search engines on the World Wide Web: a few key words often yield better results than an entire sentence because the search focuses on the important ideas. As shown in Figure 1, MDS includes supportive information such as examples, instructions and other context. Inclusion of all this material in the TermWorks matching would have resulted in matches to many standard vocabulary concepts whose meanings had little to do with the MDS term. Therefore, we excluded most of the supporting material on the MDS form and in the associated instructions from the TermWorks matching. Figure 1 highlights, by way of example, content not included in the TermWorks matching.
| FIGURE 1: Section of MDSv2 Form with Highlighted Text Showing Content Not Included in Lexical Analysis |
 |
MDS items and responses without inherent content (e.g., N/A, none of (the) above, other), were also excluded from matching. Figure 2 shows an example MDSv2 response without inherent content.
| FIGURE 2: MDSv2 Example Without Inherent Content |
 |
| NONE OF ABOVE was excluded from matching. |
The specific parameters used in TermWorks matching may significantly impact the results. We searched all the available standard vocabulary synonyms (e.g., SNOMED-CT includes heart attack as a synonym of the concept for myocardial infarction) and expanded some acronyms (e.g., IV = intravenous, TCA = tricyclic antidepressant) to ensure that matching stayed in context (for example, we did not want to match IV to Roman numeral 4 or initial velocity). In some cases, we overrode TermWorks default settings for word order normalization in order to preserve the meaning of a compound noun phrase (the difference in meaning between cold head and head cold is a commonly-cited example). The left side of Table 4 shows TermWorks 25 highest-ranked SNOMED-CT concepts matching the phrase adequate vision. The right side shows the same search except that the word vision has been made mandatory. This figure demonstrates that automated search results can differ widely depending on the search strategy employed. The potential of post-coordination (i.e., combining two or more standardized matching terms) to achieve better matching results in certain examples, such as this one, is discussed below.
TermWorks provided us with a high-speed first pass to assess the MDS coverage of a standard vocabulary, and the results were encouraging. Virtually all the MDS search terms returned one or more candidate matching concepts from a standard vocabulary. This is an important finding, in that it confirms the CHI endorsement of these vocabularies for use in the emerging electronic health information infrastructure.
As shown in Table 4, many SNOMED-CT concepts containing some of the same words as an MDS search term do not provide a useful match. Apelons clinical informatics team reviewed all the candidate matches to further refine the matching results, again using Excel augmented with TermWorks. This refinement often included additional searches for other key words or phrases based on the information that was excluded (see Figure 1 and Figure 2) from the initial automated search.
The clinical informaticist review led to the identification of a small number of standard vocabulary matches deemed appropriate for the MDS items. As an additional step, domain experts reviewed more than half the total MDS content sampled from all MDS domains. For each reviewed MDS term, we characterized any available standard vocabulary matches as follows:
Best matches seem to closely capture the meaning of the MDS phrase.
Broader standard terminology matches are related to, but more general than, the MDS phrase, and thus do not capture the specific MDS meaning. These matches, however, do identify the right place within the terminology for adding an exactly matching term. These broader matches can serve to communicate terminology gaps to the terminology providers.
Partial matches are related to the MDS phrase, but only partially overlap its meaning. For example, Needs help with feeding partially overlaps with the MDS phrase ADL [Activities of Daily Living] Support Provided in that the former is both more specific (citing feeding) and more general (does not necessarily indicate that support is provided).
| TABLE 4: TermWorks Results for "Adequate Vision" (left) and With the Word "Vision" Made Mandatory (right) | |
| Adequate and/or Vision | Adequate and Vision |
| Adequate (qualifier value) | Disorder of vision (disorder) |
| Drug directions not adequate and appropriate (finding) | Diplopia (disorder) |
| Lack of adequate intermaxillary vertical dimension (disorder) | Eye / vision finding (finding) |
| On examination - VE - pelvis adequate (context-dependent category) | Finding of binocular vision (finding) |
| Adequate workplace welfare facility (finding) | Finding of color vision (finding) |
| Adequate canteen at work (finding) | Finding of vision of eye (finding) |
| Adequacy of peritoneal dialysis (observable entity) | Finding related to focusing (finding) |
| Adequacy of living space (observable entity) | Fixation of vision, function (observable entity) |
| Drug directions adequate and appropriate (finding) | Hazy vision (disorder) |
| Finding of adequacy of living space (finding) | Increased vision (finding) |
| Pelvis not adequate for delivery (finding) | Interference with vision (finding) |
| Pelvis adequate for delivery (finding) | Monocular vision, function (observable entity) |
| Suicide attempt by adequate means (disorder) | Normal vision (finding) |
| [V]Lack of adequate food (context-dependent category) | Peripheral vision, function (observable entity) |
| Adequate anesthesia (finding) | Photopic vision (observable entity) |
| Adequacy of specimen (observable entity) | Scotopic vision (observable entity) |
| Adequacy of hemodialysis (finding) | Sees haloes around lights (finding) |
| Adequacy of dialysis (observable entity) | Sight deteriorating (finding) |
| Finding of adequacy of dialysis (finding) | Stereoscopic vision (observable entity) |
| Housing adequate (finding) | Vision convergence, function (observable entity) |
| Income sufficient to meet needs (finding) | Vision therapy (regime/therapy) |
| Sufficiency of income for needs (observable entity) | Vision screening (procedure) |
| Disorder of vision (disorder) | Vision observable (observable entity) |
| Finding of vision (finding) | Vision, function (observable entity) |
| Vision, function (observable entity) | Finding of vision (finding) |
Attachment C includes a side-by-side depiction of each MDSv2 section and the standard vocabulary matches we found. Table 5 presents an example of the matching results within Attachment C for MDSv2 Section G1B (ADL SUPPORT PROVIDED).
| TABLE 5: Matches Found for MDSv2 Section G1B: ADL Support Provided |
| BEST MATCH TERM |
| Assisting with activity of daily living (procedure) |
| BROADER MATCH TERM |
| Support (regime/therapy) |
| PARTIAL MATCH TERM |
| Finding related to ability to transfer (finding) |
| Needs help in toilet (finding) |
| Needs help with cooking (finding) |
| Needs help with feeding (finding) |
| All matches shown are from SNOMED-CT. |
Upon completion of the Apelon review, the standard vocabulary matches were loaded from Excel into the DTS database and linked to the MDS items. Altogether, more than 2,000 standard vocabulary concepts were identified as possible matches (best matches, partial matches and broader matches). In approximately 8% of the phrases examined, we found no appropriate counterpart for an MDS item in the standard vocabularies analyzed. In these cases we manually verified the results and recorded the lack of a matching standard vocabulary concept. In Attachment C, items for which no standardized match could be found are labeled NO MATCH FOUND.
Then, using a specially enhanced version of the DTS Web browser software developed for this study, experts in the MDS and its uses provided further review of the terminology matching and further insight into MDS. In a series of conference calls as well as via independent review using the Web browser, these experts provided more than 880 separate pieces of feedback on the standard vocabulary matches. Table 6 repeats the data from Table 5, but adds the feedback provided by the experts as an additional column. Automatically-generated timestamps are shown in bold. In Attachment C, reviewer feedback (when available) appears alongside the matches found for each section of the MDSv2.
| TABLE 6: Matched Terms and Reviewer Feedback for MDSv2 Section HeadingG1B: ADL Support Provided | |
| BEST MATCH TERM | REVIEWER FEEDBACK & NAME This is a label, not an item or response. (dmalitz 2005/05/31 12:33) Finding related to ability to transfer (finding) Code: F-02C55 Id: 397666 might be a partial match. Cooking is not one of the ADLs. (rshepard 2005/05/27 18:34) |
| Assisting with activity of daily living (procedure) | |
| BROADER MATCH TERM | |
| Support (regime/therapy) | |
| PARTIAL MATCH TERM | |
| Finding related to ability to transfer (finding) | |
| Needs help in toilet (finding) | |
| Needs help with cooking (finding) | |
| Needs help with feeding (finding) | |
| All matches shown are from SNOMED-CT. | |
Findings
Apelon identified a total of 537 phrases (including headings, questions and answers) in MDSv2 and performed automated TermWorks matching on all of them. The TermWorks software returned one or more candidate matches from SNOMED-CT and/or another CHI-endorsed vocabulary for virtually all of these phrases. Apelons informaticist review, however, winnowed the total to 2,064 candidate concepts (mostly from SNOMED-CT) that were identified as potential matches for these phrases. We performed a similar exercise with a sample of MDSv3 items.
CHI-recommended standard vocabularies provided plausible matching for the large majority of these MDS phrases. Specifically, from our review of almost 90% of the MDSv2 phrases that we examined we found:
- Complete coverage for 47% (250/537) of the MDSv2 terms and concepts.
- Partial coverage for 45% (244/537) of the MDSv2 terms and concepts.
- No useful matches to standardized vocabularies for 8% (43/537) of MDSv2 phrases.
Attachment C and Attachment D show all analyzed MDSv2 and MDSv3 items and the matching concepts from the CHI-endorsed standard vocabularies, along with the expert feedback received.
The specific vocabulary codes that correspond with each of the standardized vocabulary matches identified in Attachment C and Attachment D can be found in Attachment F.
Discussion
While these findings are encouraging, there are a number of caveats to consider. Most importantly, the definition of a good match remains something of a moving target. As discussed above, survey theory and psychometric theory may restrict the perceived validity of any translation of the MDS form as it is presented. A strict interpretation, therefore, says that even if a standard vocabulary has exactly the same words as an MDS item, the meaning may not be perceived by the user in the same way, potentially invalidating the whole notion of a match. Even a more liberal interpretation of standardization presents some problems. For example, the MDS instructions and definitions often convey additional meaning that either expands on or constricts the common-sense definition of the MDS item. Our experts were often frustrated on one hand by a wealth of supporting documentation on the MDS, which often led them to downgrade a match from exact to partial, and on the other hand by the lack of narrative definitions for SNOMED-CT concepts.
