
U.S. Department of Health and Human Services
The Effect of State Community Rating Regulations on Premiums and Coverage in the Individual Health Insurance Market
Bradley Herring and Mark Pauly
National Bureau of Economic Research
August 2006
PDF Version (25 PDF pages)
This report was prepared under contract #HHS-100-03-0022 between the U.S. Department of Health and Human Services (HHS), Office of Disability, Aging and Long-Term Care Policy (DALTCP) and the MEDSTAT Group. For additional information about this subject, you can visit the DALTCP home page at http://aspe.hhs.gov/_/office_specific/daltcp.cfm or contact the ASPE Project Officer, John Drabek, at HHS/ASPE/DALTCP, Room 424E, H.H. Humphrey Building, 200 Independence Avenue, S.W., Washington, D.C. 20201. His e-mail address is: John.Drabek@hhs.gov.
The authors thank Robert Krasowski at the National Center for Health Statistics Research Data Center for assistance with accessing the restricted-use NHIS data and Niels Rosenquist for helpful research assistance. They also thank John Drabek, Bill Marder, Kosali Simon, and seminar participants at the 2005 AcademyHealth ARM, the 2005 iHEA, and the 2006 AHEC at MUSC for helpful comments. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research (NBER) or any funding organization. This paper was submitted to NBER as Working Paper #12504 (http://www.nber.org/papers/w12504).
TABLE OF CONTENTS
- I. INTRODUCTION
- A. Background
- B. Previous Literature
- C. Our Analysis
- II. EMPIRICAL MODEL
- A. Overview
- B. Empirical Model
- C. Data
- D. Estimating Expected Expense
- E. Categorizing State Regulations
- III. RESULTS
- A. Main Results
- B. Results by Regulation and Income
- C. Examining the Effect of Health Risk on Coverage
- IV. CONCLUSION
- LIST OF TABLES
- TABLE 1: Full Regression Results for Premiums and Coverage in the Individual Market: All U.S. States
- TABLE 2: Regression Results for Risk on Premiums and Coverage in the Individual Market: Unregulated Versus Regulated States
- TABLE 3: Regression Results for Risk on Premiums and Coverage in the Individual Market: Low-Income Versus High-Income in Unregulated States
- TABLE 4: Results for Risk on Coverage in the Individual Market Unregulated Versus Regulated States
ABSTRACT
Some states have implemented community rating regulations to limit the extent to which premiums in the individual health insurance market can vary with a persons health status. Community rating and guaranteed issues laws were passed with hopes of increasing access to affordable insurance for people with high-risk health conditions, but there are concerns that these laws led to adverse selection. In some sense, the extent to which these regulations ultimately affected the individual market depends in large part on the degree of risk segmentation in unregulated states. In this paper, we examine the relationship between expected medical expenses, individual insurance premiums, and the likelihood of obtaining individual insurance using data from both the National Health Interview Survey and the Community Tracking Study Household Survey. We test for differences in these relationships between states with both community rating and guaranteed issue and states with no such regulations. While we find that people living in unregulated states with higher expected expense due to chronic health conditions pay modestly higher premiums and are somewhat less likely to obtain coverage, the variation between premiums and risk in unregulated individual insurance markets is far from proportional; there is considerable pooling. In regulated states, we find that there is no effect of having higher expected expense due to chronic health conditions on neither premiums nor coverage. Overall, our results suggest that the effect of regulation is to produce a slight increase in the proportion uninsured, as increases in low-risk uninsureds more than offset decreases in high-risk uninsureds. Community rating and guaranteed issue regulations produce only small changes in risk pooling because the extent of pooling in the absence of regulation is substantial.
| Bradley Herring Department of Health Policy and Management 1518 Clifton Road, NE Atlanta, GA 30322 bradley.herring@emory.edu | |
| Mark V. Pauly Health Care Systems DepartmentUniversity of Pennsylvania208 Colonial Penn Center3641 Locust Walk Philadelphia, PA 19104-6218 pauly@wharton.upenn.edu | National Bureau of Economic Research 1050 Massachusetts Avenue Cambridge, MA 02138 |
I. INTRODUCTION
A. Background
Although the vast majority of privately-insured people in the United States obtain their coverage in the employment-based group market, there are currently about 13 million people insured in the individual health insurance market. However, there is much uncertainty regarding how this market actually functions, particularly in regard to premiums paid by those in poor health status due to chronic health conditions and possible effects on their access to coverage. The conventional wisdom is that, while those in poorer health have a higher demand for insurance, medical underwriting by insurers screens out many high risks from obtaining individual insurance and results in relatively higher premiums for those who do obtain coverage. However, the extent to which risk segmentation actually occurs in unregulated health insurance markets is empirically unknown.
As a result of this perception of harm to high-risk persons in unregulated markets, some states have implemented community rating and guaranteed issue laws in the late 1980s and early 1990s, as policymakers hoped to make coverage more affordable and attractive to high-risk persons. However, these regulations may have ultimately led to adverse selection. Mandating that premiums for a given health insurance plan cannot vary with health status may result in low-risk people enrolling in less-generous plans and high-risk people enrolling in more-generous plans (Rothschild and Stiglitz, 1976). As a result, the premiums that people pay would in the end still reflect their own health status. Moreover, such policies may also lead to relatively more uninsured as those in good health may simply wait until becoming sick to obtain coverage.
