
U.S. Department of Health and Human Services
Children's Bureau
Administration on Children, Youth and Families
Administration for Children and Families
and
Office of the Assistant Secretary for Planning and Evaluation
Executive Summary
Introduction
The National Study of Child Protective Services Systems and Reform Efforts, under the leadership of the Children's Bureau of the Administration for Children and Families and the Office of the Assistant Secretary for Planning and Evaluation, both within the U.S. Department of Health and Human Services, has examined the current system of child protective services (CPS) from both a policy and a practice perspective. While there are five main components to the National Study, this report discusses the findings on CPS practice based on just one of the components--the Local Agency Survey (LAS) of the CPS agencies serving a randomly selected sample of counties in the United States.
The purpose of the survey was to identify the ways in which local agencies carried out the CPS functions across the U.S. Its design consisted of a mail survey to the CPS agencies serving a representative sample of 375 counties. The sample was designed to assure adequate representation of urban and rural counties, counties in both State-administered systems and counties in county-administered systems, and all census regions. An 80 percent response rate was achieved; surveys covering 300 counties were received.
After a brief description of the study, this report discusses current practice (as of 2002) related to the organization and administration of CPS, the screening and intake functions, the investigation function, the provision of an alternative noninvestigative response by many agencies, and the role of law enforcement and other agencies in CPS work.1 In addition, changes being undertaken by local agencies and conclusions are presented.
Agency Administration and Staffing
There were an estimated 2,600 local CPS agencies throughout the country during 2001. These may be county-level agencies or State regional offices covering multiple counties. For 61 percent of agencies, workers could perform more than one CPS function. In larger agencies, specialized workers often conducted single functions. While there were differences between small and large agencies, on average a CPS agency screened 64 referrals and completed 43 investigations per month. The average number of caseworkers per agency was 17. Additional analyses indicate that one-quarter of agencies had approximately 4 or fewer workers, and another one-quarter had 15 or more.
It is estimated that only a small number of staff positions were vacant among CPS local agencies at the time of the survey. On average, each agency had 0.6 vacancies, of which 0.4 were social workers or caseworkers. More than 75 percent of agencies indicated that they had no vacancies at the time of the survey.
A majority of agencies operated with specialized staff in their screening and intake, and investigation functions, even though approximately 20 percent of these agencies had staff perform other functions when needed. The majority of children resided in counties that were served by agencies with staff who specialized in providing one CPS function.
This pattern of specialization is similar for agencies that offer other responses to abuse and neglect allegations in that almost one-half of such agencies had specialist staff in the role of screening and intake versus alternative response.2 However, in most agencies (60%) the same workers who provided investigation also provided alternative response.
Most agencies believed that their workloads were excessive. Almost 70 percent of agencies thought this was the case for at least one CPS function. Three-quarters of the Nation's children resided in jurisdictions where CPS agencies reported excessive workloads. There is some indication that concerns about workload were especially prevalent among agencies serving larger child populations.
Screening and Intake
CPS agencies received referrals from many sources.3 Individuals, State or local hotlines, and schools were the most common referral sources. A substantial minority of CPS agencies automatically accepted referrals from certain sources such as specific agencies or mandated reporters.
Roughly two-thirds of local CPS agencies received State hotline referrals; however, most agencies had local authority in handling these referrals. For example, even though the State hotline might make recommendations regarding the local response, many agencies assigned their own priority status to the recommendation.
Very few CPS agencies made direct contact with the child, family, or reporter during the screening and intake process. In conducting screening and intake activities, a majority of CPS agencies indicated that they always searched CPS records for information on the alleged victims and alleged perpetrators, and that they used a safety assessment tool. Nonetheless, agencies undertook a wide variety of other activities during the screening process, including calls to collaterals, calls to family members, and establishing the credibility of the reporter.
A large majority of CPS agencies used various response options for screened-out referrals, including making referrals to other agencies. For all types of screened-in referrals, the most common response option was a CPS investigation; however, approximately one-quarter to one-half of agencies had several response options for screened-in referrals.
Investigation and Alternative Response
After the screening process, almost two-thirds of agencies nationwide handled referrals through both investigations and alternative responses.
Alternative responses were defined for study purposes as a formal response of the agency that assesses the needs of the child or family without requiring a determination that maltreatment had occurred or that the child is at risk of maltreatment. Overall, the investigation response was used for the more serious types of maltreatment, while the alternative responses were used for situations where children were at risk of maltreatment or where the situation could be remedied without an investigation. Further, alternative responses were less likely to be used for removing a child from the home, to include an assessment of safety needs of the family, to make a determination of whether maltreatment or risk of maltreatment had occurred, or to make a recommendation for court action.
Despite a different focus for the two responses, many of the approaches and practices used in conducting the responses were similar. Almost all agencies reviewed CPS records, interviewed or formally observed the child, and interviewed the caregiver during investigations. Slightly lower proportions of agencies conducted the same activities during alternative responses. Under both responses, a majority of agencies sometimes discussed the case with other CPS workers or with a multidisciplinary team, visited the family, and interviewed professionals.
Agencies had access to a wide range of resources during both responses. Nearly three-quarters of agencies used guidelines for establishing risk or safety of a child during investigations, and almost two-thirds of agencies also used such guidelines during alternative responses.
While a majority of agencies followed guidelines for conducting assessments during the investigation response, only a minority used formal assessment tools during the investigation to gauge the extent of risk, safety, substance abuse, or domestic violence. This finding may contradict what many in the field believe to be a more widespread use of these tools during investigations. Overall, there was less use of standardized instruments and tools during alternative responses than during investigation.
Certain professional resources were widely available during both investigations and alternative responses. For example, clinicians or psychiatrists, domestic violence specialists, substance abuse specialists, and child fatality teams were almost always available to assist workers during both investigation and alternative response activities.
CPS agencies also provided followup services to children and families as part of their responses. Almost three-quarters of agencies were allowed to provide services regardless of the result of investigations. The range of potential service offerings available to most agencies was quite extensive, with educational or therapeutic services most commonly available, and financial services less commonly available. Approximately one-quarter of agencies provided services only if a report was substantiated or did not provide followup services at all.
Collaboration with Other Agencies
While more CPS agencies claimed lead responsibility across all type of maltreatment for the screening function, very few had overall lead responsibility for the investigation and alternative response functions. The specific circumstances of the maltreatment also shaped the role of CPS agencies. CPS agencies shared lead responsibility more often for the more serious forms of maltreatment. CPS agencies shared lead responsibility for screening more often for physical abuse and sexual abuse than for neglect or other maltreatment. Similarly, while more than one-half of CPS agencies shared lead responsibility for severe physical abuse, the percentages for moderate physical abuse and at risk of physical abuse were much lower. CPS agencies were most likely to have lead responsibility when an investigation or an alternative response related to a perpetrator who was a family member or a relative. Approximately one-half of the agencies did not provide alternative response in cases that included foster parents, institutional staff, or minors.
The findings also reveal a distinction between the role of law enforcement and that of other agencies in CPS work. Across different types of maltreatment, CPS agencies reported sharing lead responsibility with law enforcement more often than with any other type of agency. While nearly three-quarters of CPS agencies shared lead responsibility with law enforcement for physical and sexual abuse, fewer than 20 percent of agencies shared with other, nonlaw enforcement agencies for these types of maltreatment. The same pattern holds true for different types of perpetrators with more sharing of lead responsibility with law enforcement agencies. While 41 percent of CPS agencies shared lead responsibility with law enforcement agencies when the perpetrator was a family member or relative, just 3 percent shared with other agencies for this type of perpetrator. Together, these differences emphasize the significant role law enforcement agencies play in CPS processes. Law enforcement agencies are the only other agencies besides CPS agencies that can receive mandated reports of child maltreatment, enforce the applicable criminal law, and remove children from their parents, if they are being maltreated or are at risk of maltreatment.
Changes in CPS Practice
Agencies' overall approaches to CPS were generally stable; more than one-half reported that their practices had been in place for 5 or more years. However, there were many areas of ongoing modification and adjusting. In the area of organizational changes, more than one-quarter had made changes to their use of information technology and nearly 30 percent had adjusted staff training during the preceding 6 months. Further, 13 percent of agencies had made changes to their philosophy of services, such as to include a stronger focus on either safety or family-centered services. With respect to community partners, 11 percent of CPS agencies had implemented changes related to their collaboration with substance abuse agencies, and16 percent had implemented changes in collaborations with domestic violence agencies. In the area of screening and intake, 17 percent had changed their use of assessments or other standard instruments in the screening process. Relatively few changes had been made to investigation processes, but the most common was the introduction or modification of multidisciplinary teams, noted by 9 percent of agencies.
This survey is the first to attempt an estimate of how deeply changes have reached into the CPS field. It appears that changes are not as deep at the local level as might have been assumed based on anecdotal accounts.
Variation by Administrative Structure
Differences were examined across local agencies, based upon the administrative structure of CPS services.(4) In some States, the entire CPS program is managed by the State, while in other States, CPS is managed by county agencies. Three categories of agencies were studied--State-administered agencies, county-administered agencies, and State-administered agencies with strong county-level management structure.
Agencies in State-administered systems with a strong county structure had more expansive and flexible investigations than other agencies. These agencies were more likely to always extend the investigation response to all children in the household and to include such activities as discussing the case with a multidisciplinary team, as part of the investigation. These agencies also faced fewer obstacles to timely completion of the investigation. Agencies in State-administered systems with strong county structure rarely reported obstacles like preparing materials for the case or court record and handling language barriers.
For the screening/intake and investigation function, 43 percent of State-administered agencies were estimated to have specialized staff members, while 23 percent of county- and 32 percent of State-administered with a strong county structure had specialized staff. Differences between State-administered agencies and county-administered agencies suggest that county agencies might not have specialized in the screening and intake function to the same degree that State-administered agencies did. In general, it appeared that at least one-half of the staff assigned to this function at either the caseworker or supervisory level was assigned to other responsibilities.
In terms of the alternative response function, agencies in State-administered systems with strong county structure appeared more consistent in how they conducted alternative response than other types of agencies. These agencies had more required practices to perform before completing the alternative response.
Site Visits to Local Agencies
Eight site visits were made to localities ranging from suburban communities to rural communities. Three sites were in county-administered systems and the remaining five sites were in State-administered systems. The objective of the site visits was to gain a deeper understanding of the changes in CPS practice being undertaken. Activities included interviewing key stakeholders in the CPS system and obtaining documentation of the reform efforts underway.
Several trends were identified as a result of the site visits. Many agencies reported having undertaken broad-based changes in their philosophy of service. Seven of the eight sites had conducted organizational and administrative changes. One-half of the agencies had moved to conducting joint CPS and law enforcement investigations and one-half of the sites had changed the way in which the agency worked with families. Five sites had changed or were in the process of changing community collaboration efforts and one-half of the sites had adopted new practices for working with domestic violence programs.
Conclusions
The LAS provides a rich source of information about the processes and practices of CPS agencies. The survey's focus on the different functional areas as well as reform efforts within the agencies contributes to the overall study's ability to describe the status of the CPS system nationally and to characterize the reform efforts underway. With a unique national perspective lacking in other research efforts, the LAS findings can help both policy makers and practitioners understand how CPS agencies nationwide operate.
The LAS findings provide concrete evidence of both the commonalities and diversity of CPS practices throughout the Nation. The diversity is at the very core of CPS practice. While all CPS agencies investigated child abuse and neglect, they did not all have the same lead responsibility. To a certain degree, the more serious the type of maltreatment, the more likely they were to share the responsibility for investigating the maltreatment. This obviously requires clear lines of responsibility and collaboration to be effective.
Furthermore, the majority of CPS agencies conceptualized their practice as having different responses for different types of maltreatment. Not only were responsibilities shared, but the responses were different. In general, alternative responses were less focused on obtaining forensic evidence, but the clear difference was that they focused on different types of maltreatment than did investigation.
The LAS provides data on CPS practice as it existed in 2002. It is hoped that it will assist in planning for improved CPS practices in future years.
Endnotes
1. Intake refers to the assignment by the CPS agency of a worker to respond to a screened-in referral alleging child abuse and neglect.
2. These other responses are called alternative response.
3. Calls that are received by the CPS agency are considered to be referrals to the agency, which may be screened in or screened out by the agency. Screened-in referrals are considered reports alleging child abuse or neglect.
4. Administrative structure refers to the method of assigning organizational authority for CPS among subjurisdictions in a State.
Chapter 1. Introduction
1.1 Overview of the Study
This report presents the findings from the Local Agency Survey component of the National Study of Child Protective Services Systems and Reform Efforts. The study was designed to describe the national status of the child protective services (CPS) system and to characterize any reform efforts underway. Acknowledging the state of change that currently exists within the field of CPS and the dynamic nature of the relationship between policy and practice, the CPS systems are being studied from three main perspectives — the State policies and mandates that define CPS functions and specify how these functions are carried out; local CPS agency organization and practices that implement CPS functions; and innovative reform efforts that seek to restructure, redefine, or reformulate the purposes and functions of CPS. These perspectives and the data collection methods used to address them are briefly detailed below.
The overarching responsibility of the CPS agency (most commonly a division or unit within a child welfare department) is to provide the initial response to the needs of children who may have been abused or neglected. Given this mandate to conduct the first response to potential critical emergencies, much of CPS policy focuses on what conditions require a response and what type of response is required.
The first study component addressed policy and consisted of a review of State policy manuals and followup interviews with State administrators. The State policy review focused on those policies and mandates that relate to three primary CPS functions — screening, investigation, and alternative response.1
The review began with extensive reviews of State policy manuals. Next, the Study Team interviewed State CPS administrators to confirm and expand upon the information obtained from the policy review. The interview protocol included separate sections for each CPS function. Each section began by establishing a definition for the function in question and the criteria used in carrying out the function.2
The second study component examined the functions and operational practices conducted by local agencies in order to meet the State and local mandates and policy requirements. This component was addressed through a Local Agency Survey (LAS) of a nationally representative sample of local CPS agencies. The LAS included questions about the organizational structure of the local CPS agencies, the procedures by which the key CPS functions were carried out at the local level, and the ways in which local CPS agencies interfaced with other governmental and community agencies to conduct key CPS functions. The LAS used the findings from the State policy review as a backdrop for the design of the survey and adopted a similar structure and organization in terms of topical areas within the survey. This report presents the findings from this component.
The third component examined the innovative approaches being implemented in local agencies to address the mandates and policies of CPS and explored the degree to which practice is changing to include these new reform efforts. The nature of cutting edge reform is such that there are unique practices that cannot necessarily be anticipated or fully captured through highly structured interview questions that have been wholly formulated in advance. As a result, this research area required an open-ended qualitative approach that examined the problems that the reform efforts sought to address, the critical features of the reform effort, and the results of the reform effort. Consequently, the primary data collection effort in this area involved site visits to a small sample of local CPS agencies to document some of the changes in the field. The agencies were selected based upon their responses to a module in the LAS that asked CPS agencies to describe any recent changes in a number of key areas related to operation and functions of CPS.3
The National Study of Child Protective Services Systems and Reform Efforts was structured around three research components. The emphasis of the State policy review was on the ways in which State CPS mandates and policies defined the roles and key functions of the CPS, as well as the ways in which State mandates and policies provided criteria that guided the manner in which the key CPS functions are carried out. The emphasis of the LAS was the organization of CPS and the procedures by which the key CPS functions were carried out. Finally, the local site visits emphasized current directions in agency practices for carrying out key CPS functions.
1.2 Local Agency Survey
The objective of the LAS was to obtain detailed information on the types of activities that were conducted under the rubric of child protective services (CPS) practice at the local agency level and to describe variations in practice throughout the nation. This survey effort was a pioneer in the field because it collected information about CPS agency practice from a nationally representative sample of agencies. In the past, the understanding of how CPS agencies operate has relied on anecdotal information, focused studies in local jurisdictions, or purposive samples that provided an incomplete view of CPS agencies. The national perspective of the LAS offered a unique opportunity to quantify the distribution of CPS agencies in terms of how the work was conducted in different realms.
The LAS focused on CPS work in terms of determining:
- The core functions of CPS;
- The purpose of these core functions;
- How the CPS agencies interface with other governmental and community agencies in implementing the core CPS functions;
- The organizational structure of local CPS agencies; and
- The multiplicity of procedures and activities that underlie the core CPS functions of CPS agencies.
The survey also sought to document the range of reform efforts or changes underway around the Nation. Across all of these areas, the LAS was designed to help understand the commonalities and differences found among programs and practices across the Nation.
The LAS sampling procedures were designed to select a nationally representative sample of counties, stratified by whether they were county- or State-administered child welfare systems, and by whether they were considered to be urban or rural. Census regions were also taken into account to ensure that the county sample was spread evenly across regions. Using these stratifications, a total of 375 counties were sampled. All local CPS agencies that served the sampled counties were targeted for LAS data collection.
The LAS used a modular questionnaire to determine the functions and practices of local CPS agencies. The Administration Module collected information on the basic organization of the agency. Three modules focused on the functional areas of CPS work — the Screening/Intake Module gathered data on the screening practices of the agencies; the Investigation Response Module collected information on the manner in which the agency conducted investigations of alleged maltreatment; and the Other CPS Response Module enabled agencies to describe alternative approaches to responding to allegations of maltreatment other than traditional investigations. Finally, the fifth module — New Directions Module — asked agencies to document recent changes in CPS practice.
For each module, the person most knowledgeable about CPS practice in the particular topical or functional area was asked to respond to the survey questions. While a single individual may not have been able to give a fully comprehensive description of agency practice, relying on the most knowledgeable person for each module helped ensure a reasonably accurate portrayal of practice without placing undue burden on each agency.
The data collection procedures involved State recruitment, agency recruitment, survey distribution and retrieval, and nonresponse followup. Together, these procedures resulted in an 80 percent response rate.
The survey data were entered into a database and weights were developed. Weighting took into account the probability of selecting the local CPS agencies and adjusted for nonresponse, allowing the LAS data to produce national estimates. The final analysis file was configured at the agency level so that it contained a unique agency record for each responding agency. The sum of all the agency-level final weights provided an estimate of the number of local CPS agencies in the nation equal to 2,610 agencies. Because all LAS findings are presented as national estimates derived from a sample, their statistical precision is qualified by sampling error. This report provides estimates of the numbers and percentages of the Nation's 2,610 local CPS agencies with different practices and procedures, with the precision of the estimates indexed using the 95 percent confidence interval.4 As an example, the 95 percent confidence interval for the estimated national total of 2,610 local CPS agencies is 2,410 to 2,810 agencies.
1.3 Organization of Report
This report is organized into a series of chapters that discuss the analytical findings from the LAS. Chapter 2 describes the survey findings related to the structure and organization of CPS agencies. It presents information in terms of both estimates of CPS agencies with the various characteristics and of the population of children served by CPS agencies. Chapter 3 examines local agency practices and procedures for receiving and screening child maltreatment referrals and provides details on the screening/intake function with sections on the receipt of referrals, the processing of referrals, and the role of the State hotline. In Chapter 4, the findings related to both the investigation response and the alternative response are provided in terms of the types of responses, the response features and activities, the roles of workers and supervisors, and the difficulties encountered in conducting the response. Chapter 5 discusses findings related to the role of law enforcement. Chapter 6 describes the degree and types of change within CPS agencies. Chapter 7 presents the examples of change based on site visits to local agencies, and Chapter 8 provides discusses difference among agencies by administrative structure. Chapter 9 provides a summary conclusion.
Appendix A provides detail on methodology.
Endnotes
1. Alternative response is a maltreatment disposition system that provides for responses other than "Substantiated," "Indicated," and "Unsubstantiated." In this type of system, children may or may not be determined to be maltreatment victims. Although the survey module was labeled "other CPS response," in the report the term "alternative response" is used.
2. The report, Review of State CPS Policy, of the National Study of Child Protective Services Systems and Reform Efforts, is available on the Internet site for the Office of the Assistant Secretary for Planning and Evaluation (ASPE) at http://aspe.hhs.gov/hsp/CPS-status03. Posted: 2003.
3. The Site Visits Report, of the National Study of Child Protective Services Systems and Reform Efforts, is available on the Internet site for the Office of the Assistant Secretary for Planning and Evaluation (ASPE) at http://aspe.hhs.gov/hsp/CPS-status03. Posted: 2003.
4. The 95 percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval.
Chapter 2. Agency Administration and Staffing
This chapter describes the overall operation of CPS agencies. Topics addressed in the chapter include national estimates of the number of agencies, staffing patterns, worker assignments and workload, and the role of the CPS agencies in providing followup services. Subsequent chapters discuss each of the core functions of screening and intake, investigation, and alternative response, in greater detail.
Data in this chapter are presented in terms of agencies and the number of children in the population living in the jurisdictions of these agencies. These children were not necessarily served by the CPS agency, but would be if the need arose.