Often, our reviewers found that a very close match was possible based on the combination of two or more terms. In Table 4, while neither Finding of vision (Finding) nor Adequate (qualifier) is a complete match for the MDS phrase Adequate vision, putting the two together seems to make a very close or exact match. The practice of combining two or more standard vocabulary concepts to create a new expression is called post-coordination. SNOMED-CT is specifically designed to support post-coordination. However, the rules or grammar for post-coordination are still a research topic within the standards development community. Therefore, while we recognize that post-coordinated expressions based on standard vocabulary concepts would undoubtedly increase the percentage of exact or more complete matches, we did not include post-coordinated expressions in our analysis.
One of the most important difficulties we encountered in assessing standard vocabulary coverage of MDS items concerns the structure of the MDS form itself. Many MDS items take the form Does the resident have/exhibit/do
This project entailed work with MDSv2 and selected MDSv3 items as they were. Although outside the scope of this project, principled design of items, including appropriate distribution of content between the question and answers is an important matter. In the future, responsible parties may wish to explicitly consider pertinent standard vocabularies during the design process. For example, questions and answers which correspond exactly to concepts found in standard vocabularies are highly amenable to automatic derivation of suggested answers from electronic health records, sophisticated vocabulary-based analysis, and so on.
We continually refined the matching parameters and criteria for review of candidate terms during this project. Therefore, the matches presented in Attachment C should not be considered as a cohesive collection, but rather as the consequence of this evolutionary approach. The recommendations in this report highlight the lessons we learned about the importance of clearly identifying and communicating the matching parameters and the intended use for any connection between MDS and CHI-endorsed vocabularies. For example, late in the project, we identified the important concept of usefully related terminology matches. Usefully related matches show connections between standard vocabulary concepts and the MDS that would be useful to a clinician filling out the MDS form, but are not exact matches for all the nuances of the MDS item. Thus, we recommend that the government review the standardized vocabulary matches identified through this study and determine those matches it believes to be usefully related to the MDS items. Those matches determined to be usefully related could be:
- re-used to the extent the same items are included in the emerging MDSv3; and
- distributed for use by the private sector in the development of software applications that seek to use standardized content.
Another area touched upon but generally excluded during this work was the idea of information models for certain MDS items. Information models in HIT are pre-built templates for information, with each template built from a set of re-usable attributes. As a simple example, an information model for pain might include its location in the body, a characterization of its intensity, its quality, its date of onset and duration, and so on. Such an information model could perhaps replace, or at least help inform, idiosyncratic MDSv2 items such as Items J2 and J3 with information structures that are directly comparable with pain descriptions from other sources that use the information model. As described in the Next Steps section below, we believe that such models hold great promise for development of future HIT-enabled survey instruments. However, information model development was out of scope for this project.
MDSv2 AND CLINICAL LOINC
The vocabulary coverage analysis described in the previous section provides an encouraging basis for the integration of vocabulary standards recommended by CHI into the MDS. However, our results suggest that vocabulary-based semantic interoperability of MDSv2 may be several years away. Therefore, we looked for alternative standardization strategies with more immediate applicability. That search led us to Clinical LOINC, described previously. Unlike SNOMED-CT or even ICD-9-CM, each of which includes a semantic model that may be difficult to harmonize with an instrument such as MDSv2, LOINC serves primarily as a structured, standardized container for assessments and surveys (like the MDS) that is designed to work in concert with other HIT standards.
Methods
Apelon subcontracted with Dr. Thomas White38 to develop a LOINC-compatible representation of MDSv2. Dr. White and a group of students from Columbia University began exploring the use of LOINC to represent MDS content in 2002 as part of a class project. In the current project, he used the methods previously developed along with the experience he has gained in developing an electronic repository of mental health survey instruments in his work for the New York Department of Mental Health.
The first step in developing a Clinical LOINC representation of any survey is to break the survey down into its constituent parts. Although conceptually similar to the parsing process we undertook in the vocabulary coverage analysis, the LOINC representation is intended to capture all the data on the form, including formatting and instructions. Dr. White and his team ran into the same questions we discovered during the vocabulary coverage analysis regarding the distribution of information between the question and the responses. Whenever possible, to preserve the previously-identified standard vocabulary matches, Apelons question-answer divisions were re-used in developing a LOINC-compatible representation of the MDS. In addition, Dr. Whites team extracted the Help and Consistency Notes sections from the Resident Assessment Validation and Entry (RAVEN) database. When discrepancies were found between content in the RAVEN database and the paper forms, the text from the paper forms was given precedence.
The smallest constituent parts of surveys are called items, which are roughly equivalent to a question and the allowable answer options. According to Survey Theory, each item has three definitions. The conceptual definition describes what the item is trying to measure. The operational definition specifies how that variable is collected, and is equivalent to the text of the question. The variable definition specifies the allowable response options, such as the data type, enumerated list of answers, and associated coded values. Each item is fully defined by the operational and variable definitions, with the conceptual definition being descriptive. These items are the atomic-level measurable entities within survey instruments.
According to Psychometric Theory, the interpretation of an item can be altered by the context in which it is used, such as neighboring items or associated help and instructions. Thus, identical items could have different conceptual meanings when used within different instruments.
The Clinical LOINC committee decided to model surveys at both the item and instrument levels. Each item has its own LOINC code. Each instrument is a LOINC Panel, which lists the items it contains, plus associated metadata like the order in which items should be asked. Each Panel is also assigned a unique LOINC code.
The LOINC database includes a separate record for each item in each included survey instrument. Although LOINC has six primary axes used to distinguish among related tests, four supplemental axes are most important for distinguishing survey items. The primary axes are:
- component
- property
- time_aspect
- system
- scale_type
- method_type
The supplementary axes are:
- SurveyQuestionText
- AnswerList
- Formula
- SurveyQuestionSource
- Comments
The component encapsulates the meaning or intent of the variable, and is essentially the conceptual definition. The property distinguishes between observations and findings. The time_aspect traditionally specifies the temporal aspects of the variable, such as whether it is a point in time measurement or represents symptoms having occurred within the prior two weeks, but since many survey items define the temporal aspects within the questions themselves, the value for time_aspect is always a point in time, to indicate that the results for this survey item reflect the knowledge about the variable at this point in time, rather than trying to represent the time period to which the variable refers. The system specifies the entity being measured, such as the patient, family member, or other caregiver. Typical scale types are nominal, ordinal, quantitative, and narrative. The method_type is used to disambiguate elements which are identical on the first five axes, but have different clinical meaning due to the method used to collect them. SurveyQuestionText is the full text of the question asked, effectively the operational definition. AnswerList is the variable definition, containing a formatted list of response options and associated coded values. The Formula field stores computable equations, such as quality measures or scale scores. SurveyQuestionSource is a delimited record indicating the name of the instrument and the sequence number of that question within the instrument. The Comments field stores item specific instructions and help which do not appear on the original survey form, but are included in the instruction manual.
Any change in SurveyQuestionText or AnswerList results in a new LOINC code, since such changes might result in a change in meaning. LOINCs goals are to provide the minimum number of codes needed to represent clinically distinct entities. Having separate LOINC codes for each small variant in question wording may seem to deviate from that goal, but survey instruments pose a Catch-22. The only way to know whether two items should really have one code is to first give them separate codes, and then study their psychometric properties to see whether they measure the same constructs. If so, the codes can be merged.
LOINC uses Panels to represent entire survey instruments. This makes it possible to re-use items across instruments, yet uniquely identify the version and contents of a survey by the LOINC record for that Panel. The Panel specifies which survey items are contained within it, and associated metadata like variable names, the order in which questions are asked, branching logic, and local equations.
The proposed supplementary axes were presented to and refined by the Clinical LOINC committee at their meetings between 2002 and 2003, including proof-of-concept conversions of all existing nursing instruments into the new model, plus the addition of five mental health instruments. The most recent updates of this work were presented at a national panel at the 2005 American Medical Informatics Association Fall Meeting. The extended LOINC framework served as the basis for the LOINC representation in this project.
In addition, in February 2006 the LOINC committee reviewed proposals to extend the LOINC model with one new field needed to support the assessment/survey instruments, such as the MDS. This Context field will encapsulate instructions that are relevant to groups of assessment items
Findings
A LOINC-compatible representation of the MDSv2 was created re-using, whenever possible, the question-answer divisions created in the earlier phase of this study.
The MDS representation in LOINC was presented to the Clinical LOINC committee in February 2006. In June 2006, the Clinical LOINC committee formatted and coded the following MDSv2 assessment instruments: Basic Assessment Tracking Form, Full Assessment Form, MDS Quarterly Assessment Form, MDS Quarterly Assessment Form (Optional Version For Rug-III MDS Quarterly Assessment Form), and Optional Version For Rug-III 1997 Update. A draft version of the LOINC formatted and coded MDS assessments are available at http://aspe.hhs.gov/daltcp/instruments/LOINC.pdf. The draft and final LOINC formatted and coded MDS assessments are available by downloading RELMA at http://www.loinc.org. (After downloading and installing RELMA, click "Map Local Terms to LOINC" button; type "MDS", "ASSESSMENT", and "FORM" into the first three "Local Words" boxes; click Search (Ctl+Enter); highlight the desired MDS assessment form; click "View Details"; and select the "HTML w/details" radio button).
Messaging
This section provides a brief overview of HL7v2 messaging and how its use can support the interoperable exchange of MDS data using both the standard vocabularies and Clinical LOINC.
HL7v2 messages allow computer systems to exchange information in a structured format. HL7v2 standards are analogous to the standards specified by the U.S. Post Office, including envelope size, postage amount and placement, address format, ZIP code, mail type and so on. When a letter is correctly addressed and posted, the sender can be confident that it will be delivered to the intended recipient. The recipient can then open and read the letter and respond appropriately. Because HL7v2 messages are intended to be read by a computer system rather than a person, HL7v2 messages also include explicit information that the receiving system can use for processing, such as what kind of message it is (for instance, a laboratory result should be processed differently than a request for a radiology consultation or an admission order) and what to do if the receiving system has problems receiving the message.