The individual market is currently receiving increased interest as policymakers consider ways to expand insurance coverage to the uninsured in the United States, estimated to number 45.8 million in the 2004 Current Population Survey. Many advocate the use of tax credit subsidies towards the purchase of individual insurance. The desirability of using individual insurance to expand coverage to the uninsured depends, in part, upon the degree to which persons of varying health status actually obtain coverage and pay pooled premiums in this market.
B. Previous Literature
Existing studies of the individual market do not show high levels of risk segmentation in earlier years, but are not conclusive on this matter. Pauly and Herring (1999) examined individual market premiums in the 1987 National Medical Expenditure Survey (NMES) and found that premiums did increase with increases in risk due to age and gender, but that the increase was less than proportional. Controlling for age and other demographic variables, they did not detect a significant relationship between expected expense due to chronic health conditions and premiums paid, although low sample size may have prohibited them from observing a relationship. Herring and Pauly (2001) examined individual market premiums in the 1996-1997 Community Tracking Study Household Survey (CTS-HS) and did not detect a significant effect of poor health on premiums paid either, although that years survey only contained self-reported health status (i.e., excellent, very good, good, fair, or poor). Hadley and Reschovsky (2003) used the 1998-1999 CTS-HS containing information on several chronic health conditions and found that, controlling for age and gender, those with chronic conditions paid somewhat higher premiums. Marquis and Beeuwkes-Buntin (forthcoming) examined individual market premiums from California and also found that those with chronic conditions paid higher premiums. However, neither the Hadley and Reschovsky study nor the Marquis and Beeuwkes-Buntin study produced an estimate of the magnitude of the effect on premiums relative to higher expected medical claims. Moreover, none of this prior work explored in detail the effect of regulation on the relationship between premiums and risk.
Several studies have examined the effect of community rating regulations in the individual market on the overall likelihood of obtaining any coverage using the Current Population Survey by employing a difference-in-difference approach to examining the staggered implementation of the laws in the late 1980s and early 1990s. These include Sloan and Conover (1998), Chollet et al. (2000), Percy (2000), and Buchmueller and DiNardo (2002). These studies showed either no change or a small decrease in overall coverage rates for the individual market as the result of implementing community rating regulations, and no effect or a small increase in coverage rates for high risks.
LoSasso and Lurie (2005) applied a similar difference-in-difference approach to the 1990-2000 Survey of Income and Program Participation and explicitly showed reductions in coverage for younger people with excellent self-reported health status offset by increases in coverage for older people in poor self-reported health; they found no changes in coverage overall. There has been a similar group of papers examining the effect of reforms in the small group market for employer-based coverage with generally mixed results as well; for instance, Davidoff et al. (2005) found this substitution of low-risk for high-risk workers as a result of states implementing small group reforms.
C. Our Analysis
Our paper contributes to this literature on health insurance markets in three important ways. First, we examine the effect of being high-risk on premiums in the individual market in a way that measures the magnitude of the effect and compares it to the increase in expected benefits for that risk class. This permits a measure of the extent of risk segmentation in this market; we can tell not only whether it exists but, if it does, whether it is large or small. In doing so, we treat the decision to obtain insurance as endogenous by modeling a two-stage model for coverage and premiums paid, similar in spirit to Hadley and Reschovsky (2003). Second, we examine the effect of community rating and guaranteed issue regulations on premiums in the individual market; the direct effect of these regulations on the cost of coverage has, to our knowledge, not been explored. Finally, we examine the effect of these individual market regulations on the likelihood of obtaining insurance coverage, for high-risks and for the overall population, by incorporating detailed data for high-risk chronic conditions.
II. EMPIRICAL MODEL
A. Overview
Our primary empirical model examines premiums in the individual market as a function of expected medical expenses. Since it is likely that health status affects the decision to obtain individual insurance, a simple model examining the relationship between premiums actually paid and health status may lead to biased results for health status. The bias could go either way. If people who are higher risks than they appear in available measures are more likely to obtain insurance, the relationship between measured risk and premiums will understate the true relationship. Conversely, if people who are higher risk than they appear are denied coverage though underwriting, the relationship between risk and premiums will be understated. We therefore use a two-stage model, where the first-stage of our model predicts the likelihood of purchasing a plan in the individual market and the second-stage examines the censored sample of observed premiums (Heckman, 1979). In Section II.B of the paper, we outline the specification of this two-stage model and, in Section II.C, we describe the data used to estimate our model. We then describe, in Section II.D, our methodology for producing an estimate of expected medical expense, which is the key independent variable in our joint model for premiums and whether a household obtains insurance. We then discuss our categorization of state-level regulations in the individual market in Section II.E. We estimate our joint model of premiums and insurance choice for samples of unregulated and regulated states separately and compare our estimated coefficients for expected expense between the two samples. We also split these samples by the income level of the household to examine potential differences in the affordability of coverage (Bundorf and Pauly, 2004; Bundorf et al., 2005).
B. Empirical Model
We use a sample of policyholders of individual health insurance to examine a regression model for the log of the premium as follows:
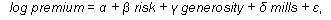 | (1) |
where risk is a measure of expected medical expense, generosity is a measure of the attributes of the insurance plan, and mills is the inverse Mills ratio produced from an equation for the selection of this observed sample of actual premium transactions (Heckman, 1979). The selection equation for the likelihood of whether the household obtains individual insurance is
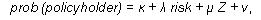 | (2) |
where Z is a set of variables related to whether the household obtains insurance but not included in equation (1) for premiums. (The Heckman specification, of course, allows for correlations of the error terms in these equations, 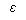 and
and 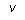 , by inclusion of the Mills ratio.)
, by inclusion of the Mills ratio.)