2.1 National Coverage
Nationally, all jurisdictions are covered by local agencies that conduct screening and intake and investigation. A new finding was that 64 percent of agencies provided an alternative response and that more than one-half of the Nation's children (54%) live in a jurisdiction with both an investigation response and an alternative response (Table 2-1).
| Functions | Agency | Number of children residing in areas served by agencies | ||
|---|---|---|---|---|
| Estimate ( C.I. ) ** |
Percent * | Estimate ( C.I. ) |
Percent | |
| Screening/intake at local agency | 2,590 (2,390-2,790) |
99% | 71,382,000 (68,714,000-74,049,000) |
98% |
| Investigation | 2,600 (2,400-2,800) |
100% | 72,913,000 (72,334,000-73,492,000) |
100% |
| Alternative response | 1,660 (1,460-1,860) |
64% | 39,280,000 (24,111,000-54,450,000) |
54% |
| * Percentages are not additive because agencies were included in each applicable row (category). ** The 95 percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval. |
||||
2.2 CPS Staffing
While there is considerable variation in the size of CPS agencies, the national average per agency was 26 staff including 17 social workers or caseworkers, with 3 supervisory staff (Table 2-2). Additional analyses indicate that one-quarter quarter of agencies had approximately 4 or fewer social workers and another one-quarter had 15 or more staff. Other staff, which added another four to five staff per agency, included support staff, case aides, specialist workers and mangers. Less than one Full-Time Equivalent (FTE) employee per category (e.g. caseworker, supervisor, etc.) worked part time, on average, across agencies.
| Worker category | Average number of full-time workersa | Average number of part-time workersb | Average number of staff |
|---|---|---|---|
| Estimate (C.I.) |
Estimate (C.I.) |
Estimate (C.I.) |
|
| Social workers or caseworkers | 16 (8-24) |
<1 (<1-1) |
17 (8-26) |
| Supervisors | 3 (2-5) |
<1 (<1-<1) |
3 (2-5) |
| Other worker category | 2 (<1-4) |
<1 (<1-<1) |
2 (<1-4) |
| 2nd other worker category | 2 (0-4) |
<1 (<1-<1) |
2 (<1-4) |
| 3rd other worker category | <1 (<1-2) |
<1 (<1-<1) |
<1 (<1-2) |
| Total | 24 (11-37) |
1 (<1-2) |
26 (12-39) |
| a Full time refers to the time spent on CPS activities. b Part time refers to the time spent on CPS activities. |
|||
Workers on the staff of CPS agencies are mostly comprised of individuals with bachelor's degrees. Nearly one-half of all supervisors have an advanced degree, with a Master of Social Work (M.S.W.) . Agencies averaged 3 staff with less than a Bachelor's degree, 13 staff with a bachelor's degree, 3 with a Master of Social Work (M.S.W.) degree, and 1 employee (or staff person) with some other type of advanced degree. The majority of workers, 11 on average per agency, had a bachelor's degree, and 2 on average per agency had an M.S.W. degree. For supervisors, each agency on average had one supervisor with a Bachelor's degree and one with an M.S.W. In the other worker category, agencies averaged one person on staff with less than a bachelor's degree (Table 2-3).
| Worker category | Average number with less than bachelor's degree | Average number with only bachelor's degree | Average number with M.S.W. | Average number with other advanced degree |
|---|---|---|---|---|
| Estimate (C.I.) |
Estimate (C.I.) |
Estimate (C.I.) |
Estimate (C.I.) |
|
| Social workers or caseworkers | <1 (<1-<1) |
11 (6-16) |
2 (<1-3) |
<1 (<1-<1) |
| Supervisors | <1 (<1-<1) |
1 (<1-1) |
1 (1-2) |
<1 (<1-<1) |
| Other worker category | 1 (<1-3) |
<1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-<1) |
| 2nd other worker category | 1 (0-2) |
<1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-<1) |
| 3rd other worker category | <1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-<1) |
| Total Staff | 3 (<1-6) |
13 (<1-18) |
3 (1-6) |
1 (1-2) |
It is estimated that only a small number of staff positions were vacant among CPS local agencies at the time of the survey (Table 2-4). On average, each agency had 0.6 vacancies, of which 0.4 were social workers or caseworkers. More than 75 percent of agencies indicated that they had no staff vacancies.
| Position worker category | Average number of staff |
|---|---|
| Estimate (C.I.) |
|
| Social workers or caseworkers | 0.4 (<1-<1) |
| Supervisors | 0.0 (<1-<1) |
| Other worker category | 0.0 (<1-<1) |
| 2nd other worker category | 0.1 (<1-<1) |
| 3rd other worker category | 0.0 (<1-<1) |
| Total | 0.6 (0-<1) |
2.3 Specialization of Staff Functions
any agencies elect to have different workers or other staff specialize in providing the primary CPS functions; screening/intake and investigation. When an alternative response is provided, some agencies also have specialist staff perform this function. Nationally, a slight majority of agencies are specialized to at least some degree with respect to these functions.
With respect to the intake function, on average four social workers or caseworkers were exclusively assigned to the function and an additional four social workers or caseworkers were assigned to the function, but had other responsibilities. Less than one supervisor was exclusively assigned to the screening and intake function, and one supervisor was assigned who had additional responsibilities. Less than one other type of staff was assigned. In addition, two part-time staff were assigned across all categories of staff (Table 2-5).
| Position | Average number of full- time workersa | Average number of part- time workersb | Average number of Staff |
|---|---|---|---|
| Estimate (C.I.) |
Estimate (C.I.) |
Estimate (C.I.) |
|
| Workers who only conducted screening/intake | 3 (<1-6) |
<1 (<1-1) |
4 (<1-7) |
| Workers who conducted screening/intake in addition to other responsibilities | 3 (3-4) |
<1 (<1-1) |
4 (3-5) |
| Supervisors who only supervised screening/intake | <1 (<1-1) |
<1 (<1-<1) |
<1 (<1-1) |
| Supervisors who supervised screening/intake in addition to other responsibilities | 1 (<1-1) |
<1 (<1-<1) |
1 (1-2) |
| Other staff assigned to screening/intake | <1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-1) |
| Total | 9 (6-13) |
2 (<1-3) |
11 (8-15) |
| a Full time refers to the time spent on CPS activities b Part time refers to the time spent on CPS activities |
|||
Slightly more workers specialize in providing investigations, compared to workers who are assigned also to other tasks in addition to investigation. An average of four workers were exclusively assigned to the investigation function and three were assigned to other responsibilities. The average number of social workers or caseworkers who were exclusively assigned to the investigation function was five with three additional staff who were also assigned other responsibilities. For supervisors, the average number exclusively assigned to investigation was less than one, with one additional supervisor assigned who had other responsibilities. Less than one other type of staff person, on average, was assigned to this function (Table 2-6).
| Position | Average number of full- time workersa | Average number of part- time workersb | Average number of staff |
|---|---|---|---|
| Estimate (C.I.) |
Estimate (C.I.) |
Estimate (C.I.) |
|
| Workers who only conducted investigations | 4 (3-6) |
<1 (<1-1) |
5 (3-6) |
| Workers who conducted investigations in addition to other responsibilities | 3 (2-4) |
<1 (<1-1) |
3 (3-4) |
| Supervisors who only supervised investigation | <1 (<1-1) |
<1 (<1-<1) |
<1 (<1-1) |
| Supervisors who supervised investigation in addition to other responsibilities | 1 (<1-1) |
<1 (<1-<1) |
1 (1-1) |
| Other staff assigned to investigation | <1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-1) |
| Total | 10 (8-12) |
1 (<1-2) |
11 (9-13) |
| a Full time refers to the time spent on CPS activities b Part time refers to the time spent on CPS activities |
|||
Most agencies indicate that in organizing the staffing across screening/intake and investigation functions, they have chosen to have staff specialize in these functions to at least some degree. Table 2-7 illustrates that combined 51 percent of agencies either have staff who exclusively perform one function only, or usually provide only one and temporarily are sometimes assigned to the other function. Of these agencies, 33 percent were specialized across these functions; and some agencies (19%) had workers switched between screening/intake and investigations on an as-needed basis. For 42 percent of agencies nationwide, staff routinely combined the screening/intake and investigation functions, and a small number of agencies (5%) employed some other process.
Compared to the number of agencies that specialize, almost all children nationwide were be living in under the jurisdiction s that were served by agencies whose workers are specialist providers of screening/intake or investigation functions. It was estimated that 57 percent of children were residing in areas served by a gencies where workers are exclusively providing either screening/intake or investigations. Another 22 percent of children were living in jurisdictions served by agencies that have specialist workers who are assigned to another function on an as-needed basis. In contrast, only 16 percent of children nationwide were estimated to be under the jurisdiction of agencies where personnel were not specialized (Table 2-7).
| Staff | Agency | Number of children residing in areas served by agencies | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Different workers for screening/intake and investigation | 870 (700-1,050) |
33% | 41,492,000 (31,305,000-51,680,000) |
57% |
| When needed, an intake worker can conduct an investigation, or an investigation worker can conduct screening/intake | 490 (360-610) |
19% | 16,290,000 (9,035,000-23,544,000) |
22% |
| Workers routinely conduct both screening/intake and investigation | 1,090 (910-1,280) |
42% | 11,985,000 (7,662,000-16,309,000) |
16% |
| Other | 120 (70-180) |
5% | 2,865,000 (1,129,000-4,600,000) |
4% |
| No response | 30 (1-60) |
1% | 578,000 (<1-1,219,000) |
<1% |
| Total | 2,610 (2,410-2,810) |
100% | 73,210,000 (73,210,000-73,210,000) |
100% |
The pattern of staff specialization is similar for agencies that provide the alternative response function. One difference, however, is that most workers in agencies with alternative response are assigned to other responsibilities. An average of four caseworker staff were assigned exclusively to providing alternative response, and an additional four were assigned to this function who also had other responsibilities. There was less than one other type of staff member assigned and about one part time staff person assigned. On average, 11 staff were assigned to alternative response options (Table 2-8).
| Position | Average number of full- time workersa | Average number of part- time workersb | Average number of staff |
|---|---|---|---|
| Estimate (C.I.) |
Estimate (C.I.) |
Est imate (C.I.) |
|
| Workers who only conducted this response | 3 (2-5) |
<1 (<1-1) |
4 (2-6) |
| Workers who conducted this response in addition to other responsibilities | 4 (3-4) |
<1 (<1-1) |
4 (3-5) |
| Supervisors who only supervised this response | <1 (<1-1) |
<1 (<1-<1) |
<1 (<1-1) |
| Supervisors who supervised this response in addition to other responsibilities | <1 (<1-1) |
<1 (<1-<1) |
1 (<1-1) |
| Other staff assigned to this response | <1 (<1-<1) |
<1 (<1-<1) |
<1 (<1-2) |
| Total | 10 (7-12) |
1 (<1-2) |
11 (8-14) |
| a Full time refers to the time spent on CPS activities b Part time refers to the time spent on CPS activities |
|||
Among agencies that provide an alternative response, less than a majority assign specialist workers to screening/intake and the provision of the alternative response. Compared to screening/intake and investigations (Table 2-7, above), Table 2-9 provides similar data describing the pattern of staff allocation between areas where agency staff performed screening and intake and also alternative response. For many agencies providing an alternative response more staff (42%) were assigned to both functions. Fewer agencies were specialized (33%), even fewer assigned staff to either function on an as-needed basis (15%). With respect to national estimates of children, 64 percent were residing in a jurisdiction of agencies that used specialized staff to some degree (48% exclusively, and 16% with workers assigned temporarily), and 24 percent lived in areas served by agencies whose staff performed both screening/intake and the alternative response.
| Staff | Agency | Number of children residing in areas served by agencies | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Different workers for screening/intake and alternative response | 550 (400-700) |
33% | 18,726,000 (8,541,000-28,912,000) |
48% |
| When needed, an intake worker can conduct an alternative response or vice versa | 260 (150-370) |
15% | 6,089,000 (2,386,000-9,792,000) |
16% |
| Workers routinely conduct both screening/intake and alternative response | 690 (540-850) |
42% | 9,557,000 (5,210,000-13,904,000) |
24% |
| Other | 130 (70-200) |
8% | 3,962,000 (1,307,000-6,618,000) |
10% |
| No response | 20 (0-40) |
1% | 945,000 (72,000-1,818,000) |
2% |
| Total | 1,660 (1,460-1,860) |
100% | 39,280,000 (24,111,000-54,450,000) |
100% |
For agencies with an alternative response option it was also possible to examine the degree to which workers specialized in providing the investigation and alternative response functions. Most agencies do not have specialist staff providing this function, and the same workers tend to provide both these functions. In more than one-half of the agencies (59%), workers performed both the investigation and alternative response functions, fewer agencies were exclusively specialized (21%), and fewer still switched staff between the two functions (11%), (Table 2-10).
Forty-five percent of children nationwide lived in jurisdictions where agency staff performed both responses, 33 percent where agencies employed specialized staff, 11 percent where agencies used staff who switched roles on an as-needed basis, and 8 percent where agencies used some other allocation method.
| Staff | Agency | Number of children residing in areas served by agencies | ||
|---|---|---|---|---|
| Estimate (C.I .) |
Percent | Estimate (C.I.) |
Percent | |
| Different workers for investigation and alternative response | 350 (210-490) |
21% | 12,851,000 (6,839,000-18,864,000) |
33% |
| When needed, an investigation worker can conduct an alternative response, or vice versa | 190 (100-270) |
11% | 4,247,000 (1,121,000-7,373,000) |
11% |
| Workers routinely conduct both investigation and alternative response | 980 (800-1,160) |
59% | 17,582,000 (9,073,000-26,090,000) |
45% |
| Other | 120 (60-170) |
7% | 3,034,000 (394,000-5,674,000) |
8% |
| No response | 30 (0-50) |
2% | 1,566,000 (206,000-2,925,000) |
4% |
| Total | 1,660 (1,660-1,860) |
100% | 39,280,000 (24,111,000-54,450,000) |
100% |
2.4 CPS Activity and Workload
The average volume of services for CPS agencies sets the context for the level of response effort that CPS agencies must support. Nationally, the number of referrals received per agency was estimated to average 64 per month. The average number of completed investigations was estimated to be 43 per month and involved 93 children. An estimated 16 alternative response cases were processed each month that involved 32 children (Table 2-11).
| Function | Average number |
|---|---|
| Estimate (C.I.) |
|
| Number of referrals for screening/intake | 64 (39-89) |
| Number of completed investigations | 43 (19-67) |
| Number of children in completed investigated | 93 (37-149) |
| Number of completed alternative responses | 16 (10-22) |
| Number of children in completed alternative responses | 32 (19-44) |
The staff workload of CPS agencies is often of concern in that excessive workload may lead to inadequate services and jeopardize the safety of children. The following discussion describes the perceptions of agencies with respect to workload concerns.
Most agencies perceive that they are currently operating with excessive workloads. In addition, more than three-quarters of the Nation's children were residing in jurisdictions served by agencies with excessive workload in one or more CPS functions. Table 2-12 shows the estimated number of agencies with one or more of the three CPS functions (screening/intake, investigation, and alternative response) that reported excessive workloads. For most agencies (69%), workload was perceived as excessive for one or more functions, but for almost one-third of the agencies (31%) excessive workload was not a current concern. Of those agencies with workload concerns, one-third (33%) had issues concerning the three functions, one-fifth (21%) had issues with one of the three functions, and 15 percent had issues with two functions.
| Workload | Function | |||||
|---|---|---|---|---|---|---|
| Screening and Intake | Investigation | Alternative Response | ||||
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Excessive workload for function | 100 (50-160) |
20% | 360 (250-480) |
70% | 50 (5-100) |
10% |
| Excessive workload not a concern for function | 420 (300-540) |
80% | 150 (86-220) |
30% | 180 (100-270) |
36% |
| No Response | -- | -- | -- | -- | 280 (190-370) |
54% |
| Total | 520 (380-650) |
100% | 520 (380-650) |
100% | 520 (380-650) |
100% |
More than one-half (53%) of children were under the jurisdiction of agencies with excessive workload across all CPS functions, 14 percent under the jurisdiction of agencies with excessive workload in one function, and 10 percent under the jurisdiction of agencies with excessive workload in two or more functions.
Among agencies with workload concerns for only one CPS function (Table 2-13), investigation was the most often indicated as a source of concern (70%), followed by screening (20%), and alternative response (10%).
| Concern | Agency | Number of children residing in areas served by agencies | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Excessive workload for all functions | 810 (670-940) |
33% | 34,445,000 (22,072,000-46,817,000) |
53% |
| Excessive workload for one function | 520 (380-650) |
21% | 9,327,000 (4,770,000-13,885,000) |
14% |
| Excessive workload for multiple (but not all) functions | 360 (230-480) |
15% | 6,717,000 (2,845,000-10,589,000) |
10% |
| Excessive workload for no functions | 750 (600-900) |
31% | 14,940,000 (9,683,000-20,197,000) |
23% |
| Total | 2,430 (2,220-2,640) |
100% | 65,429,000 (60,150,000-70,708,000) |
100% |
2.5 The Role of CPS in Providing Followup Services
A long standing concern regarding CPS is the nature and extent of service provision in addition to the basic requirements of CPS functions. In this section, an overall view of service provision — both during and after CPS intervention — is discussed.
Most CPS agencies are able to provide services following an investigation regardless of the determinations made during the investigation. Table 2-14 provides a breakdown of the criteria used by agencies following a CPS investigation. Nearly three-quarters of agencies (74%) were allowed to provide services regardless of the investigation determination. A smaller fraction of agencies (15%), were allowed to offer services in the event that a report was substantiated or indicated, and even fewer agencies (11%) offered no services other than the investigation.
| Practice | Investigation response agency | |
|---|---|---|
| Estimate (C.I.) |
Percent | |
| Allowed to offer services, regardless of determination | 1,930 (1,730-2,130) |
74% |
| Allowed to offer services, only when referral is substantiated | 390 (250-520) |
15% |
| No services are offered at conclusion of investigation response | 290 (200-390) |
11% |
| Total | 2,610 (2,410-2,810) |
100% |
Most agencies are able to offer an extensive range of support services during and following the investigation or alternative response. Taking into account that some agencies did not provide an alternative response option, the relative frequency of service types was fairly consistent when comparing investigation and alternative response. More than three-quarters of agencies were estimated to be able to provide parenting classes, substance abuse programs, and child care. Agencies were least likely to offer financial planning, employment services, dental exams, and tutoring for both investigation and alternative response (Table 2-15).
Agencies tended to have flexible guidelines concerning when to provide services after the investigation was concluded with either no set timeframes or decisions made by supervisors. For most States there was either no time limit (22%) or the decision regarding the timing of services was made by a supervisor (27%). In contrast, a few agencies (18%) set time limits — the most common response being within 31-60 days (8%), followed by 1-30 days (6%), and 61-90 days (4%) as shown in Table 2-16.
For agencies with an alternative response, the same basic pattern is seen for investigations. However, when the numbers were adjusted to exclude agencies without an alternative response option, it is estimated that about 61 percent of the agencies had either no time limits (31%) or that it was the supervisor's discretion (30%). For these agencies, only 11 percent had set time limits for when services are to be initiated.
| Service | Investigation response agency | Alternative response agency | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Parenting classes | 2,270 (2,080-2,460) |
87% | 1,420 (1,240-1,610) |
86% |
| Grief counseling | 1,750 (1,550-1,950) |
67% | 1,140 (970-1,300) |
68% |
| Marital counseling | 1,840 (1,650-2,030) |
71% | 1,230 (1,060-1,390) |
74% |
| Family systems therapy | 1,920 (1,720-2,120) |
74% | 1,210 (1,020-1,400) |
81% |
| Child therapy | 2,130 (1,940-2,330) |
82% | 1,330 (1,150-1,500) |
61% |
| Substance abuse programs | 2,200 (1,990-2,400) |
84% | 1,350 (1,170-1,530) |
81% |
| Medical exam | 1,730 (1,540-1,920) |
66% | 1,010 (880-1,150) |
61% |
| Dental exam | 1,500 (1,310-1,690) |
58% | 860 (720-1,010) |
52% |
| Homemaker/chore | 1,630 (1,410-1,820) |
62% | 1,070 (910-1,230) |
64% |
| Transportation | 1,660 (1,500-1,820) |
64% | 1,070 (910-1,220) |
64% |
| Tutoring | 1,060 (880-1,250) |
41% | 780 (620-940) |
47% |
| Financial planning | 1,470 (1,240-1,710) |
56% | 920 (760-1,090) |
56% |
| Advocacy services | 1,790 (1,620-1,960) |
69% | 1,120 (950-1,280) |
67% |
| Housing assistance | 1,670 (1,470-1,870) |
64% | 1,100 (930-1,270) |
66% |
| Child care | 1,990 (1,790-2,190) |
76% | 1,270 (1,100-1,440) |
77% |
| Employment services | 1,500 (1,300-1,700) |
58% | 900 (740-1,050) |
54% |
| Domestic violence services | 1,990 (1,790-2,190) |
76% | 1,230 (1,050-1,410) |
74% |
| Other service category one† | 220 (140-310) |
9% | 130 (50-210) |
8% |
| Other service category two† | 80 (20-140) |
3% | 10 (<1-20) |
<1 |
| * Percentages are not additive because agencies were included in each applicable row (category). †Survey Respondents were asked to respond to two "other service" categories. Since these represent different services for the agencies with more than one, and since not all agencies provided data for two services, they are separated in the table. |
||||
| Timeframe | Investigation response agency | Alternative response agency | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| No time limit | 560 (390-740) |
22% | 510 (370-650) |
31% |
| Time limit determined by supervisor | 710 (560-870) |
27% | 500 (360-640) |
30% |
| No more than 1-30 days | 160 (80-250) |
6% | 20 (0-40) |
1% |
| No more than 31-60 days | 200 (100-200) |
8% | 80 (30-130) |
5% |
| No more than 61-90 days | 110 (30-180) |
4% | 80 (10-140) |
5% |
| Other | 800 (640-960) |
31% | 270 (140-400) |
16% |
| No response | 70 (20-120) |
3% | 200 (130-270) |
12% |
| Total | 2,610 (2,410-2,810) |
100% | 1,660 (1,460-1,860) |
100% |
| * The categories "Investigation response Agency" and "Alternative response Agency" are not mutually exclusive as all agencies providing an alternative response also provide an investigation response. | ||||
When followup services are provided, most agencies require that the worker who conducted the investigation either prepare or participate in the formulation of the service plan. As seen in Table 2-17, more than one-half of the agencies (54%) either had the worker assist in the development of the service plan (29%) or act as a consultant to the worker who will actually provide the services (25%). In either case, the implication is that the authority for the case was transferred at that stage to another worker in more than one-half of the agencies. In 20 percent of agencies, the worker who conducted the response had only minimal involvement in the service provision aspect of the case. Examples of "other roles" included that the same worker continued providing services (the most common response), that the worker carried the case for a specified time following the investigation, or that the worker developed the case plan before the case was transferred.
For alternative response, the most common practice was "other" (42%). Examples of responses indicated that the worker who provided the response continued to provide services; however, for some agencies, this reflected the provision of the service by a private provider or that the case was closed after the alternative response was provided.
| Practice | Investigation response agency | Alternative response agency | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Worker transfers case with minimal involvement | 510 (370-650) |
20% | 210 (110-310) |
13% |
| Worker assists new service worker in making a service plan | 760 (600-920) |
29% | 330 (220-440) |
20% |
| Worker is a resource for the service worker | 640 (500-780) |
25% | 270 (160-380) |
16% |
| Other | 630 (480-780) |
24% | 700 (560-840) |
42% |
| No response | 70 (30-110) |
3% | 150 (90-220) |
9% |
| Total | 2,610 (2,410-2,810) |
100% | 1,660 (1,460-1,860) |
100% |
| * The categories "Investigation response Agency" and "Alternative response Agency" are not mutually exclusive as all agencies providing an alternative response also provide an investigation response. | ||||
Many agencies did not have any type of arrangement for prioritizing services with other providers — 43 percent of agencies for investigations, and 45 percent for agencies with an alternative response did not have an arrangement. Of those agencies that did have an arrangement, most had an arrangement with multiple providers comprising some combination of mental health, substance abuse, and other providers — 33 percent for investigations, and 34 percent for alternative response. Roughly 7 to 8 percent of investigation response agencies indicated that they had only one priority arrangement with either a mental health, substance abuse, or other provider. Similarly, the percent for agencies that provide alternative response ranged from 5 to 6 percent of agencies (Table 2-18). Other provider types included domestic violence agencies, sexual maltreatment agencies, pediatricians, private psychologists, housing authorities, public assistance agencies, and so forth.
| Arrangements | Investigation response agency | Alternative response agency | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Agency does not have priority status arrangements | 1,130 (940-1,320) |
43% | 750 (590-900) |
45% |
| Agency has priority status arrangements with mental health providers | 190 (110-270) |
7% | 80 (30-130) |
5% |
| Agency has priority status arrangements with substance abuse providers | 190 (120-260) |
7% | 100 (50-150) |
6% |
| Agency has priority status arrangements with other providers | 200 (130-280) |
8% | 100 (40-160) |
6% |
| Agency has priority status arrangements with multiple types of services providers | 860 (700-1,010) |
33% | 560 (410-710) |
34% |
| No response | 40 (0-70) |
1% | 80 (40-120) |
5% |
| Total | 2,610 (2,410-2,810) |
100% | 1,660 (1,460-1,860) |
100% |
2.6 Conclusion
The findings presented above are intended to paint a broad picture and provide context for the more detailed aspects of CPS service delivery that are described in the following chapters. From the perspective of primary CPS functions, virtually all agencies are providing screening and intake, and all are providing investigation responses. More than one-half of the agencies are also providing some form of an alternative response to children and families where maltreatment is alleged, in addition to the primary investigation function. The average number of staff members in each agency is 26, of which 7 are social or caseworkers and 3 are supervisors.