HL7v2 messages are composed from re-usable segments, each of which contains some number of data fields. Sample data fields include a patients name, or a laboratory result, or a stream of binary data that encodes an x-ray image. HL7 volunteers define and publish the structure and constraints used in the messages, segments and fields. Healthcare enterprises and software developers then implement systems to send and receive these messages and use the data in applications that support the care process.
Although structured, patient-oriented clinical data can be transmitted within several HL7v2 message types for different purposes (e.g., medical document management, results reporting, clinical trials, etc.), all such message types use the Observation/Result (OBX) segment to transmit each individual clinical observation, the smallest indivisible unit of a report. The OBX-3 Observation Identifier field encodes the name of the thing observed (e.g., Pain Site, Bowel Elimination Pattern, Unsettled Relationships, etc.) via a single code from some master observation table or an external coding system, such as LOINC. The OBX-3 field identifies the question being asked. The OBX-5 field contains the resulting value for the observation identified by OBX-3 (i.e., the answer or response to a question). OBX-5 values can be transmitted as any suitable data type (e.g., coded, numeric or free text). Encoded OBX-5 observation values must be flagged with a CE value, denoting a coded element or entry. HL7 allows coded values from multiple external coding systems, including all Health Insurance Portability and Accountability Act (HIPAA) and CHI-designated terminologies. The OBX-5 field identifies the answer to the question.
Numerous OBX segments must be assembled to send all the observations in a report. They can be bundled into explicit panels or batteries of observations (e.g., electrolytes, vital signs, sections of a survey or assessment form, discharge summaries, etc.) by following a shared header, an Observation Request Segment (OBR). The OBR segment can be used to name an entire assessment form.
As Apelon and LOINC analyzed the MDS, they recognized that to create HL7 messages using coded assessment content (i.e., using SNOMED and other CHI-endorsed vocabularies), relationships with coded content would need to be specified at three levels: questions (Q), answers (A), and answers within the context of their associated question (Q+A). As mentioned earlier, answers to assessment items are sometimes, by themselves, clear and unambiguous, but in other instances answers are highly dependent on the specific question being asked. Thus, when exchanging information about a patients assessment status, it may sometimes suffice to exchange only the coded answer (or sometimes multiple answers). However, the exchange of assessment results will often require an exchange of both the question and corresponding answer.
Figure 3 highlights this issue. Figure 3 shows two MDS items (B4 and AC1a), with the text of their questions and allowable answers, plus the coded values for those answers. The figure also shows the SNOMED matches identified by Apelon for those questions and answers. The figure shows that sometimes several post-coordinated SNOMED values may be needed to represent answers, such as for answer code 2 in item B4. Moreover, sometimes the meaning of a mapping will require knowledge of both the question and answer, as in item AC1a. Although there is a perfect SNOMED match for the answer "Yes", one must also know the question in order to understand the meaning of the "Yes" response. To exchange information this topic the response value must be coordinated/linked with the question. Similarly, Apelon identified possible SNOMED matches to some questions, like B4. Traditionally, SNOMED codes the meaning for answers. When messaging the answer values to questions like B4, it may be appropriate to also post-coordinate the SNOMED codes related to the question to better capture the intent of the answer.
MDS AC1 says check all that apply. AC1a is one of the variables which can be checked. The check box has possible values of 0 (No), 1 (Yes), and -- (Unable to determine). There is fine print at the bottom of the page describing those possible options -- e.g., that users should check the box for Yes, and put a minus sign if they cant determine the answer. If they leave it blank, the value is presumed to be 0, for No. Those three possible values are specified within the RAVEN database.
| FIGURE 3: Sample Mapping of MDS Questions and Answers for Two Items to SNOMED Codes, Showing Need for Mappings at Question, Answer, and Question+Answer Levels | |||
| MDS Questions (B4) | SNOMED | ||
| Code | Text-Value | ||
| Ability to make decisions regarding daily life | F-03E75 | Ability to use decision-making strategies (observable entity) | |
| F-04C3D | Ability to make decisions (observable entity) | ||
| R-42E6A | Skills relating to cognitive functions (observable entity) | ||
| MDS Answers | SNOMED | ||
| Code | Text-Value | Code | Text-Value |
| 0 | INDEPENDENT-decisions consistent/reasonable | F-90161 | Able to make considered choices (finding) |
| 1 | MODIFIED INDEPENDENCE-some difficulty in new situations only | R-3006E | Unfamiliar environment (environment) |
| F-90120 | Difficulty making plans (finding) | ||
| 2 | MODERATELY IMPAIRED-decisions poor, cues/supervision required | F-90120 | Difficulty making plans (finding) |
| F-90156 | Unable to use decision-making strategies (finding) | ||
| F-90157 | Difficulty using decision-making strategies (finding) | ||
| 3 | SEVERELY IMPAIRED-never/rarely made decisions | F-90162 | Unable to make considered choices (finding) |
| F-90156 | Unable to use decision-making strategies (finding) | ||
| MDS Question (AC1a) | SNOMED | ||
| Code | Text-Value | ||
| Customary Routine: Stays up late at night (e.g. after 9 pm) | |||
| MDS Answers | SNOMED | ||
| Code | Text-Value | Code | Text-Value |
| 0 | No | R-00339 | No (qualifier value) |
| 1 | Yes | R-0038D | Yes (qualifier value) |
| - | Unable to Determine | R-41198 | Unknown (qualifier value) |
Given this knowledge of the sorts of mappings needed for assessment/ survey items, the LOINC committee proposed a HL7 messaging syntax that would support transmission of associated codeable vocabulary terms (e.g.., SNOMED terms), without requiring LOINC or any other terminology to uniquely name answers.
Figure 4 shows how an HL7 message could transmit part or all of the MDS, and any associated codes from other standardized terminologies.
- The OBR-4 segment specifies the name of the LOINC Panel, and thus the version of the survey; and
- Then, one or more pairs of OBX-3 and OBX-5 segments are used to transmit the name and value of each MDS variable. For example:
- The first OBX-3 segment in Figure 4 shows how MDS question B4 would be sent. The OBX-3 names the B4 item, and supports the alternate codes to identify the name of the source MDS variable used in the CMS RAVEN database.
- The next OBX-5 shows that the user selected answer 2, MODERATELY IMPAIRED-decisions poor, cues/supervision requires; plus the associated SNOMED code.
This message uses the standard HL7v2 syntax: Value^Message^Coding_System followed by AlternateValue ^AlternateMessage^AlternateCodingSystem. Thus, if nursing homes sent MDS reports via HL7 syntax, CMS would be able to parse out the values it needs (e.g., the value field from OBX-5), and store it in the proper variable within its database (the variable name field from the OBX-3 segment). Moreover, if nursing homes knew which SNOMED terms mapped to specific answers, they could also message those values.
| FIGURE 4: Sample HL7 Fragments for Messaging Survey Data Results | ||
| Field | Meaning | Example |
| OBR-4 | [Optional]: LOINC Code for Instrument / Panel (allows sending of multiple responses) | |45962-8^MINIMUM DATA SET FOR NURSING HOME RESIDENT ASSESSMENT AND CARE SCREEN^LN| |
| OBX-3 | LOINC code for item + alternate codes | OBX|3|CE|45490-0^MAKES DECISIONS REGARDING TASKS OF DAILY LIFE^LN^B4^Ability to make decisions regarding daily life^MDS| |
| OBX-5 | Response, allowing for alternate coding systems | OBX|5|CE|2^MODERATELY IMPAIRED-decisions poor, cues/supervision required^MDS^F-90157^Difficulty using decision-making strategies (finding)^SNM| |
| OBX-3 | LOINC code for item + alternate codes | OBX|3|CE|45428-0^STAYS UP LATE AT NIGHT^LN^AC1a^Customary Routine: Stays up late at night (e.g. after 9 pm)^MDS| |
| OBX-5 | Response, allowing for alternate coding systems | OBX|5|CE|1^Yes^MDS^R-0038D^Yes (qualifier value)^SNM| |
| KEY: CE = Coded Entry; SNM = SNOMED-CT; MDS = a locally identified coding system. If LOINC became the coding system for survey answers, the primary coding system would be LN for LOINC. Until this issue is resolved, a local, externally maintained coding system would need to be used. | ||
Discussion
The LOINC committee concluded that encoding assessment forms, such as the MDS, using LOINC codes will serve as the gold-standard coding system for these instruments. The LOINC terms will encapsulate the full operational and variable definitions of the assessment/survey items as intended by the developers of the instruments. This coding system creates a format that supports standardized information exchange, permits the exchange of content that has been standardized with codeable vocabularies, and allows additional SNOMED and related CHI vocabulary matches to be identified, and transmitted as alternate codes within the HL7 messages.
Ideally, nursing homes will not need to manually enter patient assessment data that could be automatically extracted from their standardized EHRs. In order to achieve this outcome, computer systems need to be able to: (a) identify all of the alternate codes which can be associated with LOINC-ified MDS (or other assessment) questions and answers; (b) be able to query their EHR to see if those alternate codes are present; and (c) create properly formatted HL7 messages which transmit both the LOINC and associated content codes for the MDS items. Thus, there is a need for a data dictionary which contains the mapping of all content codes that have been mapped to the MDS LOINC codes at the question (Q), answer (A), or question plus answer (Q+A) levels. Such a dictionary requires the creation of unique identifiers for each Q, A and Q+A pair.
There are two lingering dilemmas: (1) how and where to store the unique identifiers at the Q, A, and Q+A levels, and (2) how and where to store the vocabulary matches (such as SNOMED) that have been and will be linked with LOINC coded questions and answers. Alternative methods for addressing this issue require further consideration, including the pros and cons of maintaining such linkages by:
- The NLM/UMLS, given that its Metathesaurus is designed to maintain such relationships, and UMLS is the only authorized distributor of SNOMED codes (see Attachment F for further discussion on this alternative);
- Clinical LOINC; or
- Some other entity
Conclusion
Coding survey and assessment instruments using Clinical LOINC (i.e., LOINC-ifying instruments) is an efficient and straightforward step toward making existing data collection efforts compliant with standards such as HIPAA and other CHI standards. The initial LOINC-ification of an instrument assigns a unique name and code for each measurable entity within that instrument, even those for which there are no known mappings to existing clinical content standards. This is akin to creating a table for all of the variables in an instrument, plus all of the associated metadata (e.g., the text of the question and that of the answer options). Thus, there is effectively a one-to-one mapping between the variables that are already being collected and analyzed, and the new LOINC names for those variables.