One measure we use to identify the first-stage equation for obtaining coverage is the local-level availability of charity care; Herring (2005) has shown that the availability of charity care to the uninsured results in a reduction in the likelihood of being insured, due to the disincentive it causes towards purchasing private coverage. Specifically, we use a binary variable for whether either a community health center or a public hospital exists in the county; these data are available from the Area Resource File and American Hospital Association, respectively. A second measure that we use to identify the first-stage equation for obtaining coverage is the education level for the family.
C. Data
We use two similar data sets to estimate the above joint model for premiums and coverage in the individual health insurance market. We use two different data sources to be relatively more confident in our findings if we observe consistent results. The first data set is the nationally representative National Health Interview Survey (NHIS). The NHIS samples about 40,000 households per year, and data for health insurance premiums have been collected since 1999. We use NHIS data from years 1997-2004, and we have accessed the restricted-use NHIS data with county-level identifiers at the National Center for Health Statistics Research Data Center.1 (Local-level identifiers are necessary to link observations with information on both state regulations and the presence in the county of safety net providers.) Our second data set is the nationally representative CTS-HS. The CTS-HS samples about 32,000 households per year, and data for both health insurance premiums and detailed chronic health conditions were collected for years 1998-1999 and 2000-2001.2 The restricted-use version of the CTS-HS also contains county-level identifiers.
Both of these surveys collected data for the premium paid and for various characteristics of the plan reflecting the generosity of the plan. (We inflate the premiums to 2004 dollars in both data sets.) The NHIS data includes whether the plan has a directory of doctors who will take its patients, whether the plan will play for an out-of-network physician, and whether a referral is required to see an in-network specialist. The CTS-HS includes these measures, as well as whether the plan requires individuals to sign up with a certain primary care physician. We use these measures to control for the generosity of the plan chosen.
Since the premiums are for the policyholder and cover all member of the family insurance unit, we define our potential sample of policyholders of individual insurance for Equation (2) by pooling the sample of individual insurance policyholders with a sample of uninsured families without apparent access to employment-based insurance. As such, we exclude families in which any member is either covered by public insurance or working as a full-time wage-earner from this first-stage sample of potential purchasers.
D. Estimating Expected Expense
Our main variable of interest in Equations (1) and (2) above is the measure of expected medical expense, risk, for the household. (We describe the explicit specification for this measure in Equations (1) and (2) further below.) We first produce estimates of individual-level expected expenses using a two-part regression model, since the distribution of actual expense has a large mass at zero and is heavily skewed. The first part is a probit model for the likelihood of having any nonzero expenses, and the second part is a generalized gamma model with a log link for the sub-sample with nonzero expenses; for more detail regarding the use of this model for expected expense, see Manning and Mullahy (2001).
We estimate the two-part model for privately-insured individuals in the Medical Expenditure Panel Survey (MEPS) pooling years 1996-2003 (with appropriate inflation adjustments), estimating separate models for children and adults. (Neither the NHIS nor CTSHS has data for actual medical expenses.) We include binary variables for age interacted with gender (using roughly five-year age intervals) and a host of binary variables indicating the presence of chronic health conditions identified in the NHIS or CTS-HS data. We use the coefficients from the sample of privately-insured individuals to produce estimates of individual-level expense for both insured and uninsured (as if they were insured) individuals.
To generate estimated of expected expense for the NHIS sample, we link observations from the 1997-2002 NHIS directly to the subsequent 1998-2003 MEPS, as the MEPS samples are derived from the NHIS samples in the prior year. The NHIS first asks respondents whether they faced any limitations in routine activities and then, for those who report any limitations, the NHIS asks for the medical condition(s) causing the limitation and how long they have had that limitation. We exclude the conditions discovered during the survey year since those conditions cannot influence the risk insurers observed. For children, we identify five groups of conditions: vision, hearing, and speech problems; asthma; developmental problems like retardation, learning disabilities; emotional or behavioral problem, Attention Deficit Disorder (ADD); and all other reasons collapsed: birth defect, injury, bone/joint/muscle problem, epilepsy, and other. For adults, we identify 11 groups of conditions: arthritis; back or neck problems; heart problems; stroke; hypertension; diabetes; lung problems; cancer; mental retardation, other developmental problem, and senility; depression/anxiety/emotional, drug/alcohol, and other mental problems; and all other reasons collapsed: vision, hearing, broken bone, injury, birth defect, overweight, musculoskeletal, circulatory, endocrine, nervous system, digestive problem, genitourinary problem, skin problem, blood problem, benign tumor problem, and other.
To generate estimated of expected expense for the CTS-HS sample, we estimate this two-part expenditure model with the MEPS sample using only the conditions also identified in the CTS-HS data. The CTS-HS data identifies two conditions for children: asthma and ADD for children. For adults, there are eight conditions: diabetes, arthritis, asthma, hypertension, heart disease, skin cancer, other cancer, and depression. Unfortunately, the CTS-HS does not obtain when the condition was discovered so we are unable to include only those conditions discovered before the survey year, as with the NHIS data.3 As a result, our estimate of risk for the CTS-HS will include some noise and thus be biased towards zero.
Once we have constructed individual-level estimates of risk for people in the NHIS and CTS-HS data, we then construct family-level estimates of risk by summing the individual-level amounts across the family. Since we are especially interested in examining the differential effects of expected expense related to age and gender and those related to the presence of chronic conditions, we include the following two measures for expected expense, consistent with our prior work (Pauly and Herring, 1999; Herring and Pauly, 2001). One measure is the log of family expected expense using only age and gender as explanatory variables in the prediction models. We use the log of the expected expense so that the 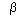 coefficient in the premium regression can be interpreted as an elasticity estimate (i.e., a coefficient equal to one implies a proportional relationship between premiums and expected expense).
coefficient in the premium regression can be interpreted as an elasticity estimate (i.e., a coefficient equal to one implies a proportional relationship between premiums and expected expense).