Regarding the specialization of staff in performing the CPS functions, the degree of specialization depends on whether an alternative response function exists. A slight majority of agencies operate with specialized staff in their screening/intake and investigation functions. When an alternative response is available, the screening/intake and alternative response are not specialized quite as often. Also, for agencies that provide alternative response, fewer than one-half of all agencies are specialized so that the same workers are providing both investigation and the alternative response. However, when the numbers of children residing in counties served by agencies are considered, nationally more children reside in counties that are served by agencies with staff who specialize in all CPS functions. For example, 54 percent of all children reside in jurisdictions that are served by agencies where workers either specialize in screening/intake or who exclusively provide investigations. This latter finding indicates that in addition to the presence of alternative response, agency size is also a factor in the degree of specialization.
The findings also addressed questions about the numbers of services and the staffing resources available to agencies. On average, CPS handled 64 referrals per month, and completed 43 investigations and 16 alternative responses, if they offered this response.
Most agencies believe that their workloads are excessive. Almost 70 percent of agencies thought this was the case for at least one function, if not all three. Where only one function was involved, for 70 percent of agencies it was the investigation function. In contrast to the 70 percent of agencies that felt that excessive workload is a concern, three-quarters of the Nation's children resided in jurisdictions whose CPS agencies had this concern. Thus, on the basis of the population of children residing in jurisdictions served by the agencies, it appears that agencies in areas with larger child populations tended to report excessive workload as a concern more frequently than agencies serving jurisdictions with smaller populations.
Most agencies were allowed to provide services to any child and family regardless of the outcome of the investigation or alternative response or whether a child was found to be maltreated or not. Almost all agencies had a wide range of services that could be made available.
Chapter 3. Screening and Intake
This chapter examines local CPS agency practices and procedures for receiving and screening child maltreatment referrals.1 The sections cover CPS practices on receiving and processing referrals, and on the role of the State hotline.
There was little variation in how referrals entered the CPS agencies. Overall, most agencies screened locally, received referrals from individuals, schools or hotlines, and used on-call staff to handle referrals after regular business hours. At the same time, the survey findings revealed that CPS agencies had some flexibility in processing referrals. Agencies utilized multiple response options for both screened-in and screened-out referrals. While most CPS agencies received referrals from their State hotline, they were not bound to the response recommendations or timeline of the hotline.
3.1 Receipt of Referrals
Individuals, State or local hotlines, and schools were the primary sources of referrals alleging maltreatment. Table 3-1 depicts the percentage of CPS agencies that ranked a list of possible referral sources as either the most common or the second most common. For 32 percent of agencies, individuals were the most common source of referrals. In almost as many agencies (28%), State or local hotlines and schools were the most common source of referrals. In one-third of agencies, schools were the second most common, and in one-fourth of agencies law enforcement was the second most common source of referrals.
| Source | Most common referral source | Second most common referral source |
|---|---|---|
| Individuals | 32% | 11% |
| State or local hotline | 28% | 4% |
| Schools | 28% | 33% |
| Law enforcement | 6% | 25% |
| Hospitals/healthcare professionals | 1% | 6% |
| State, regional, or district office | <1% | 1% |
| Other local agencies | <1% | 3% |
| Others | 1% | 3% |
| Missing | 3% | 14% |
| Total | 100% | 100% |
| Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||
Less than one-half of the agencies (38%) automatically accepted all referrals (Table 3-2). Among those that would accept all referrals, more than one-half accepted from specific agencies such as law enforcement, hospitals, or the courts and another one-third accepted referrals from mandated reporters.
| Acceptance | Estimate (C.I.)* |
Percent |
|---|---|---|
| Referrals from some reporters are automatically accepted | 990 (790-1,200) |
38% |
| Specific agencies | 540 (390-690) |
54% |
| Mandated reporters | 330 (200-450) |
33% |
| All accepted | 80 (20-150) |
8% |
| Central registry | 40 (20-70) |
5% |
| No referrals are automatically accepted | 1,520 (1,350-1,680) |
58% |
| Missing | 100 (50-150) |
4% |
| Total | 2,610 (2,410-2,810) |
100% |
| *The 95 percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval. | ||
Most CPS agencies assigned referrals received during nonbusiness hours — weekday evenings or weekends — to on-call staff. As Table 3-3 illustrates, for some agencies, State hotlines were used to accept these after-hours referrals.
| Weekday evenings | Estimate (C.I.) |
Percent |
|---|---|---|
| Handled by intake unit | 120 (50-190) |
5% |
| Assigned to on-call staff | 1,360 (1,200-1,530) |
52% |
| Routed to another agency | 120 (50-190) |
5% |
| Handled by State hotline | 450 (330-580) |
17% |
| Other method | 160 (80-230) |
6% |
| Missing | 390 (240-540) |
15% |
| Total | 2,610 (2,410-2,810) |
100% |
| Weekends | Estimate (C.I.) |
Percent |
| Handled by intake unit | 50 (0-90) |
2% |
| Assigned to on-call staff | 1,430 (1,270-1,590) |
55% |
| Routed to another agency | 130 (60-200) |
5% |
| Handled by State hotline | 430 (300-550) |
16% |
| Other method | 200 (120-280) |
8% |
| Missing | 370 (230-530) |
14% |
| Total | 2,610 (2,410-2,810) |
100% |
Few agencies had staff that could respond to calls received from non-English speakers (Table 3-4). Few agencies had non-English speakers on staff (13%) or on call (9%). Most agencies, if they had means of accepting such referrals, used other methods, such as contracting with interpreters from the community or another agency or accessing a "language line" by which a third party joins the conversation as the interpreter. Surprisingly, 15 percent of all CPS agencies were not able to accept calls from non-English speakers because of a lack of appropriate staff to handle such calls.
| Referrals from non- English speakers | Estimate (C.I.) |
Percent |
|---|---|---|
| Use non-English speakers on staff | 330 (230-430) |
13% |
| Use non-English speakers on call | 240 (150-340) |
9% |
| Other method | 1,200 (1,000-1,410) |
46% |
| Multiple methods | 440 (320-550) |
17% |
| Not able to accept | 390 (260-520) |
15% |
| Total | 2,610 (2,410-2,810) |
100% |
The majority of CPS agencies (81%) handled written referrals in the same manner as other types of referrals (Table 3-5). A few agencies handled these with priority status (8%) while the rest were handled by the person or unit receiving the written referral (2%) or in some other way (5%).
| Written referral procedure | Estimate (C.I.) |
Percent |
|---|---|---|
| Handled the same as other referrals | 2,110 (1,910-2,310) |
81% |
| Handled with priority status | 210 (110-320) |
8% |
| Handled by person or unit that received referral | 40 (0-90) |
2% |
| Handled in some other way | 130 (70-200) |
5% |
| Missing | 110 (30-180) |
4% |
| Total | 2,610 (2,410-2,810) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. | ||
3.2 Processing Referrals
he screening and intake module examined how CPS agency processed referrals, the available response options, and the activities that were performed during screening and intake. The majority of agencies (83%) conducted their own screening activities (Table 3-6). For 14 percent of agencies, the State hotline performed screening.
| Agency | Estimate (C.I.) |
Percent |
|---|---|---|
| Local agency screens | 2,170 (1,980-2,360) |
83% |
| State hotline screens | 370 (250-490) |
14% |
| Missing | 70 (20-120) |
3% |
| Total | 2,610 (2,410-2,810) |
100% |
CPS agencies had a variety of response options for both screened-out and screened-in referrals. Screened-out referrals could be either referred to another agency — such as law enforcement (84%) or a community-based agency (75%) — or closed without further action (72%), (Table 3-7).
| Referral options | Estimate (C.I.) |
Percent |
|---|---|---|
| Refer to police or sheriff's office | 2,180 (2,010-2,350) |
84% |
| Refer to local community-based agency | 1,950 (1,780-2,130) |
75% |
| Call recorded but no further action | 1,880 (1,700-2,060) |
72% |
| Other response | 510 (370-640) |
19% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Percentages are based on weighted total of 2,610 agencies. |
||
Once a referral was screened in, the majority of CPS agencies referred to the CPS investigation response for new referrals, for referrals concerning children who already had an open investigation, for children who had been previously referred, and for children in foster care (Table 3-8). In nearly one-half (44%) of agencies, multiple response options were available when the referral concerned a child or household with an open investigation, while in approximately one-fourth of the agencies there were multiple response options for new referrals and children who had been previously referred. This indicates that there may be considerable flexibility even within the same agency in how referrals were handled.
| Types of Screened- In Referrals | Referral to another agency | CPS investigation response | Alternative response | Various options available | Missing | Total |
|---|---|---|---|---|---|---|
| New referral | <1% | 74% | 1% | 23% | 1% | 100% |
| Open investigation | 1% | 50% | 3% | 44% | 1% | 100% |
| Prior substantiated | <1% | 72% | 3% | 24% | 1% | 100% |
| Prior unsubstantiated | <1% | 69% | 4% | 25% | 1% | 100% |
| Foster or substitute care | 4% | 50% | 2% | 42% | 1% | 100% |
| Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
More than three-quarters of agencies (86%) always searched for previous CPS records for the children who were alleged to be victims of maltreatment previously; 81 percent of agencies always searched for information on the alleged perpetrator (Table 3-9). While these activities are supposed to be uniformly carried out by all CPS agencies, the survey responses indicate that not all agencies follow this practice. Safety assessment tools were always used by more than two-thirds of agencies (69%). Screening and intake staff at one-third to one-half of CPS agencies sometimes searched other records, called collateral contacts, called family members, and established the credibility of the reporter. It is interesting to note that 37 percent of CPS agencies always visited the family during the screening process while 31 percent never visited the family.
| Activity | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Search CPS records for child(ren) | 86% | 7% | 1% | 1% | 6% | 100% |
| Search CPS records for alleged perpetrator | 81% | 11% | 2% | 1% | 6% | 100% |
| Search CPS records for reporter | 12% | 20% | 38% | 24% | 6% | 100% |
| Search other records | 38% | 43% | 8% | 5% | 6% | 100% |
| Use a safety assessment tool | 69% | 5% | 5% | 14% | 7% | 100% |
| Call collaterals | 19% | 60% | 8% | 7% | 6% | 100% |
| Call family members | 11% | 51% | 19% | 13% | 7% | 100% |
| Visit family | 37% | 6% | 19% | 31% | 7% | 100% |
| Establish credibility of reporter | 15% | 37% | 25% | 18% | 6% | 100% |
| Other | 3% | 2% | --- | 1% | 94% | 100% |
| Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
3.3 Role of State Hotline
Another area of interest is the role of the State hotline in the screening function. More than one-half of local CPS agencies received referrals from a State hotline (Table 3-10). For these agencies, caseworkers and supervisors usually managed referrals from the hotlines. One-quarter of the agencies that received State hotline referrals indicated that someone received them other than a caseworker or supervisor. Other persons who might handle referrals included secretaries, clerks, directors, or administrators.
| Recipient | Estimate (C.I.) |
Percent |
|---|---|---|
| Yes | 1,550 (1,300-1,790) |
59% |
| Caseworkers* | 1,010 (790-1,220) |
65% |
| Supervisors* | 1,150 (950-1,340) |
74% |
| Someone else* | 380 (250-520) |
25% |
| No | 1,020 (840-1,190) |
39% |
| Missing | 40 (10-80) |
2% |
| Total | 2,610 (2,410-2,810) |
100% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||
CPS agencies were evenly divided as to whether the State hotline made recommendations as to what the response of the agency should be. Most local agencies had autonomy in regards to action since 74 percent of agencies that received recommendations did not have to follow them and one-half of all agencies did not receive recommendations from the State hotline (Table 3-11). However, most were required to respond within timeframes established by the State hotline (Table 3-12).
| Response | Estimate (C.I.) |
Percent |
|---|---|---|
| Hotline makes recommendations | 740 (510-960) |
48% |
| Agency is not bound* | 540 (370-710) |
74% |
| Agency is bound* | 190 (100-290) |
26% |
| Hotline does not make recommendations | 790 (620-950) |
51% |
| Missing | 20 (0-50) |
1% |
| Total | 1,550 (1,300-1,790) |
100% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||
| Authority to determine response priority | Estimate (C.I.) |
Percent |
|---|---|---|
| Yes | 300 (170-430) |
40% |
| No | 440 (290-590) |
60% |
| Total | 740 (510-960) |
100% |
3.4 Conclusion
The findings indicate that many of the local CPS agencies shared some core practices when conducting the screening and intake functions. Also indicated is that CPS agencies had some flexibility in how they handled referrals.
Core practices shared by many of the local CPS agencies in conducting the screening and intake functions included the types of referral sources and the acceptance of referrals. Further, activities undertaken during the screening process were often similar among CPS agencies.
While CPS agencies received referrals from many sources, the most common sources were individuals, State or local hotlines, and schools. The second-most common source of referrals to CPS agencies was law enforcement. Responses to referrals made during weekend or evening hours were often conducted by on-call staff; however, agencies were more limited in accepting referrals from non-English speakers. A substantial minority of CPS agencies automatically accepted referrals from certain sources such as specific agencies or mandated reporters.
CPS agencies undertook a wide variety of activities during the screening process. Typical activities performed by the agencies often involved paperwork, such as searching CPS records for information on the alleged victims and perpetrators. Less frequently conducted activities were those that required direct contact with the child, family, or reporter.
While many CPS agencies shared several core functions in the screening and intake of referrals, they also had some flexibility in how they handled these referrals. This level of flexibility was evident in the use of multiple responses for both screened-out and screened-in referrals as well as collaboration with State hotlines to respond to the referrals.
A large majority of CPS agencies used multiple response options for screened-out referrals, including making referrals to other agencies. For all types of screened-in referrals, the most common response option was a CPS investigation; however, approximately one-quarter to one-half of agencies had multiple response options for screened-in referrals.
While approximately two-thirds of local CPS agencies received State hotline referrals, they retained some flexibility in handling these referrals. Close to one-half of CPS agencies indicated that their State hotline made recommendations as to their agency's response. However, most agencies were not bound to follow these recommendations, and many assigned their own priority status to the recommendation.
Endnote
1. Calls that are received by the CPS agency are considered to be referrals to the agency, which may be screened -in or screened- out by the agency. Screened-in referrals are considered reports alleging child abuse or neglect.
Chapter 4. Investigation and Alternative Response Practices
This chapter examines local agency practices and procedures in conducting investigations and alternative CPS responses. For the purposes of this study, the investigation response was defined as the process for determining whether child maltreatment has occurred or the child is at risk of maltreatment. An alternative response was defined as a response in which the agency assessed the needs of the child or family without requiring a determination that maltreatment had occurred or that the child was at risk of maltreatment.
The findings reported in this chapter examine the types of CPS agency responses, the features and activities of these responses, the role of workers and supervisors in the conduct of these responses, and difficulties encountered in carrying out the responses. Estimates of agencies with investigation response include those agencies that conducted investigations regardless of whether they had another response. Estimates of agencies with alternative response are based only on those agencies that conducted such responses.
Overall, the findings reveal that two-thirds of CPS agencies had an alternative response option available in addition to the investigation response. Further, CPS agencies often used similar approaches and practices and encountered similar obstacles in carrying out the response.
4.1 Types of Responses
Nearly two-thirds of local CPS agencies (64%) conducted both investigations and alternative responses (Table 4-1). Nearly all of the remaining agencies only conducted investigations in response to maltreatment referrals.
| Response | Estimate (C.I.)* |
Percent |
|---|---|---|
| Both investigation and alternative response | 1,660 (1,460-1,860) |
64% |
| Investigation response only | 940 (760-1,110) |
36% |
| Neither response | 10 (0-30) |
<1% |
| Total | 2,610 (2,410-2,810) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. *The 95 percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval. |
||
In comparing investigation and alternative response options, important differences in the standard practices for each type of response were found (Tables 4-2 and 4-3).
- Eighty-five percent of agency procedures for conducting investigations required the removal of a child if immediate safety was an issue, while only 50 percent of agencies made such removals under their alternative response.
- Seventy-one percent of agencies made an assessment of the immediate safety needs of the family under investigation, while 53 percent of agencies made a similar assessment under alternative response.
- Under the investigation response, 67 percent of agencies required a determination of whether or not the child had been maltreated, while 42 percent of agencies required a determination of maltreatment under the alternative response option.1
- Sixty-three percent of agencies required that a determination of risk of maltreatment be made under the investigation response, compared to 40 percent of agencies under alternative response.
- Sixty-one percent of agencies required that a recommendation for court intervention be made, if needed, under investigation, while 30 percent of agencies made a similar requirement under alternative response.
| Practice | Required before response complete | Required after response complete | May provide before response complete | May provide after response complete | Not provided | Missing | Total |
|---|---|---|---|---|---|---|---|
| Make a determination of whether the child has been maltreated | 67% | 29% | <1% | 1% | --- | 2% | 100% |
| Make a determination on all children in the family as to whether they have been maltreated | 58% | 21% | 9% | 9% | 1% | 2% | 100% |
| Make a determination of whether one or more children are at risk of maltreatment | 63% | 21% | 6% | 4% | 1% | 4% | 100% |
| Remove the child if immediate safety is an issue | 85% | 4% | 3% | <1% | 4% | 4% | 100% |
| Make an assessment of the service needs of the child | 59% | 22% | 8% | 5% | --- | 5% | 100% |
| Make an assessment of the immediate service needs of the family | 71% | 11% | 9% | 3% | --- | 6% | 100% |
| Assess the underlying causes of the maltreatment incident | 49% | 14% | 15% | 12% | 3% | 7% | 100% |
| Provide short-term services if needed | 42% | 13% | 23% | 13% | 1% | 7% | 100% |
| Refer the family for further services if needed | 41% | 22% | 17% | 13% | --- | 8% | 100% |
| To make a recommendation for court intervention if needed | 61% | 16% | 10% | 6% | <1% | 8% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
|||||||
| Practice | Required before response complete | Required after response complete | May provide before response complete | May provide after response complete | Not provided | Missing | Total |
|---|---|---|---|---|---|---|---|
| Make a determination of whether the child has been maltreated | 42% | 12% | 6% | 3% | 31% | 6% | 100% |
| Make a determination on all children in the family as to whether they have been maltreated | 33% | 10% | 10% | 7% | 33% | 6% | 100% |
| Make a determination of whether one or more children are at risk of maltreatment | 40% | 13% | 13% | 4% | 21% | 9% | 100% |
| Remove the child if immediate safety is an issue | 50% | 6% | 7% | 2% | 29% | 7% | 100% |
| Make an assessment of the service needs of the child | 41% | 20% | 12% | 5% | 9% | 13% | 100% |
| Make an assessment of the immediate service needs of the family | 53% | 8% | 13% | 7% | 7% | 11% | 100% |
| Assess the underlying causes of the maltreatment incident | 32% | 14% | 12% | 12% | 21% | 9% | 100% |
| Provide short-term services if needed | 27% | 14% | 18% | 13% | 11% | 16% | 100% |
| Refer the family for further services if needed | 28% | 16% | 17% | 19% | 6% | 14% | 100% |
| To make a recommendation for court intervention if needed | 30% | 16% | 12% | 12% | 18% | 12% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
|||||||
4.2 Practices and Procedures
While CPS agencies used a variety of practices and procedures in conducting investigations and alternative responses, the analyses revealed many areas where the two responses were similar. In terms of the scope of the responses, the components of the responses are similar but differ among some elements. Also, some components of policy and procedure apply to investigations only or only to alternative response. This section presents data on practices and procedures for both functions so that appropriate comparisons can be drawn.
More than one-half of the agencies (55%) always extended investigations to all children in the household; an additional 31 percent of agencies included all the household children in the investigation on a case-by-case basis (Table 4-4). The estimates and percentages for the alternative response are not provided because these data were missing for a large portion of agencies. Slightly more than one-half (51%) of the agencies made a separate determination of maltreatment for each child under investigation (Table 4-5).
| Scope | Investigation | |
|---|---|---|
| Estimate (C.I.) |
Percent | |
| Only children specified in referral | 110 (50-160) |
4% |
| Extend to all children in household, case-by-case | 820 (640-990) |
31% |
| Extend to all children in household in all cases | 1,440 (1,200-1,690) |
55% |
| Missing | 240 (160-320) |
9% |
| Total | 2,610 (2,410-2,810) |
100% |
| Children | Investigation | |
|---|---|---|
| Estimate (C.I.) |
Percent | |
| Only children specified in referral | 180 (100-260) |
7% |
| Separate determination for each child in household | 1,320 (1,160-1,480) |
51% |
| Inclusion decided on case-by-case basis | 1,000 (810-1,190) |
38% |
| Missing | 100 (20-170) |
4% |
| Total | 2,610 (2,410-2,810) |
100% |
Most agencies always considered the severity of the case (94%) and policy-defined standards of evidence (90%) when making a determination at the conclusion of the investigation (Table 4-6). Approximately one-half of agencies always considered the family's need for services (57%) and the parents' willingness to cooperate (43%). The availability of services was always considered by 28 percent of agencies.
| Factors | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Severity of case | 94% | 3% | --- | 2% | 1% | 100% |
| Policy-defined standards of evidence | 90% | 6% | 2% | 1% | 2% | 100% |
| Family's need for services | 57% | 27% | 7% | 8% | 1% | 100% |
| Willingness of parent to cooperate | 43% | 26% | 12% | 18% | 1% | 100% |
| Availability of services | 28% | 22% | 15% | 33% | 2% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
Concluding a response varied between investigation responses and alternative responses (Tables 4-7 and 4-8). During the investigation, almost all agencies always notified perpetrators (85%) and entered the perpetrator's name into the Central Registry (80%). In contrast, under the alternative response, fewer than one-half of the agencies always notified perpetrators (45%) and entered the perpetrator's name into the Central Registry (41%).
| Procedures | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Notify perpetrator | 85% | 9% | 2% | 3% | 1% | 100% |
| Enter perpetrator in Central Registry | 80% | 12% | 1% | 5% | 1% | 100% |
| Notify reporter | 30% | 49% | 11% | 10% | 1% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
| Procedures | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Notify perpetrator | 45% | 3% | 2% | 4% | 46% | 100% |
| Enter perpetrator in Central Registry | 41% | 5% | 1% | 8% | 46% | 100% |
| Notify reporter | 21% | 21% | 8% | 5% | 46% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||||
In general, CPS agencies establish timeframes for completing an investigation or an alternative response (Table 4-9). The majority of agencies (81%) will close the case, once the timeframe for an alternative response has elapsed. However, the majority of agencies (84%) will not close an investigation even if the timeframe has been exceeded.
| Procedures | Investigation | Alternative response | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Closed without a finding | 50 (0-100) |
2% | 50 (0-90) |
3% |
| Closed without finding of "undetermined" or "unsubstantiated" | 120 (60-190) |
5% | 1,350 (1,160-1,540) |
81% |
| Remains open with original worker until complete | 2,180 (1,960-2,400) |
84% | 70 (10-130) |
4% |
| Remains open, transferred to another worker until complete | 20 (0-60) |
1% | --- | --- |
| Missing | 230 (120-340) |
9% | 200 (80-320) |
12% |
| Total | 2,610 (2,410-2,810) |
100% | 1,660 (1,460-1,860) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. | ||||
The survey revealed that there was a great deal of similarity in the actual activities conducted under investigation and alternative response (Tables 4-10 and 4-11).