This approach supports the longer-term goals of sharing data among systems. Although initial LOINC-ification efforts are likely to create new codes for each new instrument, Clinical LOINC will come to serve as a national item bank of unique question and answer-option pairs used within national data collection efforts. Thus, as new instruments are added to LOINC, the item bank can be searched to detect if needed data items already exist, and if so they can be re-used within the newly encoded instrument. As existing instruments are modified, new versions of the instrument are added to the Clinical LOINC database.
LOINC-ification can also assist efforts to map survey and assessment items to SNOMED-CT and other standard vocabularies. The meaning of a survey item is defined by the combination of the question, the available answer options, and the selected answer. Since this same combination is assigned a unique code in Clinical LOINC, the Clinical LOINC code serves as a basis for linking to a standard vocabulary. Moreover, the single question, as well as each numbered answer can be uniquely identified within the coded Clinical LOINC record. Therefore, every question, answer, and question-answer pair can be uniquely identified and linked to a standard vocabulary such as SNOMED-CT. In the case of an individual answer, one endpoint of the link is the Clinical LOINC code together with the question number, and the other endpoint is a standard vocabulary code such as the SNOMED-CT Identifier (SCTID). For example, a Clinical LOINC code would be assigned for MDS Section AA, question 2 regarding Gender, with potential answers of: (1) Male and (2) Female. That Clinical LOINC code in combination with answer number 2 would be linked to the matching SNOMED-CT concept of "Female (finding)" whose SCTID is 248152002.
LOINC-encoded assessment instruments combined with links to standard vocabularies such as SNOMED-CT will permit:
- a variety of analyses, including analyses of the relationships between data elements that would encourage comparability of data elements, and
- the development of variety of standardized HIT applications including electronic decision support tools needed to support caregiving.
In summary, coding MDS and other assessment instrument questions and answers into Clinical LOINC, linked with coded content, will:
- promote growth of an externally-maintained and publicly available repository of questions and answers that will be available for re-use by developers of future instruments, thus promoting comparability of questions and answers across instruments;
- encode the questions and answers into a standardized, machine-processible format that will support the identification and harmonization of overlapping and redundant items;
- support the standardized exchange of assessment/survey questions and answers; and
- encourage the development of clinically useful MDS-based software applications (e.g., clinical decision support tools).
In the short term, representing a survey in Clinical LOINC format does not address the potential duplication of items across survey instruments (e.g., the MDSv2 and the IRF-PAI might intend to measure the same thing but do so using slightly different language) because every variation is given a unique Clinical LOINC code. However, putting the items into the structured, standardized Clinical LOINC format provides a rigorous framework with which to thoughtfully address inter-survey duplication and the potential re-use of survey items.
SUMMARY
In this project, we pursued three complementary avenues to standards-enable MDSv2.
First, we identified links from MDSv2 to standard vocabularies such as SNOMED-CT. Our results show that todays CHI-endorsed clinical vocabularies contain most of the raw materials needed to describe MDS items, thus laying the groundwork for the future integration of MDS with clinical HIT systems. As existing assessment instruments are modified (e.g., transforming the MDSv2 into the MDSv3) or new assessments are created (e.g., those required in Section 5008 of the Deficit Reduction Act), developers of these assessments could determine whether the standardized matches identified in this study are usefully related to the emerging applications. In addition, we anticipate that completion of the MDS and other assessments can be assisted by recognizing MDS-related terms in standardized EHRs and suggesting or semi-automating responses to corresponding MDS items. Distribution of the matches determined to be usefully related to assessment content would enable the development of software applications that seek to use standardized content.
Second, we codified MDSv2 within the structured, standardized representation of Clinical LOINC. That codification provides the basis for launching a systematic effort to identify and eliminate unnecessary variation across federally-mandated assessment instruments and other survey forms by creating and capitalizing on an environment that enables the review and re-use of questions and answers. More generally, we found that standardizing patient health and functional assessment instruments using Clinical LOINC to support HL7 messaging is a fairly straightforward process that:
- retains the context embedded in the question and answer;
- encourages development of information models for various clinical domains (e.g., pain, pressure ulcers);
- enables the standardized transmission of all or parts of assessment forms to payers, regulators, providers, and other entities authorized to access this information;
- establishes a repository for questions and answers, thus facilitating re-use of questions and answers and promoting comparability across instruments; and
- allows the development of a variety of software tools including tools that could:
- identify relationships between data elements and thus support re-use of data for these identified relationships; and
- provide clinical decision support.
It is important to emphasize the synergistic interaction between our first pair of results: linking LOINC-encoded question and answer pairs to standardized terms that are either exact matches or are usefully related to each MDS item maximizes the ability to exchange and re-use clinical content. Furthermore, standardizing existing and new patient data collection tools using Clinical LOINC will support standardized information exchange using the HL7v2 messaging standard.
Third, we demonstrated encoding of assessment results in HL7v2 messages. Such messages provide the vehicle necessary to transmit MDS data within the standards framework laid out in the Presidents and Secretarys visions for a national electronic health information infrastructure. In particular, building on our second result, these messages can embody observation identifiers (OBX-3 fields) encoded with clinical LOINC to convey a type of observation -- an MDS question, paired with corresponding observation values (OBX-5 fields) also encoded with clinical LOINC to convey what was observed -- an MDS answer. Building on our third result, the OBX-5 fields can reference standard terminology (either directly within a field or indirectly through linkage from clinical LOINC codes to standard terminology). In combination, these results enable a variety of near-term pilot projects to explore interoperability.
From the preceding results, we concluded that standardizing content when possible and using Clinical LOINC to support standardized HL7 messaging are achievable steps towards a nationwide interoperable health information infrastructure that allows the standardized electronic exchange and re-use of health and functional data. However, in the course of our work, we also identified several current impediments to interoperability:
- limitations of pre-existing patient assessment tools;
- gaps in standardized vocabularies;
- uncertainties concerning how to reproducibly combine standardized terms;
- multiple possible strategies for the Federal Government to further this work; and
- the idiosyncratic, but nonetheless important, context of many data collection tools.
Therefore, our recommendations include building on the results achieved in this project while addressing the impediments which were discovered.
NEXT STEPS
The goals of this study were to make the MDS conformant with CHI-endorsed content and messaging standards, and to produce a policy relevant report that describes the issues with integrating these HIT standards into federally-required patient assessment applications. We now summarize our complete findings and recommendations, noting that some are explained more fully in the body of this report.
While this project has shown that CHI-endorsed standard vocabularies such as SNOMED-CT, HL7 and ICD-9-CM nominally contain most (up to 97%) of the concepts needed to standardize the intent of MDSv2 and presumably MDSv3, it is equally clear that standardization leading to semantic interoperability will require significant work and an ongoing collaboration between HHS, the developers of patient assessment forms (in this case CMS, the owner of the MDS), and the standards development community. To promote the integration of HIT standards into federally-required patient assessment tools such as the MDS, we advance the following recommendations pertaining to: (i) standardization (using content and messaging standards) of assessment instruments; and (ii) technical and policy infrastructure issues needed to support widespread deployment and re-use of standardized assessment instruments, in conjunction with existing and emerging HIT standards.
Standardization of Assessment Instruments
The Federal Government could apply current and emergent HIT content and messaging standards to federally-required patient assessment tools. The work undertaken in this project on the MDS gives rise to many recommendations that could be considered in the pursuit of this goal. Specifically, the Federal Government could:
- Create standard, computer-processible versions of patient assessment tools (e.g., the MDS) based on the Clinical LOINC format developed in this project.
- Create and freely distribute software that supports use of LOINC-formatted, federally-required patient assessment tools (such as the MDS) to enable the electronic transmission of needed patient assessment data in standard form by standard means (i.e., in the case of the MDS such software would be a successor to the RAVEN application).
- Include in the freely-available software described above, a link to the usefully related CHI terminology mappings (e.g., identified through this project) so that the developer of the patient assessment forms (in this case CMS) communicates to the public and private sectors the matching standardized terms that it believes are usefully related as such terms are identified.
- Distribute this linked software (i.e., software supporting LOINC-formatting, linked with related standardized terms) as a test set to foster development of standards-based tools and processes within the applicable provider (e.g., nursing home) and software-development communities.
- Equip developers of assessment/survey forms (e.g. refined versions of the OASIS, IRF-PAI, and other assessments required in the DRA) with: (i) tools to place needed patient assessment data into a LOINC format; and (ii) convenient (e.g., Web-based) access to standard vocabularies to promote harmonization whenever possible.
- Support initial testing of such applications to validate, for example, required exchange of:
- the entire assessment forms and results, as well as
- multiple question-answer pairs needed to support
- payment, and
- quality measure/outcome reporting.
- Support pilot projects to evaluate and iteratively deploy increasingly standards-enabled assessment applications. For example, the public and private sectors could support the development of initial coding assistant applications that
- accept standard terms that describe the patient conditions, demographics, etc.,
- suggest potential assessment results based on these descriptions,
- calculate quality/outcome measures based on responses, and/or
- collect feedback regarding utility of assistant functions.
- Engage the CHI-recommended vocabulary developers to identify and fill gaps in the content and utilization of standard vocabularies.
- Replicate the process of integrating content and messaging standards for other federally-required assessment tools and government survey instruments.
- Create and execute a multi-stakeholder governance process, based on continuous improvement principles, for the standards-enabled patient assessment tools, that will:
- Oversee and align interoperable assessment instrument construction, maintenance and deployment;
- Collaborate with standards development organizations;
- Promote public-private partnerships to leverage the cost-reduction and quality-improvement potential of assessment instruments; and
- Measure and report progress toward assessment instrument compliance with Presidential, HHS and Congressional mandates.