The second measure is an index of adjusted condition-related expected expense, calculated as the ratio of family-level expected expense using age, gender, and health conditions relative to the family-level expected expense based only on age and gender. This index therefore measures the effect of health status on premiums and coverage, given ones age and gender; an index of 2.0, for instance, implies that the presence of a particular set of health conditions has caused that family to have expected expenses twice as high than if they had the same age and gender mix and were in average health. Finally, since premiums vary simply with the number of dependents, we include the number people covered by the plan so that the risk variables measure variation due only to age, gender, and health status.
E. Categorizing State Regulations
Since we are interested in testing whether state regulations have an impact on the relationship between premiums and risk and the on the relationship between coverage and risk, our empirical strategy is to estimate Equations (1) and (2) for different samples of unregulated and regulated states and then compare the estimated coefficients for from these two samples. Since there is a range of regulations states have implemented to limit variation of premiums and coverage with risk, we focus on groups of states at either end of this spectrum.
Community rating laws prohibit health plans use of experience, health status or duration of coverage in setting premium rates for individual coverage, while some community rating laws also prohibit use of demographic factors such as age and/or gender. Guaranteed issue laws mandate that insurers sell policies to all applicants, regardless of health status. The interaction of these two laws is important to a state wanting to ensure access to high-risk applicants because community rating alone could result in strict underwriting to exclude all high-risk applicants. States comprising our regulated sample with both community rating and guaranteed issue during this time period include Maine, Massachusetts, New Hampshire, New Jersey, New York, and Vermont.4 These six states also limited pre-existing condition exclusions in effect during this period. A number of states have rating band laws that restrict health plans use of health status by setting limits on allowable rate differences between blocks of covered individuals, but we do not include these in our sample of regulated states.5 Our sample of unregulated states is comprised of states with neither community rating nor guaranteed issue.6
III. RESULTS
A. Main Results
Table 1 shows the full set of regression results specified by equations (1) and (2) for the full sample of individual insurance purchasers regardless of state regulation; the top panel shows results from the NHIS data and the bottom panel shows results from the CTS-HS data. The results from the NHIS and CTS-HS are rather consistent. In the selection equation for purchasing individual insurance, the availability of charity care in the county decreases the likelihood of families obtaining coverage, while families with higher levels of education are more likely to obtain coverage. The Mills Ratio correlation term is significantly negative confirming that households more likely to purchase coverage in unmeasured ways face relatively lower premiums. In the model for the log of premiums, the control variables for the restrictiveness of coverage are generally predictive of premiums, but not always in an expected way, as each of these restrictions should imply a lower premium. However, more restrictive health maintenance organizations (HMOs) typically have low levels of cost-sharing so that the expected benefits provided by the insurer could be the same as a less restrictive plan (e.g., a restrictive HMO and a $500 deductible fee-for-service plan may have similar actuarial values); neither the NHIS nor CTS-HS has data for cost-sharing.
What is the relationship between premiums and measures of risk in this model? For the premium regression, the age and gender-related expense has an elasticity of 0.480 with respect to risk in the NHIS and 0.328 in the CTS-HS, implying that an older family with twice the expected expense would pay, on average, premiums that are at most 50 percent higher. This finding for age and gender-related expense is actually very consistent with our earlier findings using the 1987 NMES and 1996-1997 CTS-HS. It also rather consistent with a feature known as guaranteed renewability included in most individual insurance products. We discuss this feature in detail further below.
The log of condition-related expense is also statistically significant in both data sets, implying that families with the presence of high-risk chronic conditions do appear to pay, on average, higher premiums in the individual market. However, the economic magnitude of this effect is modest, implying that there is a high level of pooling. Families with health conditions that are twice as expensive to treat pay premiums that are only 11.5-15.5 percent higher than average. If insurers knew or could have known about the chronic condition and its effect on expected expense, this result implies that, somehow, those with chronic conditions that make them twice as expensive as average spread 85 percent or more of that risk to premiums paid by others.
For the coverage regression, age and gender-related expenses are positively related with the likelihood of obtaining coverage, while health condition-related expenses are negatively related with the likelihood of obtaining coverage. We examine the magnitude of this effect of condition-related expense on coverage further below.
B. Results by Regulation and Income
Table 2 shows these results from the NHIS and CTS-HS for the relationship between risk, premiums, and coverage for unregulated versus regulated states. For these sets of regressions we only show the coefficients from the age and gender-related expense and the index of condition-related expense.
Consider first the effects of community rating and guaranteed issue regulations on premiums. The positive effect of condition-related expense on premiums observed in Table 1 is observed only in states with neither of these regulations. In states with community rating and guaranteed issue, there is no statistically significant relationship between premiums and condition-related expense. The difference between these coefficients, however, is not statistically significant; even though the point estimate of the coefficient from the unregulated sample is higher than the point estimate of the coefficient from the regulated sample, the standard error of the latter is too large to conclude that there is a significant effect of regulation on the relationship between premiums and risk.