When conducting investigations, nearly all agencies always reviewed prior CPS records (89%), interviewed or formally observed the child(ren) (98%), and interviewed the caregiver(s) (98%). Percentages were similarly high for agencies providing an alternative response — 80 percent always reviewed prior CPS records; 69 percent interviewed or formally observed the child(ren); and 73 percent always interviewed the caregiver(s).
Furthermore, during the investigation a majority of the agencies sometimes discussed the case with other CPS workers (73%), discussed the case with a multidisciplinary team (67%), visited the family with an appointment (61%), visited the family without an appointment (65%), conducted a family group conference meeting (57%), interviewed professionals known to the family (58%), and conducted criminal background checks on the alleged perpetrator (50%). Results were similar for alternative response procedures. A majority of agencies discussed the case with other CPS workers (75%), discussed the case with a multidisciplinary team (57%), visited the family with an appointment (63%) or without an appointment (66%), conducted family group conference meetings (55%), interviewed family members other than the caregiver (62%), and interviewed professionals known to the family (65%).
Not surprisingly, given that maltreatment is infrequently involved in cases receiving the alternative response, approximately one-fourth of the agencies never obtained or preserved physical evidence (24%), removed the child from harm (23%), or conducted criminal background checks on the alleged perpetrator (24%) during this response.
| Activity | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Review prior CPS records | 89% | 9% | <1% | --- | 1% | 100% |
| Discuss with other CPS workers | 24% | 73% | 2% | --- | 1% | 100% |
| Discuss with multidisciplinary team | 10% | 67% | 16% | 6% | <1% | 100% |
| Visit family with appointment | 6% | 61% | 28% | 4% | 1% | 100% |
| Visit family without appointment | 34% | 65% | <1% | --- | <1% | 100% |
| Conduct family group conference meeting | 6% | 57% | 29% | 7% | <1% | 100% |
| Interview or formally observe child(ren) | 98% | 1% | --- | --- | 1% | 100% |
| Interview caregiver(s) | 98% | 1% | --- | --- | 1% | 100% |
| Interview family members other than caregiver | 56% | 42% | 1% | --- | 1% | 100% |
| Interview reporter | 43% | 48% | 7% | 1% | 1% | 100% |
| Interview witnesses | 65% | 32% | 1% | --- | 2% | 100% |
| Interview professionals known to family | 41% | 58% | 1% | --- | 1% | 100% |
| Obtain/preserve physical evidence | 50% | 45% | 3% | 1% | 1% | 100% |
| Remove child harmed or in danger of harm | 53% | 39% | 1% | 6% | 1% | 100% |
| Conduct criminal background check on alleged perpetrator | 32% | 50% | 10% | 7% | 2% | 100% |
| 1st Other | 3% | 2% | --- | --- | 95% | 100% |
| 2nd Other | 1% | 1% | --- | --- | 98% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
Local CPS agencies had few differences between the investigation and alternative response in terms of the instruments and tools used (Tables 4-12 and 4-13). Nearly three-quarters of the agencies (74%) used guidelines for establishing risk or safety during an investigation compared to 62 percent of the agencies using an alternative response option. Only a minority of agencies used formal assessment tools during the investigation or alternative response to gauge the extent of risk, safety, substance abuse, or domestic violence.
| Activity | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Review prior CPS records | 80% | 17% | 1% | 2% | 1% | 100% |
| Discuss with other CPS workers | 19% | 75% | 5% | --- | 1% | 100% |
| Discuss with multidisciplinary team | 6% | 57% | 24% | 11% | 1% | 100% |
| Visit family with appointment | 15% | 63% | 13% | 7% | 2% | 100% |
| Visit family without appointment | 18% | 66% | 11% | 4% | 1% | 100% |
| Conduct family group conference meeting | 6% | 55% | 28% | 9% | 2% | 100% |
| Interview or formally observe child(ren) | 69% | 23% | 3% | 3% | 2% | 100% |
| Interview caregiver(s) | 73% | 23% | 1% | 2% | 1% | 100% |
| Interview family members other than caregiver | 25% | 62% | 8% | 4% | 2% | 100% |
| Interview reporter | 30% | 35% | 17% | 13% | 4% | 100% |
| Interview witnesses | 30% | 42% | 10% | 16% | 2% | 100% |
| Interview professionals known to family | 25% | 65% | 5% | 2% | 3% | 100% |
| Obtain/preserve physical evidence | 27% | 36% | 11% | 24% | 2% | 100% |
| Remove child harmed or in danger of harm | 46% | 23% | 4% | 23% | 3% | 100% |
| Conduct criminal background check on alleged perpetrator | 23% | 34% | 16% | 24% | 4% | 100% |
| 1st Other | 1% | --- | --- | 1% | 98% | 100% |
| 2nd Other | --- | --- | --- | 1% | 99% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||||
There was a great deal of similarity between the professional resources available to agencies during the investigation and alternative response (Tables 4-14 and 4-15).
Under investigation, nearly all agencies always had clinicians or psychiatrists (90%), domestic violence specialists (80%), substance abuse specialists (92%), and child fatality review teams (80%) available to assist. Similarly high percentages of agencies claimed such professionals were always available during the alternative responses.
In addition, under investigation, most agencies always had forensic specialists (62%), child advocacy centers (58%), or hospital-based sexual abuse trauma centers (58%) available to assist. Again, these professional resources were also widely available to agencies during alternative responses.
| Instruments and tools | Yes |
|---|---|
| Structured decisionmaking model | 47% |
| Formal safety assessment instrument | 37% |
| Formal risk assessment instrument | 44% |
| Guidelines for establishing risk or safety | 74% |
| Standardized substance abuse assessment instrument | 13% |
| Standardized domestic violence assessment instrument | 11% |
| Standardized parenting skills assessment | 10% |
| Standardized child development inventory | 11% |
| Standardized family support assessment | 15% |
| Instruments and tools | Yes |
|---|---|
| Structured decisionmaking model | 27% |
| Formal safety assessment instrument | 26% |
| Formal risk assessment instrument | 30% |
| Guideline for establishing risk or safety | 62% |
| Standardized substance abuse assessment instrument | 12% |
| Standardized domestic violence assessment instrument | 11% |
| Standardized parenting skills assessment | 6% |
| Standardized child development inventory | 9% |
| Standardized family support assessment | 14% |
| Resources | Always | Sometimes | Missing | Total |
|---|---|---|---|---|
| Clinicians or psychiatrists | 90% | 8% | 2% | 100% |
| Domestic violence specialists | 80% | 18% | 2% | 100% |
| Substance abuse specialists | 92% | 7% | 1% | 100% |
| Forensic specialists | 62% | 35% | 4% | 100% |
| Child advocacy centers | 58% | 39% | 3% | 100% |
| Hospital-based sexual abuse trauma centers | 58% | 39% | 3% | 100% |
| Child fatality review team | 80% | 16% | 4% | 100% |
| Citizen CPS review team | 35% | 60% | 4% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||
| Resources | Always | Sometimes | Missing | Total |
|---|---|---|---|---|
| Clinicians or psychiatrists | 88% | 7% | 5% | 100% |
| Domestic violence specialists | 80% | 16% | 5% | 100% |
| Substance abuse specialists | 91% | 6% | 3% | 100% |
| Forensic specialists | 57% | 36% | 7% | 100% |
| Child advocacy centers | 53% | 43% | 4% | 100% |
| Hospital-based sexual abuse trauma centers | 55% | 39% | 6% | 100% |
| Child fatality review team | 74% | 19% | 7% | 100% |
| Citizen CPS review team | 41% | 53% | 6% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||
4.3 Worker and Supervisor Roles
The survey also gathered information about the roles of workers and supervisors in the decisionmaking process. Specifically, agencies were asked about the workers and supervisors who are assigned to conduct the response and make a final determination as to maltreatment or services.
The majority of local CPS agencies (79%) assigned investigations involving a child or household currently under investigation to a caseworker with experience with the family (Table 4-16). Agencies most often assigned referrals involving a child with prior substantiated reports and those involving prior unsubstantiated reports to the next available worker (71% and 76%, respectively). Agencies were split regarding who would be assigned to a case when the child or household was currently receiving home or foster care services — some agencies preferred to assign a caseworker with experience in working with the family and others preferred to assign the next available caseworker.
For both responses, agencies were consistent in describing who makes the final determination about maltreatment during the response. Under both investigation and alternative response, decisions were made by workers with supervisory review (Tables 4-17 and 4-18).
| Referral type | Worker experienced with family | Next available worker | Other worker providing services | Worker from other agency | Missing | Total |
|---|---|---|---|---|---|---|
| Child or household currently investigated | 79% | 18% | --- | --- | 3% | 100% |
| Child or household currently receiving in-home services | 43% | 39% | 14% | --- | 4% | 100% |
| Child or household currently receiving foster care services | 32% | 39% | 10% | --- | 19% | 100% |
| Child or household not currently served, but one or more prior substantiated reports | 27% | 71% | <1% | --- | 2% | 100% |
| Child or household not currently served, but all prior reports unsubstantiated | 21% | 76% | 1% | --- | 2% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
| Worker/supervisor | Estimate (C.I.) |
Percent |
|---|---|---|
| Worker alone | 40 (0-80) |
1% |
| Worker with supervisory review | 2,260 (2,060-2,470) |
87% |
| Supervisor alone | 30 (0-70) |
1% |
| Not applicable | 230 (140-320) |
9% |
| Missing | 50 (10-90) |
2% |
| Total | 2,610 (2,410-2,810) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. | ||
| Worker/supervisor | Estimate (C.I.) |
Percent |
|---|---|---|
| Worker alone | 20 (0-30) |
1% |
| Worker with supervisory review | 1,550 (1,340-1,750) |
93% |
| Supervisor alone | 10 (0-30) |
1% |
| Not applicable | 60 (10-100) |
3% |
| Missing | 30 (0-60) |
2% |
| Total | 1,660 (1,460-1,860) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. | ||
4.4 Difficulties in Conducting the Response
Under the investigation approach, agencies experienced somewhat more barriers than under the alternative response approach (Tables 4-19 and 4-20). The findings are summarized below:
During investigation, few agencies always experienced obstacles because of difficulties in predicting what might happen to the child (11%), in having sufficient time to make a good determination (12%), in preparing materials for the case record (17%), or in preparing materials for the court record (10%). Similarly low percentages of agencies with an alternative response reported these obstacles.
For the investigation response, a majority of agencies sometimes experienced difficulties in locating the family (67%), in spending sufficient time with the family (55%), in assessing parenting skills (55%), in determining what happened to the child (61%), in predicting what might happen to the child (55%), in having sufficient time to make a good determination (55%), or in obtaining the necessary expertise from other professionals (68%). Nearly identical percentages of agencies experienced these problems with alternative responses.
During both responses, the majority of agencies claimed that they rarely or never experienced difficulties in explaining the consequences of actions to parent(s) (61-66%), in deciding whether to remove a child (67-71%), in deciding whether to return a child (63-64%), or in handling language barriers (60-69%).
| Activities | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Locating the family | <1% | 67% | 32% | 1% | <1% | 100% |
| Spending sufficient time with the family | 9% | 55% | 31% | 4% | 1% | 100% |
| Assessing parenting skills | 2% | 55% | 39% | 4% | 1% | 100% |
| Determining what happened to child | 2% | 61% | 33% | 3% | 2% | 100% |
| Predicting what might happen to child | 11% | 55% | 30% | 4% | 1% | 100% |
| Having sufficient time to make a good determination | 12% | 55% | 28% | 5% | 1% | 100% |
| Explaining the consequences of actions to parent(s) | 3% | 30% | 55% | 11% | 1% | 100% |
| Obtaining necessary expertise from other professionals | 4% | 68% | 25% | 2% | <1% | 100% |
| Deciding whether to remove child prior to completing response | 1% | 32% | 48% | 19% | 1% | 100% |
| Deciding whether to return child upon completing response | 1% | 33% | 50% | 14% | 1% | 100% |
| Preparing materials for case record | 17% | 46% | 29% | 8% | 1% | 100% |
| Preparing materials for court record | 10% | 43% | 36% | 10% | 1% | 100% |
| Handling language barriers | 2% | 28% | 57% | 12% | 1% | 100% |
| 1st Other | 1% | 4% | 1% | --- | 94% | 100% |
| 2nd Other | 1% | 1% | --- | --- | 98% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
Strategies for ensuring that workers were safe were comparable for both responses. As shown in Table 4-21, the majority of agencies provided police escort for workers, enabled for accompaniment by another worker, supported periodic telephone check-in procedures, and restricted visits to normal business hours.
| Activities | Always | Sometimes | Rarely | Never | Missing | Total |
|---|---|---|---|---|---|---|
| Locating the family | 1% | 58% | 33% | 7% | 1% | 100% |
| Spending sufficient time with the family | 4% | 56% | 27% | 10% | 2% | 100% |
| Assessing parenting skills | 2% | 46% | 41% | 9% | 2% | 100% |
| Determining what happened to child | 4% | 46% | 35% | 12% | 3% | 100% |
| Predicting what might happen to child | 8% | 54% | 28% | 7% | 3% | 100% |
| Having sufficient time to make a good determination | 5% | 50% | 30% | 12% | 3% | 100% |
| Explaining the consequences of actions to parent(s) | 6% | 28% | 48% | 13% | 5% | 100% |
| Obtaining necessary expertise from other professionals | 4% | 50% | 39% | 5% | 1% | 100% |
| Deciding whether to remove child prior to completing response | 2% | 24% | 41% | 30% | 4% | 100% |
| Deciding whether to return child upon completing response | 1% | 30% | 39% | 24% | 6% | 100% |
| Preparing materials for case record | 9% | 46% | 30% | 14% | 2% | 100% |
| Preparing materials for court record | 7% | 37% | 37% | 18% | 2% | 100% |
| Handling language barriers | 4% | 33% | 47% | 13% | 2% | 100% |
| 1st Other | 1% | 2% | 1% | 1% | 96% | 100% |
| 2nd Other | 1% | --- | --- | 1% | 99% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||||
| Procedures | Investigation | Alternative response | ||||||
|---|---|---|---|---|---|---|---|---|
| Yes | No | Missing | Total | Yes | No | Missing | Total | |
| Formal assessment of risk to worker | 21% | 78% | 1% | 100% | 27% | 71% | 2% | 100% |
| Police escort | 86% | 12% | 2% | 100% | 71% | 28% | 2% | 100% |
| Another worker accompanies | 76% | 23% | 1% | 100% | 70% | 28% | 2% | 100% |
| Cell phones provided | 80% | 18% | 2% | 100% | 80% | 19% | 2% | 100% |
| Change to use pay phone | 26% | 66% | 8% | 100% | 24% | 70% | 6% | 100% |
| Periodic telephone check-in | 72% | 27% | 1% | 100% | 66% | 32% | 2% | 100% |
| Assistance from community resident | 1% | 98% | 1% | 100% | 2% | 95% | 3% | 100% |
| Self-defense training | 13% | 86% | 1% | 100% | 16% | 82% | 2% | 100% |
| Visits restricted to normal business hours | 68% | 30% | 2% | 100% | 66% | 31% | 2% | 100% |
| Appointments logged in master schedule | 40% | 59% | 1% | 100% | 39% | 59% | 2% | 100% |
| 1st Other | 15% | 1% | 84% | 100% | 8% | 1% | 92% | 100% |
| 2nd Other | 6% | <1% | 94% | 100% | 1% | --- | 99% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies (1,660 agencies for other CPS response columns). |
||||||||
4.5 Conclusion
The findings show that the majority of agencies nationwide handled referrals through both investigations and alternative responses. However, the circumstances under which the responses were used differed widely. Alternative responses were less likely than the investigation response to be used for removing a child, assessing the safety needs of the family, making a determination of maltreatment or risk of maltreatment, or making a recommendation for court action.
Despite differences in the types of referrals handled under the two responses, the survey found many similarities in the approaches and practices used to conduct the responses. The majority of agencies extended both the investigation response and the alternative response when it was available to all children in the household. In making determinations at the conclusion of the investigation response, most agencies made separate determinations for each child. Moreover, most agencies considered such factors as the severity of the case, policy-defined standards of evidence, and the family's need for services when making determinations during the investigation.
Agencies provided a lot of information about the activities carried out while conducting these responses. The vast majority always reviewed prior CPS records, interviewed or formally observed the child, and interviewed the caregiver as part of the investigation. These same activities were consistently performed during the alternative response. Nearly three-quarters of agencies used guidelines for establishing risk or safety during investigations, while nearly as many used this tool during alternative responses. Further, professionals and assistance groups were widely available during both responses. In particular, clinicians or psychiatrists, domestic violence specialists, substance abuse specialists, and child fatality review teams were nearly always available to workers conducting investigations and alternative responses.
Workers and supervisors had similar roles in conducting the responses. For the investigation response, agencies normally assigned a referral on a child or household currently under investigation to a worker experienced with the family. For referrals with prior substantiated or unsubstantiated reports, agencies typically assigned the next available worker to investigate. In almost all agencies, investigation workers made the formal maltreatment determination with supervisory review. This same decision structure held for service determinations during the alternative responses whereby the workers made the determination with supervisory review.
The investigation response and the alternative response also faced similar challenges. The most common obstacles to timely completion of either response included locating the family, spending sufficient time with the family, and obtaining the necessary expertise from other professionals.
More notable differences between the two responses emerged in a few areas. Agencies routinely notified perpetrators and entered their names in the central registry at the conclusion of investigations, while this was somewhat less common for alternative responses. When the response was not completed within the required timeframe, procedures differed depending on the response. For investigations, the case remained open with the original worker until complete. In contrast, for the alternative CPS response, the agency closed the referral when the time frame expired.
Endnote
1 Although the definition of alternative response specified that a maltreatment determination was not required, there are considerable differences in the types of cases that are handled, and a determination was included by almost one-half of the agencies with an alternative response.
Chapter 5. Collaboration with Other Agencies
This chapter examines the role of law enforcement and other agencies in CPS work. The analyses show the degree to which law enforcement and other agencies perform different CPS functions and how their involvement varies with type of maltreatment and type of perpetrator.
The analyses demonstrated that few CPS agencies had lead responsibility across all types of maltreatment for the investigation and alternative response functions. Other agencies, most notably law enforcement, have important roles in working with CPS agencies on the different functions. The specific circumstances of the maltreatment allegations and the type of perpetrator shaped the degree to which CPS agencies shared responsibility with other agencies. For the screening and investigation functions, it was fairly common for CPS agencies to share lead responsibility for the more serious types of maltreatment, especially with law enforcement agencies.
5.1 Responsibility for CPS functions
The survey asked CPS agencies to indicate their role and degree of responsibility in connection with each of the primary CPS functions — screening, investigation, and alternative response. Specifically, for each of several forms of maltreatment, agencies were asked to indicate whether they were the lead agency with sole responsibility, were the lead agency sharing responsibility with another agency, supported another agency/agencies, or had no responsibility.
More CPS agencies had lead responsibility across all types of maltreatment for the screening function than for the investigation or alternative response functions (Table 5-1). While 50 percent of CPS agencies had lead responsibility for the screening function, just 17 percent of CPS agencies had lead responsibility for investigations across all types of maltreatment. Similarly, only 9 percent of CPS agencies had lead responsibility for the alternative response function across all types of maltreatment. For the investigation and alternative response functions, the majority of agencies had a range of responsibilities (e.g., lead some, support some, and share some) depending on the specific type of maltreatment.
| Responsibility | Screening | Investigation | Alternative Response | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) * |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Lead for all types of maltreatment | 1,290 (1,120-1,470) |
50% | 450 (330-570) |
17% | 140 (80-200) |
9% |
| Share for all types of maltreatment | 350 (230-470) |
13% | 220 (140-300) |
8% | 60 (10-120) |
4% |
| Support for all types of maltreatment | 50 (10-100) |
2% | 20 (0-40) |
1% | 10 (0-20) |
<1% |
| No responsibility | 40 (0-80) |
1% | --- | --- | 610 (450-770) |
37% |
| Other (lead some, support some, share some) | 800 (630-960) |
31% | 1,910 (1,690-2,130) |
73% | 830 (690-970) |
50% |
| Missing | 70 (20-130) |
3% | 10 (0-30) |
<1% | 10 (0-20) |
1% |
| Total | 2,610 (2,410-2,810) |
100% | 2,610 (2,410-2,810) |
100% | 1,660 (1,460-1,860) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. *The 95 percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval. |
||||||
5.2 Responsibility for Different Types of Maltreatment
The degree to which CPS agencies share responsibility with other agencies varies by maltreatment type, with more agencies sharing responsibility for the more serious types of maltreatment. Notable percentages of CPS agencies shared responsibility for screening and intake of sexual abuse (39%) and of physical abuse (29%), while somewhat fewer CPS agencies shared lead responsibility with other agencies for neglect (19%) and other types of maltreatment (19%), (Table 5-2).