In the near term, we recommend the Federal Government consider deploying a process for integrating HIT content and messaging standards with the emerging MDSv3 and the assessments required in Section 5008 of the DRA as follows:
- Represent MDSv3/DRA content in LOINC using lessons learned from the LOINC representation of MDSv2; and
- Re-use the applicable MDSv2 content matches in the emerging MDSv3/DRA content, and conduct additional content matching, including needed subject matter expert review, for the MDSv3/DRA items.
Regarding item re-use across patient assessment instruments (e.g., OASIS and IRF-PAI), and best practices as new health and functional data collection tools are developed, we believe the following activities will facilitate standardization:
- Consider the development of standard information models (e.g., for pain scales, used to enhance utility of standard terminologies). Focus, initially, on items that may be re-used in other patient assessment instruments.
- Search question and answer repositories for any re-usable items.
- Consider the appropriate distribution of content between the question and answer when specifying needed content, and publish any lessons learned.
- Place needed questions and answers into a LOINC format and submit to Clinical LOINC for coding.
- Search HIT vocabularies to identify coded content (e.g., a SNOMED-CT concept) that is usefully related to the items being measured and have possible matches reviewed, as needed, by subject matter experts.
- Work with standard development organizations to address identified gaps in HIT standards.
- Create a freely and publicly available database that supports the standardized exchange of needed content using HLv2+ messaging, Clinical LOINC, and coded content (when available).
Related Technical and Policy Infrastructure Issues
More generally, given the increasing departmental and government focus on the Federal Health Architecture (FHA), the FHA could examine existing and emerging federal mechanisms to implement and maintain HIT content and messaging standards within the federal healthcare enterprise (e.g., at HHS/National Cancer Institute (NCI), VA, etc.). Such analyses could identify commonalities and differences in these processes and encourage the use of processes that maximally support interoperable health information exchange. For example, an issue identified in this study was the need to maintain links between codeable content and LOINC coded questions and answers to support interoperable exchange and re-use of information. Alternative approaches for maintaining these needed linkages that merit further consideration include the feasibility of using the NLMs UMLS to maintain and make available links between codeable content and Clinical LOINC. Other FHA partners have also been leaders on several wide ranging HIT standardization projects, including the NCI Center for Bioinformatics in its caBIO, caDSR and caBIG initiatives. The FHA could consider these and other initiatives to identify mechanism that could be re-used to support implementation of interoperable health information exchange.
This project has also highlighted several additional technical and policy issues that would benefit from review by the FHA partners (e.g., HHS, VA, and Department of Defense). For example the FHA could consider alternative methods of deploying and maintaining HIT standards and identify the methods that could be re-used by Federal Partners to maximize efficient interoperable health information exchange. Issues that the FHA could consider include:
- How will the FHA evaluate the presence of gaps and redundancies in CHI-approved HIT standards (based on this experience with standardizing the MDS and the experiences of other FHA partners)? Will the recently awarded HITSP contract be used to address these issues across the federal healthcare enterprise?
- Should links between federally-required patient assessment content (such as the MDS) and standard content in the NLM UMLS be maintained? If so, what process(es) will be used and who will maintain these links?
- How do FHA partners combine codeable content (i.e., using post-coordination (combined usage) of multiple standard vocabulary elements)? How are standard development organizations (e.g., the HL7 TermInfo effort) addressing issues related to post-coordination?
- What mechanisms support re-use of codeable content by and across FHA partners (e.g., how are definitions of codeable content maintained, and made transparent and re-usable)?
- How do FHA partners exchange and re-use codeable content using standardized messages?
- How do FHA partners integrate HIT content and messaging standards into various patient assessment and survey instruments?
- What role(s) could the NLMs UMLS serve in addressing these and related issues?
In summary, this study has identified:
- a feasible method to integrate HIT content and messaging standards into federally-required patient assessment tools such as the MDS;
- steps that the Federal Government could use to integrate HIT content and messaging standards into patient assessment tools; and
- cross-cutting technical and policy issues that would enhance the infrastructure needed to exchange and re-use information.
Implementation of these recommendations would promote the use of interoperable HIT applications that could improve caregiving and increase administrative efficiencies (e.g., improving quality monitoring, supporting data re-use, etc.). In addition, this study highlights several issues that the FHA could considered as a part of a larger Continuous Quality Improvement that, if implemented, would efficiently promote data standardization, exchange, and re-use.
EXPLANATION OF ATTACHMENTS
The following Attachments are referenced in the text of this report, and are attached for further information:
BIPA, Sec. 545. DEVELOPMENT OF PATIENT ASSESSMENT INSTRUMENTS
"Encoding Nursing Home Resident MDS Observation and Assessment Data: Do HL7 Messaging Standards Support its Transmission?"
Side-by-side depiction of MDSv2 and Content Matching Results
Additional Item Matching (emerging MDSv3 items)
The NLM/UMLS to Maintain Links between LOINC coded Assessment Question and Answers and Codeable Vocabularies -- An Alternative
The specific vocabulary codes that correspond with each of the standardized vocabulary matches identified in Attachment C and Attachment D
REFERENCES
-
"Executive Order -- Incentives for the Use of Health Information Technology and Establishing the Position of the National Health Information Technology Coordinator," April 27, 2004. http://www.whitehouse.gov/news/releases/2004/04/20040427-4.html
-
"Secretary Leavitt Takes New Steps to Advance Health IT." National Collaboration and RFPs Will Pave the Way for Interoperability. HHS Press Release, June 6, 2005.
-
LTC HIT Summit: DRAFT Report of Consensus, Action and Strategy. Prepared by Michelle L. Dougherty, RHIA, CHP, American Health Information Management Association.
-
"An Overview of the U.S. Healthcare System: Two Decades of Change, 1980-2000." Center for Medicare and Medicaid, Office of the Actuary. Baltimore, MD: National Health Statistics Group, 2000.
-
Health Information Technology Leadership Panel -- Final Report.
-
"Long-Term Care: Understanding Medicaids Role for the Elderly and Disabled." Prepared by Ellen OBrien, Georgetown University Health Policy Institute for the Kaiser Commission on Medicaid and the Uninsured. November 2005, p.13.
-
"Long-Term Care Financing: Growing Demand and Cost of Services Are Straining Federal and State Budgets." U.S. Government Accounting Office. Testimony before the Subcommittee on Health, Committee on Energy and Commerce, House of Representatives, p.3, April 27, 2005.
-
Kohn, LT, Corrigan, JM, Donaldson, MS (eds.) To Err is Human: Building a Safer Health System. Washington, DC: National Academy Press, 2000.
-
Annals of Family Medicine. July/August 2004. http://annalsfm.highwire.org/cgi/content/astract/2/4/317.
-
Coleman, E. "Falling Through the Cracks: Challenges and Opportunities for Improving Transitional Care for Persons with Continuous Complex Care Needs." JAGS 51:549-555, 2003.
-
"Improving the Quality of Care in Nursing Homes." IoM, 1986:75-77.
-
§1819 and 1919(b)(3)(A) of the Social Security Act.
-
"Nursing Homes Survey and Certification: Overall Capacity" and " Nursing Homes Survey and Certification: Deficiency Trends" (OIG: OEI-02-98-00330 and OEI-02-98-00331); "Nursing Homes: Additional Steps Needed to Strengthen Enforcement of Federal Quality Standards" (GAO/HEHS-99-46); "Quality of Care in Nursing Homes: An Overview" (OIG: OEI-02-99-00060).
-
MedPAC 2005 Report to Congress. Issues in a Modernized Medicare Program. Chapter 5, p.106.
-
Harris, MR, Chute, CG, Harvell, J, White, A, Moore, T. "Toward a National Health Information Infrastructure: A Key Strategy for Improving Quality in Long-Term Care." May 2003. http://aspe.hhs.gov/daltcp/reports/toward.htm
-
Kramer, A, Bennett, R, Fish, R, Lin, CT, Floersch, N, Conway, K, Coleman, E, Harvell, J, Tuttle, M. "Case Studies of Electronic Health Records in Post-Acute and Long-Term Care." August 2004. http://aspe.hhs.gov/daltcp/reports/ehrpaltc.htm
-
Aday, LA. Designing and Conducting Health Surveys: A Comprehensive Guide, 2nd ed. San Francisco, CA: Jossey-Bass, 1996.
-
Nunnally, JC, Bernstein, IH. Psychometric Theory, 3rd ed. New York, NY: McGraw-Hill, 1994.
-
Costs and Benefits of Health Information Technology. Southern California Evidence-based Practice Center, Santa Monica, CA. Paul Shekelle, MD, PhD, et al., to be published.
-
Walker, J, Pan, E, Johnston, D, et al. "The value of health care information exchange and interoperability." Health Affairs 2005; w5.10.
-
URL: http://endingthedocumentgame.gov/PDFs/ExecutiveSummary.pdf, p.2.
-
URL: http://endingthedocumentgame.gov/PDFs/ExecutiveSummary.pdf, p.2 and 5.
-
NCVHS, Report to the Secretary of the US Department of Health and Human Services on Uniform Data Standards for Patient Medical Record Information, July 6, 2000.
-
LTC HIT Summit: DRAFT Report of Consensus, Action and Strategy. Prepared by Michelle L. Dougherty, RHIA, CHP, American Health Information Management Association.
-
Cimino, JJ. "Desiderata for Controlled Medical Vocabularies in the Twenty-First Century." Meth Inform Med 1998, 37:394-403.
-
"HHS Awards Contracts to Advance Nationwide Interoperable Health Information Technology." Press Release. October 6, 2005.
-
SNOMED License Agreement. http://www.nlm.nih.gov/research/umls/Snomed/snomed_license.html
-
Logical Observation Identifiers Names and Codes Version 2.15. Regenstrief Institute, Indianapolis, IN. June 2005. http://www.regenstrief.org/loinc
-
Bakken, S, Cimino, JJ, Haskell, R, et al. Evaluation of the clinical LOINC (Logical Observation Identifiers, Names, and Codes) semantic structure as a terminology model for standardized assessment measures. J Am Med Inform Assoc. 2000; 7(6):529-538
-
White, TM. Extending the LOINC Conceptual Schema to Support Standardized Assessment Instruments, J Am Med Inform Assoc. 2002; 9(6):586-599.