Now consider the effects of community rating and guaranteed issue regulations on whether families obtain coverage. The significantly negative effect of condition-related expense on coverage observed in Table 1 for the full sample is observed only in the states with neither community rating nor guaranteed issue regulations. There is no significant effect, negative or positive, for condition-related expense on coverage in highly-regulated states. The difference between the coefficients from the unregulated and regulated samples is statistically significant. We explore the magnitude of this difference below.
Table 3 shows these results for the relationship between risk, premiums, and coverage in unregulated states for low-income versus high-income households. (We define low and high-income as having total family income either below or above 300 percent of the federal poverty level.) The results in this Table indicate that the negative effect of condition-related risk on premiums is observed in low-income households but not in high-income households. A potential reason is that the front loading of premiums needed to pay for effective guaranteed renewability is thought to be less affordable by lower income households (Frick, 1999). The negative effect of condition-related expense on obtaining coverage is observed for both low-income and high-income households. We are unable to determine whether this negative relationship results from insurer reluctance to offer coverage to high-risk households or from high-risk households electing not to purchase coverage at a (presumably) high premium.
C. Examining the Effect of Health Risk on Coverage
The above results indicate that there is a negative effect of condition-related expense on the likelihood of obtaining coverage in unregulated states, while there is no effect of condition-related expense on the likelihood of obtaining coverage in states with community rating and guaranteed issue regulations. These results therefore suggest that implementing these regulations increase the number of high-risk people with insurance, but this increase will occur at the expense of low-risk people. But what is the magnitude of this effect? And what might the overall effect on the number of those with individual insurance be?
To answer this first question, we show the predicted probabilities of obtaining coverage for those in unregulated states at various points of the distribution of expected expense. For this set of results, we examine person-level models for coverage (rather than a household-level model like that done for the two-stage models of premiums and coverage) and continue to examine age and gender-related expense and condition-related expense independently. The top panel of Table 4 shows the coefficient for condition-related expense for the NHIS sample of unregulated and regulated states for years 1997-2004, while the bottom panel shows these coefficients for the CTS-HS sample for years 1998-2003. As before, the effect of condition-related expense on coverage is insignificant in states with both community rating and guaranteed issue regulations, and the difference between the coefficients from the unregulated and regulated samples are statistically significant. The first column of the Table shows the predicted probabilities in unregulated states for various points of the distribution of condition-related expense, normalized to the average proportion insured in the sample. For low-risk people at the 10th percentile of the distribution, the relative rate of obtaining coverage (compared to a person of average-risk) in unregulated states is 1.029 in the NHIS data and 1.045 in the CTS-HS data. For high-risk people at the 90th percentile of the distribution, the relative rate of obtaining coverage in unregulated states is 0.915 in the NHIS data and 0.929 in the CTS-HS data. While it is clear that high-risk people in unregulated states are relatively less likely to obtain coverage, it is our assessment that the magnitude of this risk gradient is not overly large in magnitude. It appears that there are a sizeable number of high-risk people that obtain coverage in unregulated markets.
To address the second question regarding the effect of regulations on the total percentage with insurance, we cannot simply compare the rates of coverage in unregulated to regulated states, since there are many other factors, some unknown, that influence insurance purchasing across states; it would be difficult for us to tease out the effect of regulation alone. We also cannot utilize the difference-in-difference approach of examining the staggered implementation of these rating laws over time, since the period in which we have this detailed health condition data (i.e., after 1997) had very little variation over time in community rating regulations. We therefore take the results from our analysis of risk on coverage and simulate the effect on coverage by determining the expected increase in premiums caused by the influx of higher-risk persons into a competitive health insurance market after implementing community rating. This increase in the average premium (having already accounted for the revised mix of risk levels) can be expected to cause both high-risks and low-risks to drop coverage.
We assume that the relationship between coverage and risk for those in regulated states is the insignificant (but positive in magnitude) point estimate obtained from that samples probit regression. (As such, the effect we observe is at the high end of increasing overall costs, although the magnitude of this insignificantly positive coefficient is indeed small.) As shown in the second column of Table 4, these regulations would increase the relative rate of insurance coverage that high-risks at the 90th percentile of the risk distribution obtain coverage from 0.915 to 1.003 in the NHIS data (and from 0.929 to 1.032 in the CTS-HS data), but would reduce the relative rate of coverage that low-risks at the 10th percentile obtain coverage from 1.029 to 0.999 in the NHIS data (and from 1.045 to 0.980 in the CTS-HS data). (The functional form of the probit model does not require uniformity with respect to the mean. Moreover, the distribution of expected expense is more heavily skewed in the NHIS compared to the CTS-HS, since there is more extensive data on chronic conditions in the NHIS.) This shift in the composition of those with coverage by risk would increase the average premium in competitive but regulated markets by approximately 14.8 percent using the NHIS results and by approximately 12.0 percent using the CTS-HS results. (We determine these estimates by simply applying the change in predicted probabilities to our individual-level estimates of expected expense.)
The consensus estimate of the price elasticity of demand for insurance of -0.50 provided by Glied et al. (2002) would then imply that the number of insured will fall by between 6.0 and 7.4 percent as the result of the effect of implementing community rating regulations on costs. These factors then yield the results in the third column of Table 4 showing an average relative rate of insurance coverage equal to 0.926 for regulated states using the NHIS data (e.g., 0.929 for those at the 90th percentile equals 0.926 x 1.004, where 1.004 is the original estimate for the 90th percentile above) and 0.940 for regulated states using the CTS-HS data. In some sense, the implementation of community rating and guaranteed issue laws would appear to benefit less than a quarter of the population at the expense of more than three-fourths of the population.