For the investigation response, more CPS agencies shared lead responsibility with other agencies for the more serious maltreatment allegations (Table 5-3). More than one-half of the agencies shared lead responsibility for investigation of cases that involved severe physical abuse (65%), severe sexual abuse (66%), moderate sexual abuse (68%), or a child fatality (51%). At the same time, CPS agencies typically had sole lead responsibility for investigating forms of maltreatment that are regarded as more of the province of social work than law enforcement. More than
| Maltreatment type | Lead | Share | Support | None | Missing | Total |
|---|---|---|---|---|---|---|
| Physical abuse | 63% | 29% | 2% | 2% | 4% | 100% |
| Sexual abuse | 50% | 39% | 6% | 2% | 3% | 100% |
| Neglect | 75% | 19% | 2% | 2% | 3% | 100% |
| Other | 73% | 19% | 2% | 1% | 4% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
one-half of agencies had lead responsibility when the case involved moderate physical abuse (50%), moderate neglect (78%), severe emotional maltreatment (70%), moderate emotional maltreatment (73%), lack of supervision (76%), abandonment (65%), or a drug exposed infant (64%). Also, CPS agencies typically had lead responsibility when the allegation involved risk of maltreatment.
| Maltreatment type | Lead | Share | Support | None | Missing | Total |
|---|---|---|---|---|---|---|
| Severe physical abuse | 23% | 65% | 11% | --- | 2% | 100% |
| Moderate physical abuse | 50% | 47% | 2% | --- | 1% | 100% |
| At risk of physical abuse | 76% | 12% | 2% | 9% | 1% | 100% |
| Severe sexual abuse | 19% | 66% | 13% | --- | 2% | 100% |
| Moderate sexual abuse | 21% | 68% | 10% | --- | 1% | 100% |
| At risk of sexual abuse | 60% | 25% | 4% | 10% | 1% | 100% |
| Severe neglect | 50% | 46% | 3% | --- | 1% | 100% |
| Moderate neglect | 78% | 19% | 1% | 1% | 1% | 100% |
| At risk of neglect | 73% | 9% | 3% | 12% | 2% | 100% |
| Severe emotional maltreatment | 70% | 24% | 2% | 3% | 1% | 100% |
| Moderate maltreatment | 73% | 19% | 2% | 5% | 1% | 100% |
| At risk of emotional maltreatment | 67% | 11% | 4% | 16% | 2% | 100% |
| Truancy | 6% | 18% | 27% | 48% | 2% | 100% |
| Lack of supervision | 76% | 21% | 1% | 1% | 1% | 100% |
| Abandonment | 65% | 31% | 1% | 1% | 1% | 100% |
| Drug exposed infant | 64% | 31% | 1% | 3% | 1% | 100% |
| Status offense | 9% | 9% | 17% | 60% | 5% | 100% |
| Child fatality | 12% | 51% | 31% | 4% | 2% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
The differences in CPS agency responsibility for the different types of maltreatment under the investigation and alternative responses were striking. Most agencies did not provide any alternative response for the more serious types of maltreatment (Table 5-4). More than one-half of CPS agencies did not provide alternative response for cases that involved severe physical abuse (57%), moderate physical abuse (52%), severe sexual abuse (55%), moderate sexual abuse (55%), severe neglect (55%), severe emotional maltreatment (52%), or status offenses (52%). Approximately one-quarter of agencies shared lead responsibility for the alternative response for severe physical abuse (22%), severe sexual abuse (26%), moderate sexual abuse (25%), or child fatality (23%).
| Maltreatment type | Lead | Share | Support | None | Missing | Total |
|---|---|---|---|---|---|---|
| Severe physical abuse | 13% | 22% | 5% | 57% | 3% | 100% |
| Moderate physical abuse | 25% | 20% | 1% | 52% | 2% | 100% |
| At risk of physical abuse | 56% | 11% | 6% | 24% | 3% | 100% |
| Severe sexual abuse | 9% | 26% | 8% | 55% | 2% | 100% |
| Moderate sexual abuse | 12% | 25% | 6% | 55% | 2% | 100% |
| At risk of sexual abuse | 40% | 19% | 6% | 32% | 3% | 100% |
| Severe neglect | 24% | 15% | 2% | 55% | 3% | 100% |
| Moderate neglect | 37% | 13% | 2% | 45% | 3% | 100% |
| At risk of neglect | 62% | 10% | 7% | 20% | 2% | 100% |
| Severe emotional maltreatment | 33% | 12% | 2% | 52% | 2% | 100% |
| Moderate maltreatment | 40% | 12% | 2% | 45% | 2% | 100% |
| At risk of emotional maltreatment | 57% | 9% | 7% | 26% | 1% | 100% |
| Truancy | 9% | 13% | 37% | 40% | 1% | 100% |
| Lack of supervision | 48% | 12% | 2% | 36% | 1% | 100% |
| Abandonment | 34% | 14% | 2% | 49% | 1% | 100% |
| Drug exposed infant | 36% | 17% | 2% | 43% | 2% | 100% |
| Status offense | 11% | 5% | 29% | 52% | 3% | 100% |
| Child fatality | 8% | 23% | 17% | 50% | 2% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||||
The preceding tables revealed that, across the different types of maltreatment, CPS agencies often shared lead responsibility with other agencies, particularly for the screening and investigation functions. Further analyses examined the specific agencies that were involved in CPS functions for different types of maltreatment. CPS agencies shared lead responsibility with law enforcement more often than any other type of agency (Table 5-5). Nearly three-quarters of CPS agencies shared lead responsibility with law enforcement agencies for physical abuse (72%) and sexual abuse (70%).1 Fewer CPS agencies shared lead responsibility with law enforcement for neglect (58%) and emotional maltreatment (24%).
Since so few CPS agencies reported involvement by any single other type of agency, all nonlaw enforcement agencies were grouped together for these analyses. Nonlaw enforcement agencies include: juvenile justice agencies, mental health agencies, child advocacy centers or child protection teams, schools, centralized intake units, and licensing agencies. Just 17 percent of CPS agencies shared lead responsibility with other, nonlaw enforcement agencies for physical abuse while 18 percent shared lead responsibility for sexual abuse. The percentages for the other types of maltreatment were similarly low, with 17 percent of CPS agencies sharing lead responsibility for neglect and 20 percent sharing for other types of maltreatment.
| Law Enforcement Agencies | Other, Nonlaw Enforcement Agencies | |||
|---|---|---|---|---|
| Agency Involvement | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent |
| Share lead responsibility for physical abuse | 1,870 (1,650-2,090) |
72% | 430 (310-560) |
17% |
| Share lead responsibility for sexual abuse | 1,810 (1,580-2,040) |
70% | 470 (350-590) |
18% |
| Share lead responsibility for neglect | 1,510 (1,310-1,710) |
58% | 440 (310-570) |
17% |
| Share lead responsibility for emotional maltreatment | 630 (450-810) |
24% | 530 (390-670) |
20% |
| Note: Cells in italics are based on 10 or fewer agencies. Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Percentages are based on weighted total of 2,610 agencies. |
||||
5.3 Responsibility for Different Types of Perpetrators
The survey also asked a series of questions to determine the degree of shared responsibility for cases involving different types of perpetrators. Overall, similar percentages of CPS agencies shared lead responsibility for investigations across the different types of perpetrators (Table 5-6). Approximately one-third of CPS agencies shared lead responsibility for conducting investigations when the perpetrator was a family member or relative (39%), a foster parent (37%), a staff member at a group home or institution (36%), or a minor (35%).
While fewer CPS agencies shared lead responsibility for the alternative response function, again the percentages were similar across the different types of perpetrators (Table 5-7). Around one-fifth of agencies with an alternative response shared lead responsibility with other agencies when the perpetrator was a family member or relative (20%), a foster parent (16%), a staff member at a group home or institution (20%), or a minor (21%). Under alternative response, many agencies did not have responsibility for cases when the perpetrator was a foster parent (43%), a group home or facility staff person (48%), or a minor (36%).
| Perpetrator | Lead | Share | Support | None | Missing | Total |
|---|---|---|---|---|---|---|
| Family member or relative | 56% | 39% | 2% | <1% | 3% | 100% |
| Foster parent | 37% | 37% | 20% | 3% | 3% | 100% |
| Group home or institution staff | 23% | 36% | 23% | 14% | 4% | 100% |
| Minor | 41% | 35% | 12% | 6% | 5% | 100% |
| Not a caregiver | 7% | 12% | 34% | 45% | 2% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||||
| Perpetrator | Lead | Share | Support | None | Missing | Total |
|---|---|---|---|---|---|---|
| Family member or relative | 41% | 20% | 3% | 31% | 5% | 100% |
| Foster parent | 23% | 16% | 14% | 43% | 4% | 100% |
| Group home or institution staff | 11% | 20% | 19% | 48% | 2% | 100% |
| Minor | 28% | 21% | 11% | 36% | 4% | 100% |
| Not a caregiver | 11% | 5% | 30% | 51% | 3% | 100% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||||
The preceding tables also revealed that CPS agencies were very commonly involved with other agencies in some capacity across the different types of perpetrators. Further analyses found that for most types of perpetrators these agencies shared lead responsibility more often with law enforcement than with any other type of agency. A substantial minority of CPS agencies (41%) shared lead responsibility with law enforcement when the perpetrator was a family member or relative (Table 5-8). Thirty percent shared responsibility with law enforcement when the perpetrator was a minor. Nearly one-quarter (24%) of CPS agencies reported sharing lead responsibility with law enforcement when the perpetrator was the child's foster parent, while 17 percent shared when the alleged perpetrator was a staff person from a group home or institution. Only 13 percent of CPS agencies shared lead responsibility with law enforcement for noncaregiver perpetrators.
| Law Enforcement Agencies | Other, Nonlaw Enforcement Agencies | |||
|---|---|---|---|---|
| Agency Involvement | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent |
| Share for family member or relative | 1,070 (910-1,230) |
41% | 80 (30-130) |
3% |
| Share for minor | 770 (630-910) |
30% | 210 (130-290) |
8% |
| Share for foster parent | 610 (490-740) |
24% | 430 (320-530) |
16% |
| Share for group home or institution staff | 440 (330-540) |
17% | 580 (450-710) |
22% |
| Share for noncaregivers | 350 (240-450) |
13% | 30 (0-60) |
1% |
| Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Cells in italics are based on 10 or fewer agencies. |
||||
Other, nonlaw enforcement agencies were also involved with CPS agencies for different types of perpetrators (Table 5-8). However, with one exception, sharing with other nonlaw enforcement agencies was relatively rare. Very few nonlaw enforcement agencies were involved in responding to maltreatment perpetrated by a family member or relative (3%), minor (8%), foster parent (16%), or noncaregiver (1%). CPS agencies were somewhat more likely to share lead responsibility with other nonlaw enforcement agencies for maltreatment perpetrated by a staff member at a group home or institution.
5.4 Conclusion
While more CPS agencies claimed lead responsibility across all type of maltreatment for the screening function, very few had overall lead responsibility for the investigation and alternative response functions. The specific circumstances of the maltreatment also shaped the role of CPS agencies. CPS agencies shared lead responsibility more often for the more serious forms of maltreatment. CPS agencies shared lead responsibility for screening more often for physical abuse (29%) and sexual abuse (39%) than for neglect (19%) or other maltreatment. Similarly, while 65 percent of CPS agencies shared lead responsibility for severe physical abuse, the percentages for moderate physical abuse (47%) and at risk of physical abuse (12%) were much lower. CPS agencies were most likely to have lead responsibility when an investigation or an alternative response related to a perpetrator who was a family member or a relative. Approximately one-half of the agencies did not provide alternative response in cases that included foster parents, group home or institutional staff, or minors.
The findings also reveal a distinction between the role of law enforcement and that of other agencies in CPS work. Across different types of maltreatment, CPS agencies reported sharing lead responsibility with law enforcement more often than with any other type of agency. While nearly three-quarters of CPS agencies shared lead responsibility with law enforcement for physical and sexual abuse, fewer than 20 percent of agencies shared with other, nonlaw enforcement agencies for these types of maltreatment. The same pattern holds true for different types of perpetrators with more sharing of lead responsibility with law enforcement agencies. While 41 percent of CPS agencies shared lead responsibility with law enforcement agencies when the perpetrator was a family member or relative, just 3 percent shared with other agencies for this type of perpetrator. Together, these differences emphasize the significant role law enforcement agencies play in CPS processes. Law enforcement agencies are the only other agencies besides CPS agencies that can receive mandated reports of child maltreatment, enforce the applicable criminal law, and remove children from their parents, if they are being maltreated or are at risk of maltreatment.
Endnote
1 If a CPS agency said that they shared lead responsibility with law enforcement for physical abuse for any of the three functions (screening, investigation, alternative response), then that agency was counted as sharing lead responsibility with law enforcement for physical abuse.
Chapter 6. Changes in Practice
In addition to examining current practices, the LAS focused on types of changes being undertaken by CPS agencies regarding agency organization and administration, community partnerships, screening and intake, investigation, and alternative response. Results are presented in terms of national estimates of the number and proportion of agencies making such changes, with specific qualitative exemplar responses from the survey.
6.1 Degree of change in CPS agencies
Most agencies have not experienced recent change in their practices and processes with respect to the screening/intake, investigation, and alternative response functions. For screening and intake (36%), investigation (37%), and for alternative response (30%), approximately one-third of agencies had had their overall current practices and processes in place between 1 and 4 years (Table 6-1). Another one-third of the agencies had had their practices in place for between 5 and 10 years, with about 15 percent of agencies having their practices in place for more than 10 years.
| Process | Total | |
|---|---|---|
| Estimate (C.I.) * |
Percent | |
| Screening/Intake Process | ||
| Processes in place 1-2 years | 460 (310-610) |
18% |
| Processes in place 3-4 years | 470 (350-600) |
18% |
| Processes in place 5-10 years | 960 (790-1,130) |
37% |
| Processes in place more than 10 years | 390 (270-510) |
15% |
| Missing | 330 (220-430) |
13% |
| Total | 2,610 | 100% |
| Investigation Process** | ||
| Processes in place 1-2 years | 570 (440-710) |
22% |
| Processes in place 3-4 years | 390 (280-500) |
15% |
| Processes in place 5-10 years | 870 (720-1,020) |
33% |
| Processes in place more than 10 years | 400 (270-520) |
15% |
| Missing | 380 (270-490) |
15% |
| Total | 2610 | 100% |
| Other CPS Response Process*** | ||
| Processes in place 1-2 years | 280 (200-370) |
17% |
| Processes in place 3-4 years | 220 (150-300) |
13% |
| Processes in place 5-10 years | 590 (450-730) |
35% |
| Processes in place more than 10 years | 310 (200-420) |
19% |
| Missing | 260 (140-370) |
15% |
| Total | 1,660 | 100% |
| Note: Numbers in italics are based on 10 or fewer agencies * The 95-percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval. ** X2=22.59, p<.001 (excludes missing) *** X2=15.16, p<.01 (excludes missing) |
||
Agencies appeared to be actively adjusting or modifying other parts or components of their practices. While Table 6-1 indicates fairly stable practices for the major CPS functions, a separate module of the questionnaire examined how many and what types of all changes had been recently implemented. One-quarter of CPS agencies had not implemented any changes in the last 6 months, but three-quarters had implemented changes (Table 6-2). Nearly one-third (31%) had implemented one to two changes and 19 percent had implemented three to four changes in the last 6 months. Fourteen percent of agencies had implemented five to eight changes in the last 6 months while 11 percent had made more than eight changes.
| Number of changes | Estimate (C.I.) |
Percent |
|---|---|---|
| None | 660 (500-810) |
25% |
| 1-2 changes | 800 (640-960) |
31% |
| 3-4 changes | 490 (350-630) |
19% |
| 5-8 changes | 370 (270-470) |
14% |
| More than 8 changes | 290 (180-400) |
11% |
| Total | 2,610 (2,410-2,810) |
100% |
Many agencies also were considering changes during the prior 6 months. Table 6-3 shows how many changes had been considered during the last 6 months for all CPS agencies. One-third of agencies had not considered any changes in the last 6 months, but two-thirds had considered changes. More than one-quarter had considered one to two changes, 14 percent reported that they had considered three to four changes in the last 6 months, and 18 percent had considered five to eight changes.
| Number of changes | Estimate (C.I.) |
Percent |
|---|---|---|
| None | 850 (700-1,110) |
33% |
| 1-2 changes | 670 (520-810) |
26% |
| 3-4 changes | 360 (240-470) |
14% |
| 5-8 changes | 480 (360-600) |
18% |
| More than 8 changes | 250 (170-330) |
10% |
| Total | 2,610 | 100% |
6.2 Changes in organization
The greatest number changes were made to the overall organization of CPS agencies in the prior 6 months. These included areas such as training, information technology, staffing changes, and agency philosophy.
In the area of staff training, more than one-quarter (27%) of agencies made changes in this area during the preceding 6 months. In addition, 15 percent of agencies had considered changes related to staff training. Some examples of the more frequent types of changes reported in the survey included changes to the required training on specific topics, a general overhaul of training for new or existing staff, changes in training requirements for existing staff, and decreasing the total amount of training required.
More than one-quarter of CPS agencies (26%) had implemented changes in the use of information technology while 21 percent had considered such changes in the last 6 months. Almost all of the examples provided through the survey involved new or updated computer or reporting systems. Some agencies also had implemented systems that gave them access to other agency databases, while others had created a separate information technology unit or office.
Other recent changes implemented by CPS agencies involved the realignment of responsibility for core CPS functions. Sixteen percent of agencies had implemented such changes in the last 6 months, while 18 percent had considered them. Examples of such changes included changes in personnel (such as additions, reassignments, subtractions, or promotions of workers) and organizational changes with the formation of a unit or team.
Thirteen percent of agencies had implemented changes in their philosophy of service. Of these agencies, 23 percent mentioned a focus on safety and 20 percent mentioned a focus on family-centered services. Other types of changes that were mentioned included implementing a "best practices" approach; renewing the vision of the agency; emphasizing a case worker instead of a case manager approach; and establishing a more locally-based foster care response system to minimize trauma to children due to relocation.
Another 13 percent had considered such changes in the last 6 months. Of these, 20 percent discussed the addition of a multiple or differential response system. Other changes that were being considered included seeking accreditation by the Council on Accreditation; rewriting the agency manual; and increasing peer reviews to ensure continuous improvement.
| Change | Considered change | Implemented change | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Staff training | 390 (280-510) |
15% | 700 (530-860) |
27% |
| Use of information technology | 540 (430-660) |
21% | 670 (520-820) |
26% |
| Realignment of responsibility for functions | 470 (330-610) |
18% | 410 (270-550) |
16% |
| Philosophy of services | 350 (240-450) |
13% | 340 (250-430) |
13% |
| Agency requirements for staff qualifications | 400 (260-530) |
15% | 290 (190-390) |
11% |
| Degree of staff specialization | 230 (120-340) |
9% | 210 (140-280) |
8% |
| Decentralization of agency | 220 (130-300) |
8% | 190 (110-270) |
7% |
| Colocating workers | 180 (100-260) |
7% | 180 (120-250) |
7% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Percentages are based on weighted total of 2,610 agencies |
||||
6.3 Changes in Community Partnerships
Many agencies were also implementing changes in their relationships with other agencies and entities in the community. Such changes included collaboration with substance abuse and domestic violence providers, as well as other types of community service providers.
Eleven percent of CPS agencies had implemented changes and 14 percent had considered changes related to their collaboration with alcohol and drug agencies (Table 6-5). Examples included improved coordination through joint staffing of cases, task forces, or committees. Sixteen percent of agencies had implemented recent changes in their collaboration with domestic violence agencies, while 10 percent were considering such changes. Examples of such changes included coordinating with domestic violence agencies on specific programs or participating with domestic violence agencies on a team. CPS agencies also had either implemented (17%) or considered (13%) changes in their collaboration with other agencies. Some examples included collaborating with specific other agencies, such as mental health or law enforcement, while others described their involvement in multidisciplinary teams.