-
Choi, J, Jenkins, ML, White, TM, Cimino, JJ, Bakken, S. Toward Semantic Interoperability in Home Health Care: Formally Representing OASIS Items for Integration into a Concept-Oriented Terminology. Journal of the Medical Informatics Association 2005; 12(4):410-417.
-
Letter to the Secretary -- Final Recommendations on CHI Domain areas. January 29, 2004. http://www.ncvhs.hhs.gov/040129lt.pdf
-
Thomas White, MD, MS, MA. Director, Bureau of Mental Health Informatics, New York State Office of Mental Health, 330 Fifth Avenue, 9th Floor, New York, NY 10001. Coevtmw@omh.state.ny.us
NOTES
* MDS is organized primarily as a multiple choice questionnaire, and certain questions are only asked in some MDS situations, therefore the exact number of questions actually completed depends on the individual patient circumstances. The MDS form also includes a variety of headings, explanations, examples and other material that lends context to the question being asked. As appropriate, our vocabulary analysis also included these supplements.
ATTACHMENT A: BIPA, Sec. 545. DEVELOPMENT OF PATIENT ASSESSMENT INSTRUMENTS
- DEVELOPMENT--
- IN GENERAL--Not later than January 1, 2005, the Secretary of Health and Human Services shall submit to the Committee on Ways and Means and the Committee on Commerce of the House of Representatives and the Committee on Finance of the Senate a report on the development of standard instruments for the assessment of the health and functional status of patients, for whom items and services described in subsection (b) are furnished, and include in the report a recommendation on the use of such standard instruments for payment purposes.
- DESIGN FOR COMPARISON OF COMMON ELEMENTS--The Secretary shall design such standard instruments in a manner such that--
- elements that are common to the items and services described in subsection (b) may be readily comparable and are statistically compatible;
- only elements necessary to meet program objectives are collected; and
- the standard instruments supersede any other assessment instrument used before that date.
- CONSULTATION--In developing an assessment instrument under paragraph (1), the Secretary shall consult with the Medicare Payment Advisory Commission, the Agency for Healthcare Research and Quality, and qualified organizations representing providers of services and suppliers under title XVIII.
- DESCRIPTION OF SERVICES--For purposes of subsection (a), items and services described in this subsection are those items and services furnished to individuals entitled to benefits under part A, or enrolled under part B, or both of title XVIII of the Social Security Act for which payment is made under such title, and include the following:
- Inpatient and outpatient hospital services.
- Inpatient and outpatient rehabilitation services.
- Covered skilled nursing facility services.
- Home health services.
- Physical or occupational therapy or speech-language pathology services.
- Items and services furnished to such individuals determined to have end stage renal disease.
- Partial hospitalization services and other mental health services.
- Any other service for which payment is made under such title as the Secretary determines to be appropriate.
ATTACHMENT B: ENCODING NURSING HOME RESIDENT MDS OBSERVATION AND ASSESSMENT DATA: DO HL7 MESSAGING STANDARDS SUPPORT ITS TRANSMISSION?
1. Background
Apelon, Inc. has been tasked by the U.S. Dept. of Health and Human Services (HHS) to explore standard terminology representations of the content in its Minimum Data Set (MDS) Version 2.0 for Nursing Home Resident Assessment and Care Screening survey instrument. SNOMED-CT1 has been proposed as a candidate standard terminology that can capture and encode most of the clinical concepts expressed in the questions and responses from the MDS survey. Often, however, several SNOMED-CT concepts must be combined or post-coordinated to represent more complex MDS meanings accurately. SNOMED-CT appears to have many of the required nouns or adjectives (concepts, qualifiers, and modifiers), and verbs or linkage concepts (associations, role-relationships) to construct these complex expressions.
If post-coordinated terminological expressions are indeed required to encode and to adequately represent portions of the MDS content, can such encoded data then be communicated electronically from nursing home systems to the HHS by accepted Health Level 7 (HL7) standard messages? Does Version 2.5 of the HL7 Standard for electronic data exchange in healthcare environments,2 the latest ANSI-standard release, support transmission of these messages? Would enhancements proposed in the HL7 Version 3.0 draft standard provide a better solution? This document researches answers to these questions.
2. HL7 Version 2.5 Message Standards
HL7 Version 2.5 specifies an extensive collection of standard messages and exchange protocols for electronic healthcare data exchange. Messages consist of a group of required or optional message segments in a defined sequence, which together conveys specific types of information (admission/ discharge/transfer, financials, pharmacy reporting, orders, observations, and so on). Certain message segments can be reused in many different types of messages to transmit data for a particular domain (e.g., results of observations). Message segments themselves contain logical groupings of required or optional data fields, which are delimited strings of characters, constrained as pre-defined datatypes. Figure 1 illustrates some of these building blocks for a HL7 Version 2.5 message for observational reporting.
Datatypes relevant for the transmission of coded data (generic or post-coordinated) are the Coded Element (CE) datatype and its specializations: Coded with No Exceptions (CNE) and Coded with Exceptions (CWE). The latter two differentiate whether the set of available codes for a particular sub-domain is a closed world or open to local additions. For example, the OBX-3 field in Figure 1 is a CE datatype.
| FIGURE 1. Components of a HL7 Version 2.5 Message for Observational Reporting |
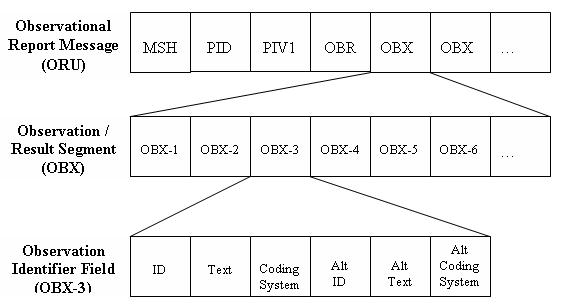 |
The CE and related datatypes consist of up to 6 components, delimited by ^ in the actual message stream. The following table describes these components in more detail.
| CE Datatype Component | CE Component Description | Sample Value |
| Identifier | Specific code from coding system | 44950 |
| Text | Text equivalent of code | Appendectomy |
| Name of Coding System | HL7 ID of coding system | CPT |
| Alternate Identifier | Alternate code from other coding system | P1-57450 |
| Alternate Text | Text equivalent of alternate code | Appendectomy, NOS |
| Name of Alternate Coding System | HL7 ID of alternate coding system | SNM |
For example, to encode an appendectomy using CPT in an HL7 Version 2.5 message, one would use a Coded Element (CE) datatype to transmit the proper CPT code for an appendectomy, its text name, and an HL7-designated ID for the CPT coding system. Generally, only these first three components are required, and some of them may be optional in selected message field usage.3 The last column of the above table also demonstrates how the final three components would be used to transmit a synonymous code, here mapping the primary code from CPT to an alternate code in legacy SNOMED International.
2.1 Observation/Result Segment (OBX)
Although structured, patient-oriented clinical data can be transmitted within several HL7 message types for different purposes (medical document management, results reporting, clinical trials, etc.); all such message types use the Observation/Result Segment (OBX) to transmit each individual clinical observation, the smallest indivisible unit of a report. Numerous OBX segments must be assembled to send all the observations in a report. They can be bundled into explicit panels or batteries of observations (e.g., electrolytes, vital signs, or sections of a survey) by following a shared header, an Observation Request Segment (OBR). Clinical data to be sent via OBX segments include, but are not limited to, patient history and physical, consultations, operative reports, discharge summaries, pathology reports, imaging reports, laboratory results, waveform results (EKG), and survey results.
The OBX segment contains up to 19 fields (full discussion beyond the scope of this document). Most relevant to the encoding of MDS content are the three OBX fields listed next, which are numbered by their position in that message segment:
| Field Number | Field Name | Field Description |
| OBX-2 | Value Type | Datatype of the result value in Field #5 |
| OBX-3 | Observation Identifier | ID or code naming the observation |
| OBX-5 | Observation Value | Observed value for named observation |
The OBX-3 Observation Identifier encodes the name of the thing observed (e.g., Serum sodium, Diastolic BP, Pain Site, etc.) via a single code from some master observation table or an external coding system, such as LOINC.4 The use of identifiers from external, authoritative coding systems or terminologies improves interoperability across healthcare sites. OBX-3 is always an instance of the CE (coded element or entry) datatype.
Although a limited set of identifier code suffixes (e.g. &IMP for diagnostic impression, &ANT for anatomy, and so on) have been defined by HL7 for post-coordination with OBX-3 codes, the OBX-3 field does not allow the ID of an observation (e.g., an MDS survey question) to be an arbitrary, post-coordinated expression of codes. Complex concepts must therefore be pre-coordinated, single entities in the master observation table or external coding system, per HL7 Version 2.5 standards.5
The OBX-5 field contains the resulting value for that observation identified by OBX-3. Although OBX-5 values can be transmitted as any suitable datatype, HHS MDS project requirements mandate that they be coded data. Encoded OBX-5 observation values must be flagged with a CE value, denoting a coded element or entry, in the OBX-2 value type field. HL7 allows code values from multiple external coding systems, including all HIPAA and CHI designated terminologies. Since each logically-independent observation must be reported in a separate OBX segment, batteries or panels of observations (e.g., Vital signs) would consist of multiple OBX segments.
However, the HL7 Version 2.5 specification for OBX-5 does permit post-coordination of codes that together describe a modified or qualified value for a single, logically independent observation result value. It does so by permitting repeating OBX-5 fields within a single OBX message.