IV. CONCLUSION
The results presented in this paper generally indicate the state-level community rating and guaranteed issue regulations in the individual market do appear to limit to some extent variation in premiums and coverage due to health conditions-related expense. In states with no such regulations, we observe a negative effect of condition-related expense on coverage and a positive effect on premiums. In states with these regulations, we observe no significant effects of condition-related expense on either coverage or premiums. In this sense, regulations do seem to work in that they make high-risk people relatively more likely to obtain coverage and pay lower premiums.
Our main finding in this analysis, however, appears to be the extent of pooling of risks in the individual market within unregulated states. The effect of doubling a households condition-related expense appears to imply, at most, a 15 percent increase in the premium. A low-risk person at the 10th percentile of risk is about 1.029-1.045 times as likely to obtain coverage as an average-risk person, while a high-risk person at the 90th percentile of risk is about 0.915-0.929 times as likely to obtain coverage as an average-risk person. These results, taken together, imply a significant amount (albeit not perfect) amount of pooling of health risks even in unregulated markets.
We do not observe overly large adverse consequences resulting from implementing community rating and guaranteed issue regulations in the individual market. That is, we do not observe a strong positive relationship between risk status and the likelihood of being covered that would be consistent with so-called death spirals induced by adverse selection. However, we do see evidence supporting the substitution of some high-risk people with coverage for a larger number of low-risk people with coverage as the result of implementing these regulations. This could imply an overall increase in the number without coverage in the individual market--perhaps as high as about 7.4 percent. An interesting question for policymakers is therefore the extent to which an increase in coverage for high-risk people is worth a slightly larger corresponding decrease in coverage for low-risk people.
Perhaps the reason we see small effects of implementing these regulations is because there is not an overwhelming amount of risk segmentation in unregulated markets. What could explain these results for this apparent degree of pooling? We think the answer lies with successful guaranteed renewability provisions in individual insurance. Guaranteed renewable (GR) insurance stipulates that those within the same initial class of coverage can renew their policies as class average rates. Thus, a finding that the condition-related component of expected expense has a significant but economically small effect on premiums is consistent with the hypothesis that most high-risk people obtained GR coverage before actually becoming high-risk. A possible explanation is that most high-risk people pay premiums that are unrelated to their health status (because of their effective GR coverage), while a few high-risk people pay premiums proportional to their expected expense because they were underwritten as high-risk at the point of obtaining coverage; this could explain the low average effect of risk on premiums. (Neither the NHIS nor the CTS-HS has data for the amount of time one has been covered by their current plan for us to test this hypothesis, however.) Moreover, the 0.40 elasticity of premiums with respect to age and gender-related expense is quite consistent with the theory of incentive-compatible GR insurance incorporating front-loaded premiums to both cover future-period medical claims and encourage older low-risk people to continue to purchase the policy (Herring and Pauly, 2006).
Overall, our results indicate that policymakers efforts to improve the individual market might be better focused in areas other than enacting community rating or guaranteed issue regulations. While these regulations do not appear to do much harm, they also do not appear to do much good either, since there is not a big problem of risk segmentation in unregulated health insurance markets. It seems to us that there are two problems with the current individual market that deserve more attention. First, the high administrative loading in the individual market results in high premiums for both high-risk and low-risk individuals alike. Second, the tax subsidy available to employment-based insurance but not generally available to those in the individual market results in an inherent instability of the latter since people will almost always prefer (and perhaps distort their behavior) to obtain their coverage in the former. Policymakers should consider making the incentives for obtaining individual versus group insurance neutral. Consumers should obtain their insurance where it is more efficient for them to do so. An increase in the number of people actually using the individual market (and remaining there over time) that could result from eliminating this inequity will likely have the byproduct of reducing its high administrative loading as the market grows in size.
REFERENCES
Buchmueller, T. and J. DiNardo, 2002, Did Community Rating Induce an Adverse Selection Death Spiral? Evidence from New York, Pennsylvania, and Connecticut, American Economic Review 92.1, 280-294.
Bundorf, M.K. and M. Pauly, 2004, Is Health Insurance Affordable for the Uninsured? NBER Working Paper #9281.
Bundorf, M.K., B. Herring, and M. Pauly, 2005, Income, Health Risk, and the Purchase of Private Health Insurance, Stanford University Working Paper.
Chollet, D., A. Kirk, and K. Simon, 2000, The Impact of Access Regulation on Health Insurance Market Structure, Report submitted to DHHS ASPE.
Davidoff, A., L. Blumberg, L. Nichols, 2005, State Health Insurance Market Reforms and Access to Insurance for High-Risk Employees, Journal of Health Economics 24.4, 725750.
Frick, K., 1998, Consumer Capital Market Constraints and Guaranteed Renewable Insurance, Journal of Risk and Uncertainty 16, 271-278.
Glied, S., D. Remler, and J. Graff-Ziven, 2002, Inside the Sausage Factory: Improving Estimates of the Effects of Health Insurance Expansion Proposals, Millbank Quarterly 80.4, 603-636.
Hadley, J., and J. Reschovsky, 2003, Health and the Cost of Nongoup Insurance, Inquiry 4.3, 235-253.
Heckman, J., 1979, Sample Selection Bias as a Specification Error, Econometrica 47, 153-162.
Herring, B., 2005, The Effect of the Availability of Charity Care to the Uninsured on the Demand for Private Health Insurance, Journal of Health Economics 24.2, 225-252.
Herring, B., and M. Pauly, 2001, Premium Variation in the Individual Insurance Market, International Journal of Health Care Finance and Economics 1.1, 43-58.