Sixteen percent of CPS agencies had implemented changes in the past 6 months related to the use of community-based organizations as service providers, while 10 percent of agencies had considered such changes in the last 6 months. Fewer CPS agencies had implemented (7%) or considered (5%) changes in the use of community-based organizations as case management service providers. It was also less common for CPS agencies to have implemented or considered changes in the use of community boards or citizen review boards.
| Change | Considered change | Implemented change | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Collaboration with alcohol and drug agencies | 360 (250-470) |
14% | 290 (200-380) |
11% |
| Collaboration with domestic violence agencies | 270 (180-360) |
10% | 420 (310-540) |
16% |
| Collaboration with other agencies | 350 (240-460) |
13% | 430 (290-580) |
17% |
| Use of community-based organizations as service providers | 260 (170-350) |
10% | 420 (290-540) |
16% |
| Use of community-based organizations as case management service providers | 120 (60-180) |
5% | 180 (100-260) |
7% |
| Use of community boards | 170 (90-250) |
7% | 170 (90-250) |
7% |
| Use of citizen review boards | 220 (130-310) |
8% | 130 (60-200) |
5% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Percentages are based on weighted total of 2,610 agencies. |
||||
6.4 Changes to Screening/Intake
Among the relatively small number of agencies that implemented changes to the screening/intake function, most added assessments or made changes in the way that referrals were processed. Seventeen percent of agencies had implemented changes in the use of assessments or other tools during the screening process during the preceding 6 months (Table 6-6). Nine percent of agencies had considered such changes. Seven percent of agencies had implemented changes in the processing of referrals and 9 percent had considered change in this area. Examples of such changes included personnel changes among CPS workers or how referrals to other agencies were handled. While 6 percent of CPS agencies had made changes in their response options in the prior 6 months, 12 percent were considering making changes. All of the other changes related to the screening function had been implemented by 5 percent or fewer of agencies.
| Change | Considered change | Implemented change | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Use of assessments or other tools | 230 (150-310) |
9% | 440 (320-550) |
17% |
| Processing of referrals | 230 (150-310) |
9% | 170 (90-250) |
7% |
| Response options | 310 (220-410) |
12% | 150 (90-220) |
6% |
| Amount of interaction with reporter and collaterals during screening | 180 (100-250) |
7% | 140 (80-190) |
5% |
| Programs/services available for screened-out referrals | 150 (80-210) |
6% | 140 (80-200) |
5% |
| Criteria for screening out referrals | 110 (60-150) |
4% | 90 (40-140) |
4% |
| Amount of interaction with family and/or child during screening | 180 (100-260) |
7% | 50 (0-90) |
2% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||
6.5 Changes in Investigation and Alternative Response
Overall, CPS agencies had implemented or considered relatively few changes in the functional area of investigation during the prior 6 months. Nine percent of agencies had implemented changes related to their use of multidisciplinary teams during the investigative process. An additional 6 percent had considered making such changes. Six percent of CPS agencies had implemented changes related to the role of law enforcement in investigating referrals, while 10 percent indicated that they had considered such a change in the last 6 months. Five percent or fewer of CPS agencies had implemented each of a range of other changes in the investigative process (Table 6-7).
| Change | Considered change | Implemented change | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Use of multidisciplinary teams | 170 (100-240) |
6% | 240 (160-330) |
9% |
| Role of law enforcement in investigating referrals | 270 (170-370) |
10% | 150 (70-220) |
6% |
| Use of risk assessments or other tools | 230 (150-320) |
9% | 140 (80-200) |
5% |
| Use of Child Advocacy Centers | 210 (130-290) |
8% | 140 (70-210) |
5% |
| Definitions of maltreatment | 130 (60-200) |
5% | 140 (40-230) |
5% |
| Amount of interaction with family and/or child | 180 (110-240) |
7% | 70 (20-120) |
3% |
| Other changes related to response | 80 (80-130) |
3% | 70 (20-120) |
3% |
| Central registries | 190 (110-180) |
7% | 90
(30-150) |
3% |
| Use of other mechanisms for joint investigation | 80 (30-130) |
3% | 60 (20-110) |
2% |
| Classification of referrals at end of response | 130 (70-190) |
5% | 50 (10-100) |
2% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 2,610 agencies. |
||||
Similar to the investigation function, few agencies were implementing or considering changes in the alternative response function (Table 6-8). Nine percent of CPS agencies had implemented changes during the prior 6 months in their use of risk assessment or other tools during their alternative response function. An additional 9 percent of agencies had considered such changes. A few agencies had implemented (7%) or considered (3%) changes related to their use of multidisciplinary teams during the alternative response. The remaining changes in this area were implemented by fewer than 5 percent of CPS agencies.
| Change | Considered change | Implemented change | ||
|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Use of risk assessments or other tools | 140 (90-200) |
9% | 160 (60-250) |
9% |
| Use of multidisciplinary teams | 60 (10-100) |
3% | 120 (50-190) |
7% |
| Classification of referrals at end of the response | 90 (50-140) |
6% | 60 (30-100) |
4% |
| Use of Child Advocacy Centers | 70 (20-120) |
4% | 50 (0-90) |
3% |
| Amount of interaction with family and/or child | 90 (40-140) |
5% | 30 (10-60) |
2% |
| Use of other mechanisms for joint investigation | 40 (10-80) |
3% | 40
(10-60) |
2% |
| Other changes related to response | 20 (0-40) |
1% | 30 (0-60) |
2% |
| * Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. Note: Percentages are based on weighted total of 1,660 agencies. |
||||
6.6 Conclusion
The findings present an interesting perspective on change in CPS among local agencies that suggests a fair degree of stability in the way that agencies have conducted the basic CPS functions. Approximately one-third of all agencies have not undertaken any major changes for a period of 4 years. However, approximately 75 percent of agencies reported having implemented some changes within the past 6 months. Examination of descriptive statements shows that changes were often related to particular processes within the overall broad functions of CPS. In other words, while there is overall stability, many modifications and adjustments are being conducted. When specific areas of change are examined, nearly one-third had implemented changes in training and the use of information technology; approximately 15 percent had implemented changes in realignment of functions, philosophy of services, staff qualifications, collaboration with domestic violence agencies, collaboration with other community agencies, use of community-based organizations as service providers, and the use of assessments or other tools. This survey is the first to attempt an estimate of how deeply changes have reached into the CPS field. This survey indicates that changes are not as deep at the local level as might have been assumed based on anecdotal accounts.
Chapter 7. Differences Among Agencies by Administrative Structure
The analyses for the Local Agency Survey (LAS) also examined any differences across local agencies that were tied to agency administrative structure at the State level. Administrative structure refers to the method of assigning organizational authority for CPS among subjurisdictions in a State. In some States, the entire CPS program is managed and operated by the State, the local agencies are offices of the State, local employees are State employees, the managers and administrators of the local offices report to the director of the State agency, infrastructure is centralized, and so forth. In other States, CPS is run by county agencies or similar jurisdictions where the managers and administrators report to a board of county commissioners, the employees are county employees, and the county provides basic infrastructure, and so forth. However, policies for these county-administered systems are usually defined at the State level, resulting in the designation that such systems are State supervised and county administered.
The type of administrative structure found in a State CPS agency is determined by the State and the category of structure used in these analyses was identified to the study by the State agency. This is distinct from self-identification of administrative structure by the local agency, which may be perceived differently by staff in a local agency compared to what is generally acknowledged by staff at the State level.
The primary basis for the administrative structure information is data collected and maintained by the American Public Human Services Association (APHSA), as modified through the review of policies and interviews described as a part of the Review of State CPS Policies, an earlier report from this study.1 To reiterate those findings, 13 States (25.5%) were characterized as State supervised/county administered and 38 States (74.5%) were characterized as State administered. Based on the policy review and interviews, eight, or one-fifth of State-administered systems (21%), were reclassified based on direct input from the State agencies involved as having strong county structure and discretion, although not as county administered according to study criteria.
Based on the data supplied through the Review of State CPS Policies, the three categories of administrative structure were used in this analysis: State-administered, State-administered/strong county structure, and State supervised/county administered. When statistically significant differences based on this Administrative structure emerged, analyses detailing the nature of the differences found for CPS agencies with each type of administrative structure are described in this chapter.
7.1 Agency Staff and Service Provision
State-administered agencies had more staff compared to State-administered agencies with strong county structure. The average number of social workers or caseworkers among State-administered agencies was 31, for county-administered agencies it was 18, and for State-administered agencies with strong county structure the average was 4. A statistically significant difference was noted when the State-administered agencies were compared to the State-administered agencies with strong county structure.2
Specialization of Staff
Both State-administered and county-administered agencies also had more staff specializing in investigations when compared to State-administered agencies with strong county structure. The number of full-time caseworker or social worker staff who were only assigned investigations for both State-administered and county-administered agencies averaged five workers, while for State-administered agencies with strong county structure the average was two, which was a statistically significant difference when compared to both State- and county-administered agencies.
There were two supervisors assigned to other responsibilities in addition to investigation in county-administered agencies compared to one in State-administered agencies, each of which averaged five full-time workers who only conducted investigations (Table 7-1).
| Statistical comparison | Full-time workers who only conducted investigations | Supervisors who supervised investigation in addition to other responsibilities | ||
|---|---|---|---|---|
| Estimate (C.I.) * |
Estimate (C.I.) |
|||
| A | State-administered | 5 (3-7) |
1 (1-1) |
|
| B | County-administered | 5 (3-7) |
2 (1-2) |
|
| C | State-administered with a strong county structure | 2 (1-3) |
1 (1-2) |
|
| * The 95 percent confidence interval (C.I.) indicates that, if the study were to be repeated with the same methodology 100 times, 95 of the replications would produce an estimate within the interval. b-c: T = 2.063, p < 0.05 a-c: T = 2.040, p < 0.05 a-b: T = -2.796, p < 0.01 |
||||
State-administered agencies have a higher percentage of workers that strictly specialize in conducting either screening/intake or investigations compared to county-administered agencies, and the percentage of specialized workers in State-administered agencies with a strong county structure fall between. On the other hand, county-administered agencies appear to have a greater percentage of staff that fill in and perform other functions when needed. For the screening/intake and investigation function 43 percent of State-administered agencies were estimated to have specialized staff members, while 23 percent of county- and 32 percent of State-administered with strong county structure had specialized staff. Staff routinely switched between functions if needed for 24 percent of county-administered agencies, 21 percent of State-administered agencies with strong county structure, and 13 percent of State-administered agencies. Roughly comparable percentages of agencies had staff who performed both functions; State-administered (37%), county-administered (45%), and State-administered agencies with strong county structure (46%). Differences between agencies were not found to be significant in terms of child population (Table 7-2).
| Staff | State-administered | County-administered | State-administered with a strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Different workers for screening/intake and investigation | 480 (340-610) |
43% | 220 (160-290) |
23% | 170 (70-280) |
32% |
| When needed, an intake worker can conduct an investigation, or an investigation worker can conduct screening/intake | 140 (70-210) |
13% | 230 (160-300) |
24% | 110 (30-190) |
21% |
| Workers routinely conduct both screening/intake and investigation | 410 (300-520) |
37% | 430 (350-520) |
45% | 250 (130-380) |
46% |
| Other | 60 (10-100) |
5% | 60 (30-90) |
6% | 10 (<1-30) |
2% |
| No Response | 10 (<1-30) |
1% | 20 (<1-30) |
2% | <1 (<1-<1) |
<1% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| X2 = 15.756, p < 0.05 | ||||||
Despite similarities in the numbers of staff that are specialized, county-administered agencies have more workers who are also assigned other responsibilities besides screening and intake compared to State-administered agencies. Among those social workers or caseworkers who also were assigned other responsibilities in addition to screening and intake, the average number for State-administered agencies was three, for county-administered agencies the average was six, and for State-administered agencies with strong county structure the average was four. The difference between State administered and county-administered agencies suggests that county agencies might not have specialized in the screening and intake function to the same degree that State-administered agencies did. In general, it appeared that at least one-half of the staff assigned to this function at either the caseworker or supervisory level was assigned to other responsibilities.3
As with screening/intake and investigations, the pattern of State-administered agencies having higher percentages of workers that specialize is repeated in comparing specialization of workers performing screening/intake versus alternative response, with State-administered agencies with strong county structure falling in the middle. For instance, more State-administered agencies (43%) had specialized staff compared to county-administered agencies (21%), and State-administered agencies with strong county structure (31%). A greater proportion of State-administered agencies with strong county structure (28%) used staff on an as-needed basis compared to State-administered agencies (12%) or county-administered agencies (13%). A higher proportion of county-administered agencies (48%) used staff in both functions than State-administered agencies (39%) and State-administered agencies with strong county structure (36%), (Table 7-3).
| Staff | State-administered | County-administered | State-administered with a strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Different workers for screening/intake and other response | 330 (230-430) |
43% | 120 (60-180) |
21% | 100 (30-180) |
31% |
| When needed, an intake worker can conduct an other response, or an other response worker can conduct screening/intake | 90 (30-150) |
12% | 70 (30-110) |
13% | 90 (30-160) |
28% |
| Workers routinely conduct both screening/intake and other response | 300 (220-380) |
39% | 270 (210-340) |
48% | 120 (30-220) |
36% |
| Other | 40 (<1-80) |
5% | 80 (40-120) |
14% | 20 (<1-40) |
5% |
| No Response | -- | -- | 20 (0-40) |
4% | -- | -- |
| Total | 760 (640-870) |
100% | 570 (480-660) |
100% | 550 (350-750) |
100% |
| X2 = 21.107, p < 0.01 | ||||||
Services
Even though differences in the availability of specific services were found by administrative structure, no clear pattern differentiating agencies by administrative structure was identified. Statistically significant differences with respect to administrative structure were found for the following services categories:
- Investigation
- Dental exams (provided less often by State-administered agencies);
- Transportation (provided more often by county-administered agencies);
- Tutoring (provided less often by State-administered agencies and most often by State-administered agencies with strong county structure);
- Financial planning (provided less often by State-administered agencies);
- Child care (provided more often by county-administered agencies); and
- Employment services (provided less often by State-administered agencies).
- Alternative response
- Marital counseling (provided less often by county-administered agencies and State-administered agencies with strong county structure).
It appears that State-administered agencies could offer fewer services following an investigation when compared to county-administered agencies. The situation for alternative response is less conclusive (Table 7-4).
| Service | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate | Percen t | Estimate | Percent | Estimate | Percent | |
| Investigation | ||||||
| Dental examsa | 550 | 50% | 620 | 64% | 330 | 60% |
| Transportationb | 660 | 60% | 680 | 71% | 320 | 59% |
| Tutoringc | 370 | 34% | 410 | 43% | 280 | 52% |
| Financial planningd | 490 | 45% | 600 | 63% | 380 | 69% |
| Child caree | 820 | 74% | 780 | 81% | 390 | 71% |
| Employment servicesf | 520 | 48% | 640 | 66% | 340 | 62% |
| Alternative response | ||||||
| Marital counselingg | 590 | 78% | 430 | 75% | 200 | 61% |
| aX2 = 14.509, p < 0.05 bX2 = 16.344, p < 0.05 cX2 = 13.007, p < 0.05 dX2 = 20.539, p < 0.01 eX2 = 19.232, p < 0.01 fX2 = 19.162, p < 0.01 gX2 = 22.564, p < 0.05 |
||||||
State-administered agencies more often required that services be provided within 31-60 days compared to either county-administered or State-administered agencies with strong county structure (Table 7-5).
| Timeframe | State-administered | County-administered | State-administered with a strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| No time limit | 180 (100-260) |
16% | 240 (170-310) |
25% | 140 (20-260) |
26% |
| Time limit determined by supervisor | 310 (190-430) |
28% | 310 (230-380) |
32% | 100 (30-170) |
18% |
| No more than 1-30 days | 30 (0-60) |
3% | 90 (50-140) |
10% | 40 (<1-90) |
7% |
| No more than 31-60 days | 140 (50-230) |
12% | 60 (30-90) |
7% | --- | <1% |
| No more than 61-90 days | 90 (<1-160) |
8% | 10 (<1-20) |
<1% | 10 (<1-30) |
2% |
| Other | 320 (210-430) |
29% | 240 (170-320) |
25% | 230 (140-330) |
43% |
| No response | 30 (0-60) |
3% | 10 (0-20) |
<1% | 30 (<1-70) |
5% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| X2 = 44.761, p < 0.001 | ||||||
Among agencies providing alternative response, more State-administered agencies and State-administered agencies with strong county structure have service priority arrangements with multiple providers compared to county-administered agencies. County-administered agencies tend to have such a relationship with only one provider. A greater proportion of State-administered agencies (36%) and State-administered agencies with strong county structure (48%) had established priority service provision arrangements with multiple providers compared to county-administered agencies (22%). The results also indicate that county-administered agencies had more priority service relationships with mental health providers (9%) compared to the other two types of agencies; less than 1 percent for both of the other structure categories (Table 7-6).
| Arrangements | State-administered | County-administered | State-administered with a strong county struc ture | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Agency does not have priority status arrangements | 340 (230-450) |
45% | 250 (180-320) |
43% | 160 (60-250) |
47% |
| Agency has priority status arrangements with mental health providers | 20 (<1-40) |
<1% | 50 (10-90) |
9% | 10 (<1-30) |
<1% |
| Agency has priority status arrangements with substance abuse providers | 50 (20-90) |
7% | 40 (10-80) |
8% | --- | --- |
| Agency has priority status arrangements with other providers | 60 (10-110) |
8% | 40 (10-70) |
7% | --- | --- |
| Agency has priority status arrangements with multiple types of services providers | 270 (180-360) |
36% | 130 (60-190) |
22% | 160 (70-250) |
48% |
| No response | 10 (<1-20) |
1% | 60 (30-100) |
11% | 10 (<1-30) |
3% |
| Total | 760 (640-870) |
100% | 570 (480-660) |
100% | 340 (210-470) |
100% |
| X2 = 22.584, p < 0.05 | ||||||
Discussion
A key distinction between State-administered agencies (including those with strong county structure) and county-administered agencies is that more State-administered agencies have strictly specialized staff performing the screening/intake, investigation, and where it exist the alternative response function. On the other hand, both State-administered and county-administered agencies have the same average number of staff who are specialized. These findings indicate the difference appears to be tied to the expectation that specialized staff may fill in for other functions when needed in county-administered agencies.
From the analysis of service data there does not appear to be any specific trend that characterizes the differences between administrative structures. In the range of services that are available, county-administered agencies may have had a broader set of services to offer. Proportionally, more of these agencies may also have established priority service arrangements with mental health providers. On the other hand, when they had a priority service relationship, more State-administered agencies had such relationship with multiple providers. An important confirmation regarding CPS from these data is that around 75 percent of agencies were able to offer services regardless of the status of the response or the disposition. It is interesting to note, however, that a few agencies required a determination of maltreatment before they were able to offer services. Almost all agencies were able to offer a potentially wide range of services and most services could be offered in well over 50 percent of the agencies. While potentially offered, the availability of these services was not addressed in this study. Of the range of services that agencies offered — parenting, substance abuse, and child focused interventions appeared to be the most common, whereas, services that address financial well-being were less common.
7.2 Screening and Intake
Further analyses of the LAS findings revealed some important differences in the screening function depending on the agency's administrative structure. The differences emerged in how referrals were received and processed and in the role of the State hotline.
Receipt of Referrals
While the overall findings showed little variation in how referrals entered agencies, further analyses found some variation by administrative structure in some of the logistical aspects of receiving referrals. For example, weekday evening referrals were more often assigned to on-call staff in county-administered agencies (71%) than in agencies in either State-administered systems (39%) or State-administered systems with strong county structure (46%). Not surprisingly, weekday evening referrals were more often handled by the State hotline for agencies in State-administered systems and State-administered systems with strong county structure, (31% and 14%, respectively), when compared to county-administered agencies (4%), (Table 7-7). A similar pattern appeared with how agencies handled referrals on weekends. Agencies in county-administered systems assigned referrals to on-call staff much more often (74%) than did the other types of agencies (39% for agencies in State-administered systems and 53% for agencies in State-administered systems with strong county structure).
| Weekday evenings* | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Handled by intake unit | 30 (0-70) |
3% | 50 (20-70) |
5% | 50 (0-100) |
9% |
| Assigned to on-call staff | 430 (330-520) |
39% | 680 (590-770) |
71% | 250 (150-360) |
46% |
| Routed to another agency | 40 (0-80) |
3% | 40 (0-70) |
4% | 50 (0-100) |
9% |
| Handled by State hotline | 340 (230-460) |
31% | 40 (10-60) |
4% | 80 (0-160) |
14% |
| Other method | 90 (30-150) |
9% | 10 (0-30) |
1% | 50 (0-100) |
9% |
| Missing | 170 | 15% | 150 | 15% | 80 | 14% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| Weekends** | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent |
| Handled by intake unit | 20 (0-60) |
2% | 20 (0-40) |
2% | 10 (0-30) |
2% |
| Assigned to on-call staff | 430 (330-520) |
39% | 710
(640-780) |
74% | 290
(170-410) |
53% |
| Routed to another agency | 40 (0-80) |
3% | 40 (10-70) |
4% | 50 (0-100) |
9% |
| Handled by State hotline | 310 (200-420) |
28% | 40 (10-70) |
4% | 80 (0-160) |
14% |
| Other method | 140 (70-210) |
13% | 10 (0-30) |
1% | 50 (0-100) |
9% |
| Missing | 160 | 15% | 140 | 15% | 80 | 14% |
| Total | 1,100 (970-1,220) | 100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| * X2=20.05, p<.001 (excludes missing) ** X2=22.91, p<.001 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
A somewhat different pattern emerged for how different types of agencies handled referrals from non-English speakers. Many more agencies in State-administered systems (24%) handled referrals from non-English speakers with non-English speaking staff than did agencies in county-administered systems (6%) or State-administered systems with strong county structure (2%). In contrast, more than two-thirds of agencies in State-administered systems with a strong county structure used a method other than non-English speakers on staff or on call. This compares to 43 percent for agencies in county-administered systems and 38 percent for agencies in State-administered systems (Table 7-8).
| Referral assignments | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | E stimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Handled by non-English speakers on staff | 260 (170-350) |
24% | 60 (20-90) |
6% | 10 (0-30) |
2% |
| Handled by non-English speakers on call | 110 (40-180) |
10% | 110 (60-160) |
11% | 30 (0-70) |
5% |
| Other method | 420 (300-530) |
38% | 410 (320-510) |
43% | 370 (220-530) |
68% |
| Multiple methods | 180 (100-260) |
16% | 210 (150-270) |
22% | 50 (0-100) |
9% |
| Not able to accept | 130 (60-200) |
12% | 170 (90-250) |
18% | 90 (0-180) |
16% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| * X2=27.72, p<.001 Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Agencies in State-administered systems also stood out in terms of the automatic acceptance of referrals. Only 27 percent of agencies in State-administered systems automatically accepted referrals from some reporters. This practice was more common for agencies in county-administered systems (42%) or State-administered systems with strong county structure (53%), (Table 7-9).
| Referral acceptance | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Some referrals are automatically accepted | 300 (210-390) |
27% | 410 (320-490) |
42% | 290 (140-440) |
53% |
| No referrals are automatically accepted | 720 (580-860) |
66% | 540 (460-620) |
56% | 260 (150-370) |
47% |
| Missing | 80 (30-130) |
7% | 20 (0-40) |
2% | --- | --- |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
|
| * X2=8.68, p<.05 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Among those agencies that automatically accepted some referrals, 80 percent of agencies in State-administered systems accepted referrals from specific types of agencies. This compares to 55 percent of agencies with State-administered systems with strong county structure and 35 percent of agencies with county-administered systems. In contrast, agencies in county-administered systems (43%) and State-administered systems with strong county structure (38%) more often automatically accepted referrals from mandated reporters than did agencies in State-administered systems (14%), (Table 7-10).
| Referral acceptance | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Accept from specific agency | 240 (140-330) |
80% | 140 (100-180) |
35% | 160 (70-250) |
55% |
| Accept from multiple agencies | 40 (0-80) |
14% | 170 (100-250) |
43% | 110 (20-200) |
38% |
| Accept from all agencies | 20 (0-60) |
6% | 40 (0-80) |
11% | 20 (0-60) |
7% |
| Accept from central registry | --- | --- | 40 (0-70) |
11% | --- | --- |
| Total | 300 (210-390) |
100% | 410 (320-490) |
100% | 290 (140-440) |
100% |
| * X2=19.31, p<.01 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Processing Referrals
The overall survey findings showed that CPS agencies had flexibility in how they processed referrals during the screening function. In a few situations, the processing of referrals also depended on the agency's administrative structure. Nearly all agencies in county-administered systems (93%) performed the screening and intake function themselves (Table 7-11). While this was also true for the other types of agencies, the percentages were somewhat lower (76% for agencies in State-administered systems and 80% for agencies in State-administered systems with strong county structure). Not surprisingly, the State hotline performed screening less often for agencies in county-administered systems (5%) compared to agencies in State-administered systems (21%) or State-administered systems with strong county structure (17%).
| Referral processing | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Local agency screens | 830 (700-970) |
76% | 900 (840-960) |
93% | 440 (260-610) |
80% |
| State hotline screens | 230 (150-320) |
21% | 50
(20-80) |
5% | 90 (20-160) |
17% |
| Missing | 30 (0-70) |
3% | 20 (0-40) |
2% | 20 (0-60) |
3% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| * X2=9.10, p<.001 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
The analyses also revealed two screening activities that varied depending on the agency's administrative structure. Agencies in State-administered systems and those in State-administered systems with strong county structure always searched CPS records for alleged perpetrators (81% and 84%, respectively). This screening practice was somewhat less common among agencies in county-administered systems (77%), (Table 7-12). Use of safety assessment tools during screening also differed depending on the agency's administrative structure. While 65 percent of agencies in county-administered systems always used such safety assessments during screening, this was truer for agencies in State-administered systems (73%) and agencies in State-administered systems with strong county structure (70%).
| Screening activity | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Search CPS records for information on alleged perpetratora | 890 (770-1,010) |
81% | 750 (660-830) |
77% | 460 (280-650) |
84% |
| Use of safety assessment toolsb | 780 (680-920) |
73% | 630 (540-720) |
65% | 380 (220-540) |
70% |
| a X2=16.5, p<.001 b X2=23.68, p<.001 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Role of State Hotline
Agencies operating under different administrative structures also differed in terms of the role of the State hotline for the screening function. Not surprisingly, it was more common for agencies in State-administered systems (72%) and State-administered systems with strong county structure (72%) to receive referrals from the State hotline when compared to agencies in county-administered systems (38%), (Table 7-13).
| Hotline recommendations | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C .I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Yes | 790 (630-940) |
72% | 360 (290-440) |
38% | 400 (220-580) |
72% |
| No | 280 (180-380) |
25% | 590 (490-690) |
61% | 150 (50-250) |
28% |
| Missing | 30 (0-70) |
3% | 10 (0-30) |
1% | --- | --- |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| * X2=25.25, p<.001 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Among agencies that used State hotlines, 68 percent of agencies in State-administered systems and 44 percent of agencies in State-administered systems with strong county structure received recommendations from State hotlines regarding the response to the referral. This compares to just 7 percent of such agencies in county-administered systems (Table 7-14).
| Hotline recommendations | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Hotline makes recommendations | 530 (380-690) |
68% | 30 (10-50) |
7% | 180 (20-330) |
44% |
| Hotline does not make recommendations | 250 (160-340) |
32% | 320 (240-400) |
89% | 210 (100-320) |
53% |
| Missing | --- | --- | 10 (0-30) |
4% | 10 (0-30) |
2% |
| Total | 790 (630-940) |
100% | 360 (290-440) |
100% | 400 (220-580) |
100% |
| * X2=16.0, p<.001 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Discussion
The analysis by administrative structure found a number of situations where screening practices were different for different types of agencies. State-administered agencies were more likely to handle referrals from non-English speakers with regular or on call staff. However, agencies in State-administered systems were less likely to automatically accept certain referrals. When they did automatically accept referrals, these agencies were also less likely to automatically accept from mandated reporters. Rather, they more often automatically accepted from specific agencies.