Though two independent diagnostic statements cannot be reported in one OBX segment, multiple categorical responses are allowed (usually as CE datatypes separated by repeat delimiters), so long as they are fragments (modifiers) that together construct one diagnostic statement. Right upper lobe (recorded as one code) and pneumonia (recorded as another code), for example, could be both reported in one OBX segment. Such multiple values would be separated by repeat delimiters.6
Although the HL7 Version 2.5 standard does not specify a grammar for associating or combining repeating codes, certain healthcare terminologies (e.g., SNOMED-CT) provide linkage concepts in order to build post-coordinated expressions. Receiving applications must be able to process these messages and be programmed to assemble sequential codes correctly.
The next example, taken from the HL7 documentation, illustrates an HL7 Version 2.5 OBX message stream which incorporates both an encoded, post-coordinated observation value (OBX-5), as well as a suffix tag to modify the meaning of the observation identifier (OBX-3). Message segment fields are delimited by the | character. The OBX segment fields of interest are highlighted.

A LOINC code (24646-2) serves as the OBX-3 observation identifier, encoding the observation name as a diagnostic impression of a PA and lateral chest X-ray. The OBX-3 CE field consists of 3 (^ delimited) components: the 1st (ID) containing a hyphenated LOINC code plus an IMP[ression] suffix tag, the 2nd (text) displaying an abbreviated LOINC name for this chest X-ray, while the 3rd (coding system ID) designates LOINC itself. The OBX-5 observation value field, a coded element according to OBX-2, contains two post-coordinated codes, both from the ACR (American College of Radiology) coding system, which are separated by a field repeat (~) delimiter. Post-coordination permits encoding of the concept Right Upper Lobe Bronchopneumonia via a simple serialization of ACR codes .61 and .212
To reiterate a key issue for MDS encoding, although the OBX-5 observation value permits repeating occurrences to build a fully-specified, post-coordinated result, the OBX-3 field does not. Each OBX-3 observation identifier must be a single code, uniquely identified in some HL7 or local master table, or an authoritative external coding system.
The LOINC coding system has become the de facto external standard system for OBX-3 identifier codes, such that several organizations have submitted their nursing surveys for inclusion in and encoding by LOINC. Items from these nursing instruments are labeled as instances of the Survey classtype with a suitable LOINC class value, an officially-assigned LOINC code, and an optional list of valid answers. The latest LOINC Version 2.15 has the following short list of classes within the Survey classtype, each containing numerous LOINC-encoded items:
| LOINC Class | Description |
| SURVEY.NURSE.HHCC | Home Health Care Classification Survey |
| SURVEY.NURSE.HIV-SSC | Signs and Symptoms Checklist for Persons with HIV Survey |
| SURVEY.NURSE.LIV-HIV | Living with HIV Survey |
| SURVEY.NURSE.OMAHA | OMAHA Survey |
| SURVEY.NURSE.QAM | Quality Audit Marker Survey |
For example, the following table shows several LOINC-encoded items from the Home Health Care Classification (HHCC) survey instrument. Each item happens to have the same ANSWERLIST attribute value, the set of valid values expected for results, namely: IMPROVED, STABILIZED, DETERIORATED.
| LOINC Code | Fully-specific LOINC Name |
| 28079-2 | ACTIVITIES OF DAILY LIVING ALTERATION: FIND:PT:^PATIENT:ORD:OBSERVED.HHCC |
| 28080-0 | ACTIVITY ALTERATION:FIND:PT:^PATIENT:ORD:OBSERVED.HHCC |
| 28081-8 | ACTIVITY INTOLERANCE:FIND:PT:^PATIENT:ORD:OBSERVED.HHCC |
| 28082-6 | ACTIVITY INTOLERANCE RISK:FIND:PT:^PATIENT:ORD:OBSERVED.HHCC |
| 28083-4 | ACUTE PAIN:FIND:PT:^PATIENT:ORD:OBSERVED.HHCC |
| 28191-5 | POISONING RISK:FIND:PT:^PATIENT:ORD:OBSERVED.HHCC |
Constrained by limitations of the current HL7 Version 2.5 standard, HHS could designate its MDS survey instrument items as coded value sets for a master HL7 observation table or for incorporation in future versions of the LOINC coding system. In either case, each MDS survey item would receive a unique code suitable for the OBX-3 observation identifier field.
MDS survey items and their codes could also be assigned officially-maintained external mappings to post-coordinated SNOMED-CT expressions, which then define and deconstruct their meanings in terms of more atomic SNOMED-CT reference terminology concepts. Although not transmitted as part of an HL7 message, those mappings should be published and could be used by recipient and HHS systems for data analytic and aggregation purposes.
Since the OBX-5 observation value field already permits post-coordinated codes, a SNOMED-CT-based solution for results reporting can already be provided with the current HL7 Version 2.5 messaging standard.
2.2 Clinical Data Architecture (CDA) Document
The HL7 Clinical Data Architecture (CDA) Release 1.07 is a document markup standard that specifies the structure and semantics of clinical documents for exchange purposes. It subdivides documents into meaningful, tagged chunks of information and provides a template for structuring computably-valid instances of a clinical document. Although derived from early versions of HL7 Version 3 Reference Information Model (RIM) and Abstract Data Types draft standards, CDA has already achieved ANSI-standard certification. Some of its constructs transition between the two HL7 versions.
Clinical CDA documents are complete information objects encoded in EXtensible Markup Language (XML)8 and may include multimedia content. At the present time, they can be a MIME-encoded payload within an HL7 Version 2.5 message. For example, an HL7 Version 2.5 OBX observation segment can contain a complete CDA document as the OBX-5 observation value, flagged by an OBX-2 value of ED (Encapsulated Data) and by other means.
At the risk of simplifying the CDA too greatly, the
of a CDA document consists of nested- ,
- ,
and/or other XML markup elements, as specified by a formal CDA document type description (DTD) developed by HL7.
and elements can be used to markup and encode clinical content from a variety of domains. The element inserts codes from HL7-recognized coding schemes into CDA documents. A element can explicitly reference the original text within the document that is being encoded. Vocabulary domains provide the value sets for CDA-required coded attributes, as well as optional
elements. Value sets can be HL7-specified concepts or defined subsets of recognized external coding systems such as LOINC or SNOMED-CT. HL7 assigns a unique identifier to each vocabulary domain, and every concept within such a domain must have a unique code. The following example, taken from the CDA specification, illustrates concept coding in a CDA document. A sample problem-oriented medical record section has a
element, which provides the LOINC code (V=code value S=coding system ID) for the element value Assessment. The Assessment record consists of a - of three
- elements, but only the first has coded
. A element provides the SNOMED International code for Asthma, text marked up by the previous element which assigned it an internal ID=String001.
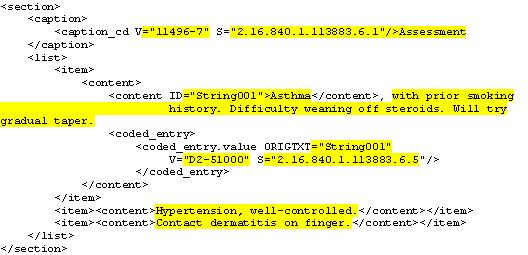
The CDA framework permits multiple
elements for , with the original text marked up or not. It is our understanding that relevant HL7 Version 3 coded datatypes will also permit post-coordinated codes.9 Extrapolating from this example, the MDS survey could be represented as a collection of tables. An MDS question, as the
element in the first column of such a table, might use a LOINC element to encode it in its entirety, with portions of its optionally marked up and further encoded by SNOMED-CT. The MDS answers or results, as a - of
- in the second column of the CDA table, would have its
marked up and encoded by SNOMED-CT elements.
3. HL7 Version 3.0 Message Standards
HL7 Version 3.0 remains a draft standard at this writing. Unlike HL7 Versions 2.x, which have evolved for more than a decade via a "bottom-up" approach permitting extensive optionality, Version 3.0 is being developed using a Reference Information Model (RIM) for data and a top-down object-oriented methodology to create concise, testable, well-defined messages. The RIM provides an explicit representation of the semantic and lexical connections existing between the information to be carried in implemented HL7 messages. Due to its complexity and on-going evolution, even a cursory overview of HL7 Version 3.0 is well beyond the scope of this document. HL7 members can obtain the latest draft versions of the HL7 Version 3.0 RIM, the Abstract Data Type Specification, and the Data Type Implementable Technology Specification for XML at Members Only portions of HL7s official web site (http://www.hl7.org>)|[g2].|
HL7 Version 3.0, when approved and fully-implemented, should be capable of meeting HHS MDS encoding and messaging requirements. Using the Concept Descriptor (CD) datatype, it will permit post-coordinated encoding of both observation identifiers and actual values. Detailed rules and policies for post-coordination semantics are still under development by HL7 committees. Nevertheless, one can glimpse how the HL7 Version 3.0 RIM and concept descriptor datatype will address post-coordinated encodings.
HL7 committees and other organizations have formalized the notion of a version 3.0 Clinical Statement as an expression of a discrete item of clinical information and its context, as relevant to a specific patient. Clinical statement patterns provide a common structural framework and model, derived from specified classes and attributes in the RIM (e.g., Act, Encounter, Observation, etc.) and connected by Statement Relationship linkages, to express detailed clinical content. Encoded concepts for content in HL7 clinical statements can be taken from a clinical reference terminology such as SNOMED-CT, which permits complex, post-coordinated expressions.
Clinical content, including observation identifiers and observation values, can be transmitted as instances of the Concept Descriptor (CD) abstract datatype in HL7 Version 3.0 messages. Like Version 2.5 legacy CE datatypes, the CD datatype can transmit a code (e.g., a SNOMED-CT conceptID), the name of the coding scheme for that code, a display name for the code, and optional synonyms, as well as the original text being encoded. The Version 3.0 CD datatype builds on the CE with a grammar for post-coordinating codes from a terminology to create a new concept. The Concept Descriptor grammar allows the assignment of modifiers, specifically: named roles and their values, where values themselves can be further modified.
The following SNOMED-supplied examples illustrate how two closely related surgical procedure concepts can be transmitted in HL7 Version 3.0 XML
messages using CD datatyped elements to express post-coordinated SNOMED-CT encodings. In the first example, the
class element has an element transfrontal approach which is logically ANDed10 with the primary concept descriptor element hypophysectomy to express the desired post-coordination. The original concept hypophysectomy by transfrontal approach thereby encoded is also captured by a element. 