Herring, B., and M. Pauly, 2006, Incentive-Compatible Guaranteed Renewable Health Insurance Premiums, Journal of Health Economics 25.3, 395-417.
LoSasso, A. and Lurie, 2003, The Effect of State Policies on the Market for Private Non-Group Health Insurance, Institute for Policy Research Northwestern University Working Paper Series #04-09.
Manning, W., and J. Mullahy, 2001, Estimating Log Models: To Transform or Not to Transform, Journal of Health Economics 20, 461-494.
Marquis, M., and M. Beeuwkes-Buntin, forthcoming, Risk Pooling in the Individual Health Insurance Market, Health Services Research.
Pauly, M., and B. Herring, 1999, Pooling Health Insurance Risks. Washington, D.C.: AEI Press.
Percy, A., 2000, Community Rating and Regulatory Reform in Health Insurance Markets, PhD Dissertation, University of Pennsylvania.
Rothschild, M., and J. Stiglitz, 1976, Equilibrium in Competitive Insurance Markets: An Essay on the Economics of Imperfect Information, Quarterly Journal of Economics 90.4, 630649.
Sloan, F., and C. Conover, 1998, Effects of State Reforms on Health Insurance Coverage of Adults, Inquiry 35, 280-293.
Zuckerman, S., and S. Rajan, 1999, An Alternative Approach to Measuring the Effects of Insurance Market Reforms, Inquiry 35, 44-56.
TABLES
| TABLE 1: Full Regression Results for Premiums and Coverage in the Individual Market: All U.S. States | ||||
| Variable | Purchase Coverage: | Premium: | ||
| Probit Coefficient | Standard Error | OLS Coefficient | Standard Error | |
| NHIS Data for 1999 through 2004: | ||||
| Intercept | -7.801 | 0.115*** | 4.204 | 0.215*** |
| Health center or public hospital in county | -0.168 | 0.017*** | ||
| Family has at most a high school graduate | 0.531 | 0.031*** | ||
| Family member has at most some college | 0.831 | 0.030*** | ||
| Family member is at most a college graduate | 1.379 | 0.032*** | ||
| Family member attended graduate school | 1.588 | 0.036*** | ||
| Number covered by the plan | -0.135 | 0.007*** | 0.037 | 0.008*** |
| Log expected expense: age and gender | 0.790 | 0.014*** | 0.480 | 0.023*** |
| Log condition-related expected expense | -0.379 | 0.028*** | 0.155 | 0.036*** |
| Plan has a director of doctors | 0.058 | 0.023** | ||
| Plan will not pay for out-of-network physician | -0.083 | 0.026*** | ||
| Plan requires referral for in-network specialist | 0.053 | 0.020*** | ||
| Year indicators included | yes | yes | ||
| Correlation | -0.191 | 0.040*** | ||
| (Log likelihood = -17597.3) | N=54,438 | N=6,390 | ||
| CTS-HS Data for 1998/1999 and 2000/2001: | ||||
| Intercept | -6.801 | 0.210*** | 5.003 | 0.358*** |
| Health center or public hospital in county | -0.229 | 0.037* | ||
| Family has at most a high school graduate | 0.722 | 0.059*** | ||
| Family member has at most some college | 1.183 | 0.061*** | ||
| Family member is at most a college graduate | 1.622 | 0.067*** | ||
| Family member attended graduate school | 1.962 | 0.082*** | ||
| Number covered by the plan | -0.462 | 0.020*** | 0.301 | 0.028*** |
| Log expected expense: age and gender | 0.759 | 0.027*** | 0.328 | 0.041*** |
| Log condition-related expected expense | -0.152 | 0.026*** | 0.115 | 0.028*** |
| Plan has a director of doctors | 0.214 | 0.038*** | ||
| Plan requires primary care physician assignment | 0.074 | 0.039* | ||
| Plan will not pay for out-of-network physician | -0.087 | 0.038** | ||
| Plan requires referral for in-network specialist | -0.031 | 0.037 | ||
| Year indicators included | yes | yes | ||
| Correlation | -0.572 | 0.095*** | ||
| (Log likelihood = -6395.0) | N=10,545 | N=2,411 | ||
| p-values: Statistical significance at 0.01 or better (***); between 0.01 and 0.05 (**); between 0.05 and 0.10(*). | ||||
| TABLE 2: Regression Results for Risk on Premiums and Coverage in the Individual Market: Unregulated Versus Regulated States | ||||
| Variable | Purchase Coverage: | Premium: | ||
| Probit Coefficient | Standard Error | OLS Coefficient | Standard Error | |
| NHIS Data for 1999 through 2004: | ||||
| Unregulated States: | ||||
| Log of expected expense: age and gender | 0.780 | 0.016*** | 0.465 | 0.026*** |
| Log of condition-related expected expense | -0.429 | 0.034*** | 0.108 | 0.043** |
| Regulated States: | ||||
| Log of expected expense: age and gender | 0.939 | 0.052*** | 0.251 | 0.104** |
| Log of condition-related expected expense | -0.042 | 0.089 | 0.069 | 0.105 |
| CTS-HS Data for 1998/1999 and 2000/2001: | ||||
| Unregulated States: | ||||
| Log of expected expense: age and gender | 0.749 | 0.032*** | 0.356 | 0.047*** |
| Log of condition-related expected expense | -0.172 | 0.031*** | 0.074 | 0.034** |
| Regulated States: | ||||
| Log of expected expense: age and gender | 0.776 | 0.076*** | 0.545 | 0.091*** |
| Log of condition-related expected expense | 0.053 | 0.075 | 0.023 | 0.070 |
| p-values: Statistical significance at 0.01 or better (***); between 0.01 and 0.05 (**); between 0.05 and 0.10(*). | ||||