County-administered agencies were different from the other agency types in a number of areas. County-administered agencies were more likely to utilize on-call workers to cover referrals received during non-business hours. Not surprisingly, these agencies were also more likely to screen locally and less likely to receive referrals from the State hotline and to receive response recommendations from the State hotline. In terms of processing referrals, two specific screening activities were different for agencies in county-administered systems. These agencies searched CPS records and used safety assessment tools considerably less often than other agencies.
7.3 Investigation and Alternative Response
The LAS analyses also examined how agencies with different administrative structures conducted investigations and alternative responses. This section describes the differences for both responses.
Investigation Response
In terms of the scope of the investigation response, agencies in State-administered systems with strong county structure appeared to be more flexible and expansive than other agencies. State-administered agencies with a strong county structure more often (67%) extended the investigation to all children in the household in all cases when compared to agencies in State-administered (51%) and county-administered systems (54%), (Table 7-15).
| Scope | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Only children specified in referral | 30 (0-60) |
3% | 60 (20-110) |
7% | 10 (0-30) |
2% |
| Extend to all children in household, case-by-case | 350 (230-480) |
32% | 290 (240-350) |
31% | 170 (70-270) |
31% |
| Extend to all children in household in all cases | 550 (420-690) |
51% | 520 (440-600) |
54% | 370 (190-550) |
67% |
| Missing | 160 (100-220) |
14% | 80 (40-130) |
9% | --- | --- |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. * X2=15.28, p<.05 |
||||||
The analyses revealed some differences in the procedures agencies used at the conclusion of their investigations. Agencies in State-administered (80%) and county-administered (85%) systems were somewhat more likely to always enter the perpetrator information into the Central Registry than were agencies in State-administered systems with strong county structure (72%), (Table7-16). The same patterns appear with regard to notifying the reporter at the conclusion of the investigation, more agencies in State- and county-administered systems (30% and 36%, respectively) always made this notification when compared to agencies in State-administered systems with strong county structure (17%).
| Procedure | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Enter perpetrator information in Central Registrya | 870 (760-990) |
80% | 820 (750-880) |
85% | 390 (210-580) |
72% |
| Notify reporterb | 330 (220-440) |
30% | 350 (270-430) |
36% | 90 (30-160) |
17% |
| a X2=27.13, p<.001 b X2=62.2, p<.001 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
These analyses also found a few differences in the frequency of specific investigative activities. Certain activities were much more common for agencies in State-administered systems with strong county structure. For example, a greater proportion of agencies in State-administered systems with strong county structure (19%) always discussed the case with a multidisciplinary team than did agencies in State-administered (5%) or county-administered systems (10%), (Table 7-17). Similarly, it was more common for agencies in State-administered systems with strong county structure to always interview the reporter and to always interview witnesses when compared to State- and county-administered agencies.
| Activity | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Discuss with Multidisciplinary Team a | 50 (0-100) |
5% | 100 (50-150) |
10% | 100 (30-180) |
19% |
| Interview reporterb | 450 (320-580) |
41% | 300 (230-370) |
31% | 370 (210-540) |
67% |
| Interview witnessesc | 680 (550-810) |
62% | 610 (530-690) |
63% | 410 (230-600) |
75% |
| Interview professionals known to familyd | 480 (340-620) |
44% | 330 (250-400) |
34% | 260 (130-380) |
47% |
| Conduct criminal background check on alleged perpetratore | 530 (410-640) |
48% | 190 (130-240) |
19% | 110 (40-180) |
20% |
| a X2=19.82, p<.05 b X2=22.94, p<.01 c X2=14.34, p<.05 d X2=13.25, p<.05 e X2=23.99, p<.01 Note: Percentages are not additive because agencies were included in each applicable row (category). |
||||||
Other investigation activities were also more common for State-administered agencies. Agencies in State-administered systems (44%) and those in State-administered systems with strong county structure (47%) always interviewed professionals known to the family more often than did agencies in county-administered systems (34%), (Table 7-22). Finally, more State-administered agencies (48%) always conducted criminal background checks on the alleged perpetrator than did agencies in county-administered systems (19%) or in State-administered systems with strong county structure (20%).
Only one difference by administrative structure emerged in how often agencies used different instruments or tools during the investigation. County-administered agencies (4%) were less likely to always conduct standardized domestic violence assessments as part of the investigation when compared to other agencies (15% for both State-administered and State-administered with strong county structure), (Table 7-18).
| Instruments and tools | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C .I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Always | 170 (80-250) |
15% | 40 (10-70) |
4% | 80 (10-140) |
15% |
| Sometimes | 890 (760-1,020) |
81% | 900 (810-980) |
93% | 470 (310-640) |
86% |
| Missing | 40 (0-80) |
3% | 20 (0-40) |
2% | --- | --- |
| Total | 1,100
(970-1,220) |
100% | 960
(890-1,030) |
100% | 550
(350-750) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. * X2=10.55, p<.05 |
||||||
The analyses also uncovered evidence that agencies in State-administered systems with strong county structure had fewer resources during investigations. In State- and county-administered systems both domestic violence specialists and substance abuse specialists were almost always available during investigations. While 81 percent of agencies in State-administered systems and 85 percent of agencies in county-administered always had access to domestic violence specialists, this was true for 69 percent of agencies in State-administered systems with strong county structure (Table 7-19). Similarly, 91 percent of State-administered agencies and 97 percent of county-administered agencies always had substance abuse specialists available during investigations, compared to 84 percent of agencies in State-administered systems with strong county structure. One exception to this pattern was related to access to hospital-based sexual abuse trauma centers. While 71 percent of county-administered agencies always had access to these centers, 46 percent of State-administered agencies and 60 percent of agencies in State-administered with strong county structure reported such widespread access.
| Type of assistance | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I .) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Domestic violence specialistsa | 880 (760-1,010) |
81% | 820 (740-900) |
85% | 380 (230-530) |
69% |
| Substance abuse specialistsb | 1,000 (870-1,130) |
91% | 930 (870-1,000) |
97% | 460 (270-650) |
84% |
| Hospital-based sexual abuse trauma centersc | 500 (370-630) |
46% | 690 (620-750) |
71% | 330 (200-470) |
60% |
| a X2=11.4, p<.05 b X2=15.04, p<.01 c X2=12.42, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). |
||||||
When examining the obstacles to timely completion of investigations, fewer barriers were found for agencies in State-administered systems with strong county structure. Just over one-half of the agencies in State-administered systems with strong county structure (52%) rarely cited the need to predict what might happen to the child as an obstacle to completing the investigation. This compares to 24 percent for agencies in both State- and county-administered systems (Table 7-20). The same pattern emerges for difficulties related to preparing materials for the case record, preparing materials for the court record, and handling language barriers. For these obstacles, agencies in State-administered systems with strong county structure rarely faced the obstacle compared to State- or county-administered agencies.
| Obstacles | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Predicting what might happen to the childa | 260 (170-350) |
24% | 230 (170-300) |
24% | 290 (150-420) |
52% |
| Preparing materials for case recordb | 310 (200-420) |
28% | 210 (160-260) |
22% | 240 (130-350) |
43% |
| Preparing materials for court recordc | 330 (220-430) |
30% | 300 (240-370) |
31% | 310 (170-450) |
57% |
| Handling language barriersd | 580 (460-690) |
53% | 510 (430-590) |
53% | 400 (220-570) |
72% |
| a X2=27.63, p<.001 b X2=20.6, p<.01 c X2=24.23, p<.01 d X2=17.68, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). |
||||||
Alternative Response
The supplemental analyses also examined the alternative response function to uncover any notable differences in how this response was carried out by agency administrative structure. Overall, when conducting an alternative response, agencies in State-administered systems with strong county structure were more consistent in several practices than agencies in State-administered systems or county-administered systems.
A few differences by administrative structure emerged in the standard practices for the alternative response. More agencies in State-administered systems with strong county structure (73%) were required to assess the family needs before completing the response, when compared to agencies in State-administered systems (60%) or county-administered systems (51%), (Table 7-21). It was also more common for agencies in State-administered systems with strong county structure to have requirements related to assessing the underlying causes of maltreatment and referring the family for further services before completing the response than it was for the other types of agencies.
| Practice | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Assess family needsa | 400 (300-490) |
60% | 250 (180-330) |
51% | 230 (120-350) |
73% |
| Assess underlying causes of maltreatmentb | 200 (120-280) |
31% | 150 (90-210) |
30% | 180 (90-270) |
52% |
| Refer family for further servicesc | 220 (140-300) |
34% | 120 (80-160) |
26% | 130 (60-200) |
42% |
| a X2=17.54, p<.05 b X2=15.81, p<.05 c X2=15.81, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). |
||||||
CPS agencies with different administrative structures had different procedures for concluding the alternative response. Agencies in State-administered systems with strong county structure (72%) always notified the perpetrator about the determination much more often than did the other types of agencies (37% for State-administered and 38% for county-administered), (Table 7-22). Likewise, State-administered agencies with strong county structure always entered perpetrator information into the Central Registry more frequently than did the other agencies (67% v. 34% and 35%).
| Procedure | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Notify perpetrator of determinationa | 280 (20-360) |
37% | 220 (160-280) |
38% | 240 (130-360) |
72% |
| Enter perpetrator information in Central Registryb | 260 (170-340) |
34% | 200 (130-270) |
35% | 220 (100-350) |
67% |
| a X2=27.86, p<.01 b X2=32.58, p<.001 Note: Percentages are not additive because agencies were included in each applicable row (category). |
||||||
The specific activities conducted during the alternative response also varied by the agency's administrative structure. Again, agencies in State-administered systems with strong county structure stood out from the other types of agencies. State-administered agencies with strong county structure were more likely to always work with multidisciplinary teams (11%) than State-administered agencies (4%) or county-administered agencies (7%), (Table 7-23). These agencies were also more likely than the others to conduct family group conference meetings, interview additional family members, interview the persons who made the report alleging maltreatment, and remove the child. A different pattern emerged for one alternative response activity. Almost all agencies in State-administered (87%) and agencies in State-administered systems with strong county structure (86%) always reviewed prior CPS records when conducting an alternative response, compared to just 67 percent of county-administered agencies (Table 7-23).
| Activity | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Discuss with multidisciplinary teama | 30 (0-70) |
4% | 40 (10-70) |
7% | 40 (0-90) |
11% |
| Conduct family group conference meetingb | 10 (0-20) |
1% | 20 (10-50) |
4% | 70 (10-120) |
20% |
| Interview family members other than the caregiverc | 140 (70-210) |
19% | 140 (80-190) |
24% | 130 (50-220) |
39% |
| Interview reporter who alleged maltreatmentd | 120 (70-180) |
16% | 120 (60-180) |
21% | 260 (150-370) |
76% |
| Remove child if evidence of harm or danger of harme | 370 (260-480) |
49% | 210 (140-280) |
37% | 180 (90-260) |
52% |
| Review prior CPS recordsf | 650 (550-760) |
87% | 380 (300-470) |
67% | 290 (180-200) |
86% |
| a X2=20.75, p<.01 b X2=21.28, p<.01 c X2=20.1, p<.01 d X2=62.4, p<.001 e X2=25.66, p<.001 f X2=18.65, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
In terms of standard use of various instruments or tools during the alternative response, other patterns emerged. State-administered agencies were less likely to always use formal safety assessment instruments (16%) and formal risk assessment instruments (22%) than agencies in county-administered systems (35% and 43% respectively) or agencies in State-administered systems with strong county structure (31% and 27% respectively), (Table 7-24). At the same time, State-administered agencies were more likely to always use standardized domestic violence assessment instruments (18%) compared to county-administered agencies (4%) or agencies in State-administered systems with strong county structure (8%).
| Instruments and tools | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I. ) |
Percent | |
| Formal safety assessment instrumenta | 120 (60-180) |
16% | 200 (130-270) |
35% | 100 (30-180) |
31% |
| Formal risk assessment instrumentb | 170 (110-230) |
22% | 240 (180-310) |
43% | 90 (20-160) |
27% |
| Standardized domestic violence assessment instrumentc | 130 (60-210) |
18% | 20 (0-40) |
4% | 30 (0-70) |
8% |
| a X2=17.01, p<.01 b X2=15.96, p<.01 c X2=11.96, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Access to professional resources during the alternative response also varied depending on the agency's administrative structure. For example, agencies in State-administered systems with strong county structure were more likely (75%) to always have child advocacy centers available compared to State administered agencies (55%) or county-administered systems (38%). For one professional resource, both State-administered agencies (48%) and agencies in State-administered systems with strong county structure (42%) were more likely (48%) to always have citizen CPS review teams available compared to agencies in county-administered systems (30%), (Table 7-25).
| Assistance | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Child Advocacy Centera | 410 (300-530) |
55% | 220 (150-280) |
38% | 250 (130-380) |
75% |
| Citizen CPS Review Teamb | 360 (250-430) |
48% | 170 (110-230) |
30% | 140 (60-220) |
42% |
| a X2=13.76, p<.01 b X2=10.0, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Discussion
When different types of administrative structures were compared, agencies in State-administered systems with strong county structure emerged as different from the other types of agencies in certain practices or approaches used during investigations and alternative responses.
Agencies in State-administered systems with strong county structure had more expansive and flexible investigations than other agencies. These agencies were more likely to always extend the investigation response to all children in the household and to include certain activities, such as discussing the case with a multidisciplinary team, as part of the investigation. These agencies also faced fewer obstacles to timely completion of the investigation. Agencies in State-administered systems with strong county structure rarely reported obstacles like preparing materials for the case or court record and handling language barriers.
In terms of the alternative response function, agencies in State-administered systems with strong county structure appeared more consistent in how they conducted the response than the other types of agencies. These agencies had more required practices to perform before completing the alternative response. For example, CPS agencies in State-administered systems with strong county structure were more often required to assess family needs, assess the underlying causes of maltreatment, and refer the family for further services before completing the response than the other kinds of agencies. Likewise, these agencies were more likely to routinely conduct procedures such as notifying the perpetrator of the determination and entering the perpetrator information into the Central Registry than other agencies. Agencies in State-administered systems with strong county structure also more often discussed the response with a multidisciplinary team, conducted family group conference meetings, interviewed family members, and interviewed the reporter during the course of the alternative response.
For the alternative response function, county-administered agencies stood out in two ways. First, county-administered agencies were more likely to routinely use formal safety and risk assessment instruments as part of the alternative response when compared to the other agencies. In addition, these agencies were less likely to have access to certain professional resources such as Child Advocacy Centers or citizen CPS review teams during the alternative response.
7.4 Role of Law Enforcement and Other Agencies
Further analyses of the role of law enforcement and other agencies examined differences in agencies' patterns of survey responses depending on their administrative structure. This section shows how responsibility sharing differed by function, type of maltreatment, and type of perpetrator depending on the CPS administrative structure.
Responsibility for CPS Functions
The supplemental analyses found several differences in responsibility for CPS functions related to the agency's administrative structure. In terms of the overall level of responsibility for the screening function, more agencies in State-administered systems (52%) and county-administered systems (55%) had lead responsibility for screening/intake of all types of maltreatment than did agencies in State-administered systems with strong county structure (37%). At the same time, it was more common for agencies in State-administered systems with strong county structure (48%) to have varied levels of responsibility depending on the type of maltreatment than it was for agencies in State-administered systems (19%) or county-administered systems (34%), (Table 7-26).
| Level of responsibility | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Lead for all types of maltreatment | 570 (410-730) |
52% | 530 (430-620) |
55% | 200 (90-310) |
37% |
| Share for all types of maltreatment | 200 (110-290) |
18% | 80 (40-130) |
9% | 70 (0-140) |
12% |
| Support for all types of maltreatment | 30 (0-70) |
3% | 10 (0-30) |
1% | 10 (0-30) |
2% |
| No responsibility | 30 (0-70) |
3% | 10 (0-20) |
1% | --- | --- |
| Other (lead some, support some, share some) | 210 (130-290) |
19% | 320
(240-410) |
34% | 260
(150-370) |
48% |
| Missing | 50 (10-100) |
5% | 10 (0-20) |
1% | 10 (0-30) |
2% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| * X2=18.53, p<.01 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
For the investigation function, a greater proportion of agencies in State-administered systems had lead responsibility for all types of maltreatment (25%) compared to agencies in county-administered systems (15%) and State-administered systems with strong county structure (5%), (Table 7-27).
| Responsibility | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Lead for all types of maltreatment | 280 (190-370) |
25% | 140 (70-210) |
15% | 30 (0-70) |
5% |
| Share for all types of maltreatment | 130 (70-190) |
12% | 50 (10-100) |
6% | 30 (0-80) |
6% |
| Support for all types of maltreatment | 20 (0-40) |
2% | --- | --- | --- | --- |
| Other (lead some, support some, share some) | 660 (520-790) |
60% | 770 (700-840) |
80% | 490 (300-670) |
89% |
| Missing | 10 (0-30) |
1% | --- | --- | --- | --- |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| Note: Numbers in italics are based on 10 or fewer agencies. * X2=32.05, p<.001 |
||||||
Responsibility for Different Types of Maltreatment
Two patterns related to administrative structure emerged when examining CPS agency responsibility for investigations for different types of maltreatment. For certain more serious types of maltreatment, it was considerably less common for agencies in State-administered systems with strong county structure to have lead responsibility compared to agencies in State-administered or county-administered systems. For example, a smaller proportion of agencies in State-administered systems with strong county structure (9%) had lead responsibility for investigating severe physical abuse than did agencies in State-administered systems (33%) or county-administered systems (20%), (Table 7-28). The same pattern emerged for severe and moderate sexual abuse, for child fatalities, for severe and moderate emotional maltreatment, and for risk of emotional maltreatment. For these types of maltreatment, fewer agencies in State-administered systems with strong county had lead responsibility than State- or county-administered agencies.
| Type of maltreatment | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Severe physical abusea | 360 (250-470) |
33% | 190 (120-270) |
20% | 50 (0-90) |
9% |
| Severe sexual abuseb | 300 (200-400) |
28% | 140 (70-200) |
15% | 40 (0-80) |
7% |
| Moderate sexual abusec | 340 (240-440) |
31% | 170 (100-250) |
18% | 50 (0-90) |
9% |
| Severe emotional maltreatmenth | 770 (610-930) |
70% | 740 (650-930) |
77% | 300 (190-420) |
56% |
| Moderate emotional maltreatmenti | 770 (630-900) |
70% | 780 (700-870) |
81% | 360 (210-520) |
66% |
| At risk of emotional maltreatmentj | 750 (610-900) |
69% | 660 (780-740) |
69% | 330 (180-480) |
60% |
| Child fatalityd | 220 (120-320) |
20% | 80 (40-120) |
9% | 20 (0-60) |
3% |
| At risk of physical abusee | 840 (670-1,000) |
76% | 680 (600-760) |
70% | 460 (280-650) |
84% |
| At risk of neglectf | 800 (650-940) |
73% | 690 (600-760) |
72% | 400 (240-590) |
76% |
| Status offenseg | 60 (10-120) |
6% | 80 (40-110) |
8% | 90 (20-170) |
17% |
| a X2=27.59, p<.001 b X2=30.54, p<.001 c X2=20.75, p<.01 d X2=21.96, p<.01 e X2=21.07, p<.01 f X2=19.43, p<.05 g X2=20.84, p<.01 h X2=28.04, p<.001 I X2=25.41, p<.01 j X2=17.0, p<.05 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
For other less serious types of maltreatment, agencies operating under State-administered systems with strong county structure more often had lead responsibility. A greater proportion of agencies in State-administered systems with strong county structure had lead responsibility for children at risk for physical abuse (84%), risk of neglect (76%), and status offenses (17%) compared to agencies in State-administered systems (76%, 73%, 6%, respectively) and county-administered systems (70%, 72%, 8%, respectively), (Table 7-28).