The next example shows another method of post-coordination supported only by the full CD datatype. The primary concept descriptor
element itself has been further modified with a SNOMED-coded role name and value, thereby altering that to become an incision of a brain lesion, where lesion is the value of the DIRECT-MORPHOLOGY role modifying brain incision. SNOMED-CT concept representation semantics guide the choice of roles and values used to construct post-coordinated concepts. Also, as in the previous example, the message specification allows an additional element pituitary posterior lobe which is also logically ANDed with the modified primary concept descriptor element to express the fully post-coordinated, encoded concept. Here again, the original concept is captured by the element incision of lesion of posterior lobe of pituitary gland. 
By analogy, one can envision how MDS nursing survey observations and results could also be transmitted as HL7
or other clinical statement messages via post-coordinated encodings of SNOMED-CT through concept descriptor datatypes. These examples also suggest the need for HL7 efforts that are still on-going to clarify and specify how to ensure unambiguous semantics for post-coordinated encoding. References
-
SNOMED Clinical Terms. SNOMED International, July 2005. http://www.snomed.org/snomedct/>.
-
Health Level Seven Version 2.5 Final Standard, July 2003. http://www.hl7.org>.
-
In certain instances, a CE datatype can even transmit uncoded free-text data. However, our focus is on the transmission of coded data from standard terminologies.
-
Logical Observation Identifiers Names and Codes Version 2.15, Regenstrief Institute, Indianapolis, IN, June 2005. http://www.regenstrief.org/loinc/>.
-
Personal communications with Drs. Clem McDonald and Stan Huff, August 2005.
-
Health Level Seven Version 2.5 Final Standard. July 2003, pp. 7-47. http://www.hl7.org>.
-
Health Level Seven Version 3 Standard: Clinical Data Architecture Release 1.0. November 2000. http://www.hl7.org>.
-
Extensible Markup Language (XML). World Wide Web Consortium. http://www.w3.org/XML/>.
-
Personal communication with Dr. Stan Huff, August 2005.
-
HL7 Version 3 RIM-based specification of the
element defines a semantically-suitable set of optional concept descriptor elements for procedures, such as approach site or target site, to be logically AND'ed with the primary concept descriptor.
ATTACHMENT C: MDS TERM MATCHES AND REVIEWER FEEDBACK
Because of its large size, this attachment is current available only as a PDF document at http://aspe.hhs.gov/daltcp/reports/2006/MDS-HIT-C1.pdf.
ATTACHMENT D: ADDITIONAL ITEM MATCHES FOR SAMPLED MDSv3
This attachment is current available only as a PDF document at http://aspe.hhs.gov/daltcp/reports/2006/MDS-HIT-D.pdf.
ATTACHMENT E: THE NLM/UMLS TO MAINTAIN LINKS BETWEEN LOINC CODED ASSESSMENT QUESTION AND ANSWERS AND CODEABLE VOCABULARIES -- AN ALTERNATIVE
In order for the NHIN to reliability and reproducibly exchange assessment content, it must have ways to (a) uniquely code questions, answers, and answers + questions, and (b) represent the relationship between any of those codes and other CHI endorsed vocabularies. One logical solution for (b) is to use the UMLS, since its Metathesaurus is designed to maintain such relationships, and UMLS is the only authorized distributor of SNOMED codes. Relationships in UMLS are represented at either the Concept or Atom levels. The text of survey items is currently stored within the UMLS as Attributes, so the content needed for (a) is already present within the UMLS, but since they are not stored as Atoms, they can not be used within relationships. Two possible solutions are to (1) extend UMLS to allow the survey questions, answers, and answers + questions to be represented as Atoms, or (2) extend UMLS to support relationships at the Attribute level. Since both proposed solutions involved changes to the UMLS, their potential ramifications would need to be carefully considered.
Although there is precedent for multiple Atoms for a single LOINC item, the lack of associated metadata may make this a non-ideal solution. TABLE 1 shows two Atoms for the LOINC code 28083-4. The String is a concatenation of the 6 main LOINC axes; and there are Atom Unique Identifiers (AUIs) for the full and abbreviated text versions of those six LOINC axes.
TABLE 1: Sample Data from UMLS MRCONSO Table Showing Unique Concepts and Their Associated String Description CUI LUI SUI AUI LOINC String C0943734 L1841898 S2144660 A2000256 28083-4 ACUTE PAIN:FINDING:POINT IN TIME:^PATIENT:ORDINAL:OBSERVED.HHCC C0943734 L1841897 S2144659 A2000255 28083-4 ACUTE PAIN:FIND:PT:^PATIENT:ORD:OBSERVED.HHCC A single LOINC code has a single concept (CUI), but may have multiple String representations and string identifiers (SUI). The UMLS Attribute Table already stores components of survey items needed for mapping to other vocabularies. TABLE 2 shows a subset of those attributes for LOINC code 28083-4, AUI A2000255. The Survey Question Text, Source, and AnswerLists are stored as distinct Attributes, as are the fields from the six primary LOINC axes. Although the LOINC Answer List (LAL) attribute is not as granular as would be needed to represent unique Questions, Answers, and Answers + Questions, UMLS might consider updating the LAL syntax to allow for that granularity. This might be done by adding a new Attribute Name (ATN) to indicate the questions and answers, with one record for each. Presuming that LOINC adopts the proposal for unique tables of Q, A, and Q+A levels, it would have its own unique identifiers for those strings. UMLS would then treat these as Source Asserted Attribute Identifiers (SATUIs), and include them in the Attribute table structure. If such an approach were used, UMLS could use ATUI codes to represent the unique questions, answers, and answers+questions, and relationships to other vocabularies could be done at that level. However, Attributers are not currently included among the unique Strings and Atoms, so such an approach would not take advantage of the UMLS's ability to identify ambiguous strings. Perhaps a mixed solution, of storing this content as Attributes, but also letting Attributes be included within the Strings table might solve that problem, but such a proposal is beyond the scope of this project.
TABLE 2: Sample Data from UMLS MRATT Table Showing Extended LOINC Attributes Associated with a Single LOINC Code ATUI ATN (Attribute Name) SATUI ATV (Attribute Value) AT28331085 LAL (AnswerList) IMPROVED, STABILIZED, DETERIORATED AT28398053 LCL (Class) SURVEY.NURSE.HHCC AT28582102 LOINC_COMPONENT ACUTE PAIN AT28605219 LOINC_METHOD_TYP OBSERVED.HHCC AT28636817 LOINC_PROPERTY FIND AT28671631 LOINC_SCALE_TYP ORD AT28705795 LOINC_SYSTEM ^PATIENT AT28728565 LOINC_TIME_ASPECT PT AT28744038 LQS (Survey Question Source) HOME HEALTH CARE CLASSIFICATION Q45.1 AT28780799 LSR (Survey Question Text) 0 AT28822964 SOS (Scope Statement) PHYSICAL SUFFERING OR DISTRESS, HURTING Storing Vocabulary Matches within LOINC
Regardless of where the unique identifiers for survey components are stored, ones will be needed to support vocabulary matches. Anticipating this, Dr. White proposed that the LOINC committee create their own identifiers for these strings, and encode them within the structured AnswerLists so that computer systems could readily match LOINC answers to other vocabularies, and also use these when transmitting HL7 messages. This proposal would need to be reviewed by LOINC, HL7, CMS, UMLS, and possibly other stakeholders.
The proposal is to have LOINC use syntax for the AnswerLists which facilitates creation of HL7 messages. As described previously, the OBX-5 segment would transmit the response to a survey item, using the syntax Value^Message^Coding_System followed by AlternateValue ^AlternateMessage^AlternateCodingSystem. The Message section is free text, and optional, but Dr. White proposes that LOINC and HL7 add a sub-syntax to it. For example, answer 2 for MDS question B4 could be transmitted as:
OBX|5|CE|2^[???] MODERATELY IMPAIRED-decisions poor, cues/supervision required^LN.
Thus, the Message would have the sub-syntax [AQUID] Original_Message. This AQUID would be the identifier at the level of Answer within context of Question, and Original Message would be that Answer. Supporting tables within LOINC or elsewhere would maintain the mapping of that AQUID to the unique identifiers at the Answer and Question levels, thereby supporting relationships to other vocabularies. Logistically, it may make sense for LOINC to maintain its own unique coding system for AQUID. These might then become the Source Attribute Unique Identifier (SATUI) or related code within UMLS.
This approach would not impose any additional burden on instrument authors. They would simply need to create instruments using an approach compatible with the LOINC syntax. The LOINC group would run the algorithms to determine whether the questions, answers, and answers within the context of questions had been previously used; determine the proper AQUID for each answer choice, and store the original content and AQUID within the AnswerList structure.
This approach also eliminates much of the burden of generating properly formed HL7 messages. The LOINC AnswerList syntax would already include the properly formed OBX-5 segment for the LOINC component of the response. The presence of the AQUID would facilitate identification of mappings to other vocabularies.
Such an approach would support the administrative simplification goal. Since LOINC would store unique identifiers for all possible answers to survey questions within the formatted AnswerList syntax, computer systems could retrieve all known semantic matches to those answers within other vocabularies, such as a set of relevant SNOMED codes. The computer system could search for those SNOMED codes within the electronic health record. If some were found, the computer system would then be able to construct proper HL7 messages for that content by concatenating the LOINC AnswerList syntax and the identified SNOMED or related terms as alternate codes. A similar approach could be used to transmit alternate codes for the OBX-3 segment.
ATTACHMENT F: SPECIFIC VOCABULARY CODES
Because of its large size, this attachment is current available only as a PDF document at http://aspe.hhs.gov/daltcp/reports/2006/MDS-HIT-F.pdf. This attachment is also available as an Excel file at http://aspe.hhs.gov/daltcp/reports/2006/MDS-HIT-F.xls.
- elements, but only the first has coded