| TABLE 3: Regression Results for Risk on Premiums and Coverage in the Individual Market: Low-Income Versus High-Income in Unregulated States | ||||
| Variable | Purchase Coverage: | Premium: | ||
| Probit Coefficient | Standard Error | OLS Coefficient | Standard Error | |
| NHIS Data for 1999 through 2004: | ||||
| Low-Income in Unregulated States: | ||||
| Log of expected expense: age and gender | 0.663 | 0.022*** | 0.524 | 0.037*** |
| Log of condition-related expected expense | -0.382 | 0.040*** | 0.147 | 0.059** |
| High-Income in Unregulated States: | ||||
| Log of expected expense: age and gender | 0.778 | 0.026*** | 0.427 | 0.064*** |
| Log of condition-related expected expense | -0.258 | 0.067*** | 0.062 | 0.067 |
| CTS-HS Data for 1998/1999 and 2000/2001: | ||||
| Low-Income in Unregulated States: | ||||
| Log of expected expense: age and gender | 0.713 | 0.046*** | 0.278 | 0.099*** |
| Log of condition-related expected expense | -0.142 | 0.040*** | 0.104 | 0.060* |
| High-Income in Unregulated States: | ||||
| Log of expected expense: age and gender | 0.769 | 0.046*** | 0.502 | 0.046*** |
| Log of condition-related expected expense | -0.149 | 0.049*** | 0.037 | 0.036 |
| p-values: Statistical significance at 0.01 or better (***); between 0.01 and 0.05 (**); between 0.05 and 0.10(*). | ||||
| TABLE 4: Results for Risk on Coverage in the Individual Market Unregulated Versus Regulated States | |||
| Condition-Related Expected Expense | Unregulated States: Observed | Regulated States: Observed | Regulated States: Simulateda |
| NHIS Data for 1997 through 2004: | |||
| Probit Coefficientb | -0.209[0.029]*** | 0.007[0.077] | n/a |
| Relative Rates of Insurance Coverage | |||
| Average | 1.000 | 1.000 | 0.926 |
| 95th percentile | 0.882 | 1.004 | 0.930 |
| 90th percentile | 0.915 | 1.003 | 0.929 |
| 75th percentile | 1.006 | 1.000 | 0.926 |
| 50th percentile | 1.014 | 0.999 | 0.926 |
| 25th percentile | 1.020 | 0.999 | 0.925 |
| 10th percentile | 1.029 | 0.999 | 0.925 |
| 5th percentile | 1.044 | 0.998 | 0.925 |
| CTS-HS Data for 1998/1999, 2000/2001, and 2003: | |||
| Probit Coefficientb | -0.094[0.025]*** | 0.041[0.061] | n/a |
| Relative Rates of Insurance Coverage | |||
| Average | 1.000 | 1.000 | 0.940 |
| 95th percentile | 0.899 | 1.046 | 0.984 |
| 90th percentile | 0.929 | 1.032 | 0.970 |
| 75th percentile | 0.974 | 1.011 | 0.951 |
| 50th percentile | 1.017 | 0.992 | 0.932 |
| 25th percentile | 1.027 | 0.988 | 0.929 |
| 10th percentile | 1.045 | 0.980 | 0.921 |
| 5th percentile | 1.056 | 0.975 | 0.917 |
p-values: Statistical significance at 0.01 or better (***); between 0.01 and 0.05 (**); between 0.05 and 0.10(*).
| |||
NOTES
-
We use NHIS data from 1997 and 1998 for our models of expected expense, described below. We also use NHIS data for these years in a model focusing solely on whether one obtains insurance coverage, also described below.
-
We do not use the 2003 CTS-HS data for our analysis of household premiums because survey questions regarding chronic health conditions for children were dropped from this year.
-
Another limitation to the CTS-HS data is the way in which information is collected for children. In households with more than one child, the CTS-HS only includes one randomly-selected child for inclusion in the survey. (That childs sample weight varies, however, to account for the other children in the family,) As a result, families with more than one child and at least one unhealthy child will appear sicker than they really are if that child was randomly-selected as the representative child while such a family will appear healthier than they really are if that child was not randomly-selected as the representative child. Thus, we will expect our estimates for condition-related expense in the CTS-HS to be biased towards zero to the extent that childrens health affects the variation across households in total family medical expenses.
-
Kentucky had a community rating law in effect that was rescinded in 2001.
-
States with rating bands include Idaho, Iowa, North Dakota, New Mexico, Oregon, Utah, and Washington.
-
These states include Alabama, Alaska, Arkansas, Arizona, California, Colorado, Connecticut, Delaware, District of Columbia, Florida, Georgia, Hawaii, Illinois, Indiana, Kansas, Louisiana, Maryland, Michigan, Minnesota, Mississippi, Missouri, Montana, Nebraska, Nevada, North Carolina, Oklahoma, Pennsylvania, South Carolina, Tennessee, Texas, Virginia, West Virginia, Wisconsin, and Wyoming. States with guaranteed issue laws but no rating regulations--and hence not included in our sample of unregulated states--are Ohio, Rhode Island, and South Dakota. While some of these states did have pre-existing condition exclusions in effect during this period, we do not exclude them from our sample of unregulated states. Paradoxically, the states with this pre-existing condition exclusion in effect are those in which a stronger relationship between premiums and risk would be expected.