The analyses also revealed differences in how CPS agencies shared lead responsibility with law enforcement for different types of maltreatment (Table 7-29). While nearly two-thirds (64%) of CPS agencies in State-administered systems shared lead responsibility with law enforcement for physical abuse, the percentages were even higher for CPS agencies with other administrative structures. Seventy-four percent of CPS agencies in county-administered systems and 84 percent of CPS agencies in State-administered systems with strong county structure shared lead responsibility with law enforcement when the allegation involved physical abuse. A similar pattern is seen for sexual abuse, with fewer agencies in State-administered systems sharing lead responsibility with law enforcement (62%) and more agencies in county-administered systems (74%) and in State-administered systems with strong county structure (78%) doing so. The differences by administrative structure are even more pronounced for neglect. Fewer than one-half (49%) of CPS agencies in State-administered systems shared lead responsibility with law enforcement for neglect. This compares to 59 percent of CPS agencies in county-administered systems and 74 percent of agencies in State-administered systems with strong county structure.
| Type of maltreatment | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Physical abusea | 700 (580-820) |
64% | 710 (640-790) |
74% | 460 (280-650) |
84% |
| Sexual abuseb | 680 (560-800) |
62% | 710 (630-790) |
74% | 430 (250-600) |
78% |
| Neglectc | 530 (430-630) |
49% | 570 (490-660) |
59% | 410 (240-570) |
74% |
| a X2=9.65, p<.001 b X2=6.06, p<.05 c X2=9.16, p<.01 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Responsibility for Different Types of Perpetrators
The supplemental analyses found administrative structure differences in agency responsibility for different types of perpetrators. Agencies in State-administered systems with strong county structure were less likely to have lead responsibility when perpetrators were facility personnel, but the reverse was true if the perpetrator was a noncaregiver (Table 7-30). Specifically, agencies in State-administered systems (30%) and county-administered systems (21%) more often had lead responsibility when the maltreatment was perpetrated by a staff person at a group home or institution than did agencies in State-administered systems with strong county structure (14%). When the perpetrator was not a caregiver, a higher proportion of agencies in State-administered systems with strong county structure (16%) had lead responsibility compared to both State-administered agencies (1%) and county-administered agencies (10%).
| Type of perpetrator | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Group home or institution staffa | 330 (230-440) |
30% | 200 (130-270) |
21% | 80 (10-140) |
14% |
| Noncaregiverb | 10 (0-30) |
1% | 100 (50-140) |
10% | 90 (20-150) |
16% |
| a X2=33.26, p<.001 b X2=21.55, p<.001 Note: Percentages are not additive because agencies were included in each applicable row (category). Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Differences by administrative structure in the role of law enforcement emerged for one type of perpetrator. Four percent of agencies in State-administered systems and 14 percent of agencies in county-administered systems shared responsibility with law enforcement for noncaregiver perpetrators (Table 7-31). Nearly one-third (31%) of agencies in State-administered systems with strong county structure shared lead responsibility with law enforcement for maltreatment by noncaregivers.
| Lead responsibility | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Share for noncaregiver perpetrators | 40 (10-70) |
4% | 140 (90-180) |
14% | 170 (80-260) |
31% |
| Do not share for noncaregiver perpetrators | 1,060 (940-1,180) |
96% | 830 (750-900) |
86% | 380 (210-550) |
69% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| a X2=12.37, p<.001 Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
There was also one notable difference by administrative structure in how CPS agencies shared lead responsibility with other, nonlaw enforcement agencies for different types of perpetrators. CPS agencies were more likely to share lead responsibility with other agencies for maltreatment perpetrated by staff at a group home or institution when their system was county-administered (33%) compared to agencies in State-administered systems (19%) or State-administered with strong county structure (10%), (Table 7-32).
h scope="COL">Percent
| Lead responsibility | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
||
| Share for institutional perpetrators | 200 (120-290) |
19% | 320 (250-390) |
33% | 60 (0-110) |
10% |
| Do not share for institutional perpetrators | 890 (750-1,030) |
81% | 640 (540-740) |
67% | 490 (300-680) |
90% |
| Total | 1,100 (970-1,220) |
100% | 960 (890-1,030) |
100% | 550 (350-750) |
100% |
| a X2=14.34, p<.001 Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Discussion
These analyses examined differences related to administration structure in the role of CPS agencies in performing the traditional CPS functions. Overall, agencies in State-administered systems with strong county structure had lead responsibility for screening and investigation less often than the other types of agencies. For both functions, these agencies were more likely to have varied levels of responsibility depending on the type of maltreatment.
This same pattern held true when looking at agency responsibility for investigations by maltreatment type. For many of the more serious types of maltreatment, State- and county-administered agencies had lead responsibility much more often than agencies in State-administered systems with strong county structure. For example, State- and county-administered agencies had lead responsibility for investigations of severe physical abuse, severe sexual abuse, moderate sexual abuse, and child fatalities more often than did agencies in State-administered systems with strong county structure.
The role of law enforcement in responding to different types of maltreatment also depended on the agency's administrative structure. For certain types of maltreatment, State-administered agencies with strong county structure shared lead responsibility with law enforcement more often than State- or county-administered agencies. For example, these agencies more often shared lead responsibility with law enforcement for allegations of physical abuse, sexual abuse, and neglect.
When examining the level of responsibility for investigation for different types of perpetrators, two different patterns emerged. State-administered agencies more often had lead responsibility for institutional perpetrators, while State-administered agencies with strong county structure more often had lead responsibility for investigations for noncaregiver perpetrators.
Finally, a few differences by administrative structure emerged when examining the involvement of other agencies for different types of perpetrators. When the perpetrator was a noncaregiver, agencies in State-administered systems with strong county structure shared lead responsibility with law enforcement much more often than did other agencies. Agencies in county-administered systems were more likely to share lead responsibility with other, nonlaw enforcement agencies when the perpetrator was a staff person at a group home or institution than were other agencies.
7.5 New Directions
Differences in the patterns of implemented change or considered change by administrative structure were also examined.
Degree of Change in CPS Agencies
State- and county-administered agencies had less stable processes than agencies in State-administered systems with strong county structure in terms of the investigation and alternative response functions (Table 7-33). For more than one-quarter (29%) of CPS agencies in State-administered systems and 21 percent of agencies in county-administered systems, the investigative process had been in place for just 1 to 2 years. Agencies in State-administered systems with strong county structure had more longstanding investigative processes, as just 9 percent of these agencies reported that their investigative process had been in place for 1 to 2 years. Instead, for 43 percent of CPS agencies in State-administered systems with strong county structure their investigative process had been in place 5 to 10 years.
A similar pattern is seen for the alternative response function. The alternative response process had been in place for 1 to 2 years for higher percentages of agencies in State-administered (18%) and county-administered systems (21%), compared to just 8 percent of agencies in State-administered systems with strong county structure. Moreover, the alternative response process had been in place for 5 to 10 years for one-half of agencies in this latter group.
| Process | State-administered | County -administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Investigation processa | ||||||
| Process in place 1-2 years | 320 (220-420) |
29% | 210 (140-280) |
21% | 50 (0-100) |
9% |
| Process in place 3-4 years | 80 (20-140) |
7% | 200 (130-270) |
21% | 110 (30-190) |
21% |
| Process in place 5-10 years | 270 (180-350) |
24% | 370 (280-450) |
38% | 240 (130-240) |
43% |
| Process in place more than 10 years | 250 (130-270) |
23% | 110 (70-160) |
12% | 30 (0-70) |
5% |
| Missing | 180 (100-250) |
16% | 80 (40-120) |
8% | 120 (40-200) |
22% |
| Total | 1,100 | 100% | 960 | 100% | 550 | 100% |
| Alternative response processb | ||||||
| Process in place 1-2 years | 140 (70-210) |
18% | 120 (80-160) |
21% | 30 (0-70) |
8% |
| Process in place 3-4 years | 70 (30-110) |
9% | 110 (70-160) |
20% | 40 (0-80) |
11% |
| Process in place 5-10 years | 230 (150-300) |
30% | 200 (140-250) |
35% | 170 (80-260) |
50% |
| Process in place more than 10 years | 230 (120-330) |
30% | 60 (20-110) |
11% | 20 (0-60) |
6% |
| Missing | 100 (40-150) |
13% | 70 (40-110) |
13% | 90 (20-150) |
25% |
| Total | 760 | 100% | 570 | 100% | 340 | 100% |
| a X2=22.59, p<.001 (excludes missing) b X2=15.16, p<.01 (excludes missing) Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Types of Changes in CPS Agencies
The recent implementation of some specific changes differed depending on the administrative structure of the agencies (Table 7-34). In terms of changes related to staff training, it was more common for agencies in State-administered systems (35%) to report implementing changes in the last 6 months than it was for agencies in county-administered systems (19%) or for agencies in State-administered systems with strong county structure (23%).
Some implemented changes were more common among county-administered agencies. For example, agencies in county-administered systems (9%) had implemented more changes during screening in the amount of interaction with reporter and collaterals than had agencies in either State-administered systems (3%) or State-administered systems with strong county structure (3%). Likewise, it was more common for agencies in county-administered systems (14%) to have implemented changes in the use of multidisciplinary teams than it was for agencies in either State-administered systems (7%) or State-administered systems with strong county structure (5%).
| Change implemented | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Staff traininga | 380 (260-510) |
35% | 190 (130-250) |
19% | 130 (50-210) |
23% |
| Amount of interaction with reporter and collateralsa | 30 (0-60) |
3% | 90 (40-130) |
9% | 20 (0-40) |
3% |
| Use of multidisciplinary teams during the investigationc | 80 (21-140) |
7% | 140 (90-180) |
14% | 30 (0-70) |
5% |
| a X2=6.94, p<.05 a X2=6.22, p<.05 a X2=6.75, p<.05 Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Differences depending on administrative structure also emerged for a few of the changes that agencies had considered during the preceding 6 months (Table 7-35). Agencies in county-administered systems (19%) were more likely to have considered changes during the past 6 months related to screening/intake responses options than were State-administered agencies (11%) or agencies in State-administered systems with strong county structure (2%). The same pattern emerged for changes related to the processing of referrals, the amount of interaction with family and/or child during the investigation, and the use of multidisciplinary teams during the investigation response. More county-administered agencies had considered changes in each of these areas when compared to either State-administered agencies or agencies in State-administered systems with strong county structure.
| Change considered | State-administered | County-administered | State-administered with strong county structure | |||
|---|---|---|---|---|---|---|
| Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | Estimate (C.I.) |
Percent | |
| Screening/intake response optionsc | 120 (50-190) |
11% | 180 (120-240) |
19% | 10 (0-30) |
2% |
| Processing of referralsd | 100 (30-170) |
9% | 120 (80-160) |
13% | <10 (0-10) |
1% |
| Amount of interaction with family and/or child during the investigatione | 60 (20-90) |
5% | 110 (60-160) |
12% | 10 (0-30) |
2% |
| Use of multidisciplinary teams during the investigationf | 30 (0-70) |
3% | 110 (60-150) |
11% | 30 (0-70) |
6% |
| Agency requirements for staff qualificationsa | 150 (70-230) |
14% | 50 (10-90) |
5% | 200 (100-300) |
36% |
| Information technologyb | 320 (220-430) |
30% | 170 (120-220) |
18% | 50 (0-100) |
9% |
| a X2=14.16, p<.001 b X2=9.49, p<.01 c X2=11.59, p<.01 d X2=7.99, p<.05 e X2=9.11, p<.01 f X2=6.11, p<.05 Note: Numbers in italics are based on 10 or fewer agencies. |
||||||
Different patterns emerged when examining some other changes. Agencies operating under State-administered systems (14%) or county-administered systems (5%) were much less likely to have considered changes during the last 6 months in the agency requirements for staff qualifications compared to agencies operating under State-administered systems with strong county structure (36%). Finally, 30 percent of agencies in State-administered systems indicated that they had considered changes related to information technology. The corresponding percentage for agencies in county-administered systems was 18 percent. Just 9 percent of agencies in State-administered systems with strong county structure had considered changes in information technology.
Discussion
Some interesting differences emerged when the types of reforms were examined from the perspective of administrative structure. Agencies in county-administered systems appeared to focus on efforts related to client and community interactions. For example, more county-administered agencies were considering changes related to amount of interaction with reporter and collaterals during screening and the amount of interaction with the family or the children during an investigation. Further, county-administered agencies had implemented more changes related to use of multidisciplinary teams during the investigation response than had either type of State-administered agency. In contrast, State-administered agencies and State-administered agencies with strong county structure more often considered changes in information technology and staff training.
Endnotes
1 The report, Review of State CPS Policy, of the National Study of Child Protective Services Systems and Reform Efforts, is available on the Internet site for the Office of the Assistant Secretary for Planning and Evaluation (ASPE) at http://aspe.hhs.gov/hsp/CPS-status03. Posted: 2003.
2 T = 2.391, p < 0.05
3 T = -3.867, p < 0.001
Chapter 8. Examples of Change Based on Site Visits to Local Agencies
The National Study also conducted site visits to eight local CPS agencies. The purpose of the site visits was to discuss in greater detail the types of reforms that had been implemented in the local agencies. This chapter summarizes the thethe practice innovations and reform efforts that had been undertaken in the sites.
The site visit reports are not representative of all changes being undertaken throughout the country. They describe how change has been undertaken by a select number of local CPS agencies. In some locations the changes and reforms were more systemic than in others, but in all sites, many types of change have been undertaken with the intent of improving the management and provision of CPS. The site visits were not evaluative; however, many of the changes have been found to be beneficial by the local agency staff and the community.
8.1 Site Selection and Site Visit Methods
Sites were identified for visits based on their response to the Local Agency Survey (LAS) in which they indicated whether they had implemented significant changes within the prior months. Of those responding, 81 percent said they had implemented one or more changes. The number of changes ranged from 1 to 15 per site. Sites were assigned a "change weight score" by computing the product of the total number of changes and the number of functional areas with a change. This score represented both the number of changes in an agency and the breadth of the changes. The sites with the largest change scores were considered eligible for visits. Since a further selection criterion was that only one site would be visited in each State, the site with the highest score from a State was selected, and the others were dropped from the list. Of the 11 sites selected by this method, 3 could not participate due to scheduling or other types of conflicts.
Eight site visits were made to localities ranging from suburban communities to rural communities. Three of the sites were in county-administered child welfare systems; five of the sites were in State-administered child welfare systems. The sites were:
- Brooks County Department of Family and Children Services (DFCS), Brooks County, Georgia;
- Butler County Children and Youth Agency, Butler County, Pennsylvania;
- Catawba County Department of Social Services (DSS), Catawba County, North Carolina;
- Children Youth and Family Division (CYFD), Fairfax County Department of Family Services, Fairfax County, Virginia;
- La Crosse Human Services Department (LCHSD), La Crosse County, Wisconsin;
- Children and Family Services Department (CFS), Ventura County Human Services Agency (HSA), Ventura County, California;
- District 3 Department of Children and Families (DCF), Union County, Florida; and
- Western Region of the Division of Children and Family Services (DCFS), Utah County, Utah.
The objective of the site visits was to gain a deeper understanding of the changes in CPS practice being undertaken. Activities included interviewing key stakeholders in the CPS system and obtaining documentation of the reform efforts underway. Sites were asked specifically to discuss the changes that had been indicated in their LAS response and to identify any other changes that were related to conducting CPS. Interviews were held with individuals and focus groups. The interviews were focused on CPS rather than on the broader sphere of child welfare responsibilities. The following areas of change were discussed:
- Organization and administration of CPS;
- Investigation and assessment functions;
- Improvements in working with families;
- Community collaborations;
- Attention to domestic violence;
- Addressing substance abuse; and
- Accountability.
8.2 Organizational and Administrative Changes
Several of the site visits provided detailed information on changes related to philosophy of service, organizational and functional structuring of work, training, and staffing. Some of these changes have affected the operations of the entire agency, while others have had more limited impact.
Many agencies reported having undertaken broad-based changes in their philosophy of service. For example, agencies in Fairfax County, Utah County, and Ventura County implemented changes in the overall philosophy of their programs to emphasize the provision of family-focused and family-friendly approaches to services.
Specific changes in the screening function were noted by the agency in Ventura County, which had contracted with a private agency to conduct screening. In La Crosse County, paraprofessional screeners received primary referral information; casework supervisors reviewed the information and made the decision to investigate or not. Staff in Butler County also addressed screening by implementing a specialized unit in order to improve the consistency of screening decisions rather than having this function performed by the staff who also conducted investigations.
Additional specialization of functions was reported by agencies in Butler County and Union County. In Butler County, a single, dedicated investigator handled all sexual abuse cases, which was thought to be critical because of the special expertise needed for these types of cases. The dedicated investigator also became part of a joint police and CPS investigative team. Similarly, the agency in Union County recently separated its generic CPS units into investigative and ongoing services units.
Other types of specialized staffing changes included those undertaken by the agencies in Catawba County, Ventura County, and Fairfax County. The agency in Catawba County created a half-time position for a family group conferencing coordinator; the agency in Ventura County reformulated its use of public health nurses who were part of the investigation units to re-emphasize their role as nurses rather than acting as if they were CPS investigators. Fairfax County planned to create a child custody intervention team to reduce the amount of time spent on allegations that were actually part of child custody cases.
In some sites, there was a different direction for change. The agency in Fairfax County integrated investigation and ongoing support functions. Staff members served on a team to improve continuity between intake and ongoing services. Further, these combined services units were moved out into satellite offices in order to be in a better position to meet community and family needs. Similarly, the agency in La Crosse County decided to make all CPS workers generic workers, and workers would share responsibility for intake, investigation, and case management.
Many agencies commented on the need for new training for workers as change has been implemented.
8.3 Investigation and Assessment Functions
The response to an allegation of abuse and neglect has always been the responsibility of CPS. Two major directions of change were noted in the site visits, as well as a number of additional changes. These involved the role of law enforcement in investigations and the creation of an alternative response to investigation.
Joint CPS and Law Enforcement Investigations
Law enforcement, whether police departments, sheriff offices, or the District Attorney's office, has long had a role in collecting evidence to prosecute perpetrators and, in some jurisdictions, in reaching decisions about removal of children from the home. As the evidentiary requirements have grown, CPS practitioners have found the need to clarify roles and reduce duplication of responsibilities in order that the roles of the social services agencies and the law enforcement agencies can be complementary rather than competitive. Some jurisdictions have moved to joint CPS and law enforcement investigations to allow social workers to spend less time on investigation and more time on establishing a relationship with the nonoffending caretaker and the rest of the family.
In Brooks County, the District Attorney's office, three law enforcement agencies, CPS, and numerous other agencies worked together to revise the interagency child abuse protocol, which clarified the role of CPS workers and law enforcement and established a multidisciplinary team for case review. Some of the results, according to those interviewed, included better decisionmaking by caseworkers about how to proceed on a case and reduced revictimization of children. The agency in Butler County also established protocols for joint police and CPS investigations, which clarified roles and responsibilities. The agency in Catawba County went further and co-located law enforcement and CPS staff in an effort to ensure ongoing cooperation in cases of child sexual abuse and extreme physical abuse.
Whenever serious physical abuse, sexual abuse, or a child fatality was alleged in Union County, law enforcement personnel from the sheriff's office accompanied caseworkers from the Department of Children and Families (DCF) to investigate. Even when law enforcement and DCF were not conducting joint investigations, information was shared. For example, if the county sheriff determined that a child was not in "serious" danger, the DCF investigator would conduct the investigation and submit a report to the sheriff's office. The sheriff's office would rely on the DCF worker's judgment. DCF workers stated that joint investigations ensured the protection of endangered children and the safety of the worker.
Alternative Response
The diversification of responses to an allegation of maltreatment is a trend that is gaining attention throughout the country. In one site, this practice was a recent innovation. The agency in Fairfax County recently implemented a Differential Response System (DRS). In this system, when a child was found not to be in immediate danger, a family assessment would be used to identify family needs and provide immediate services built on family strengths. Under the DRS, reports alleging child abuse or neglect were assessed to determine whether they deserved an investigation or family assessment response. Family assessment responses differed from investigations in that they did not require a determination of maltreatment or the same level of due process procedures, and were not recorded on the State Central Registry.
Additional Changes
Several sites reported that they had implemented the use of safety or risk assessment tools to assist workers in assessing immediate danger to the child. Staff in La Crosse County specifically described the implementation of new safety and risk assessment procedures. The use of multidisciplinary teams — often an outgrowth of joint police and CPS investigations — was also observed in Brooks County.
8.4 Changes in Working with Families
Some agencies have chosen to implement family-centered service philosophies. Such approaches result in practice that seeks to empower families and help them recognize and build on their strengths. Caseworkers make efforts to meet extended family members and make families partners in permanency planning. Several sites had implemented some form of family conferencing or family group decisionmaking.
Staff in Catawba County used two family group conferencing models to facilitate planning and decisions about a range of family needs to address child safety. Staff in Fairfax County used family assessments to engage families in cooperative efforts to find solutions to the problems for which they were reported. The family decisionmaking process in Ventura County brought families, friends, and service providers to work together to make decisions that will ensure the safety and well-being of the children. Staff in Utah County worked to engage families and build on their strengths through many family-oriented practices.
8.5 Community Collaborations
Community partnerships to serve families in which the child has been or is at risk of being abused or neglected have resulted from the development of a range of cooperative service arrangements. Many efforts are underway to include a wide range of service providers in meeting the needs of children and families.
One-half of the sites had established some type of community partnership to serve children and families. In Butler County the Community Service Review Team included approximately 25 people who reviewed difficult cases on a monthly basis and helped to provide a continuum of services. A Family and Children's Collaborative was developed in La Crosse County, which was exploring the development of a group to deal with case management and coordination among all service providers.
Two sites discussed improved relationships with the courts as a result of the involvement of a Guardian Ad Litum (GAL) for each child. GALs were hired in Butler County as staff to advocate for the best interests of the child before meeting the child in court. In Union County, the court appointed a volunteer GAL when the dependency case came to court. While not part of the agency, the GAL had contact with the child once each month and would attend all agency staffing meetings, court events, and mediation sessions.
The agency in Union County has been significantly affected by statewide initiatives to privatize services. Many service providers have become involved. The Nurturing Program, which provided parenting education and intensive home visits, was for low-risk families. In addition, other programs provided targeted mental health services and behavioral health care, including substance abuse programs and psychological assessments.
In Ventura County, extensive collaboration was also underway. One contractual organization was providing screening services and other services to children and families, such as child abuse intervention and prevention, family life education, family support, and court appointed special advocates. The human services agency was also implementing a support group program to provide direct feedback regarding agency programs and operations from current and former clients.
The Fairfax County agency made extensive efforts to involve community residents in solving problems of children and families. After relocating regionally throughout the county, multi-agency teams discussed community outreach and began to develop connections with other agencies, community groups, and residents.
8.6 Attention to Domestic Violence
One-half of the sites worked with domestic violence programs, reflecting widespread interest in improving the coordination of CPS in domestic violence situations.
In Brooks County, workers from DFCS would accompany police on domestic violence investigations since Georgia has defined witnessing violence as a form of child abuse. By increasing the coordination with the local victims assistance program in serving children, it was reported that more CPS staff time would be available to work on other cases.
In Catawba County, if domestic violence appeared to be a factor, the CPS worker would develop safety plans for both the victim and the child. This included referring them to "First Step," which provided shelter and treatment. If, however, the risk to the child was high and the parent could not or would not cooperate, or if the situation was not improved after 6 months of services, the Department would file a petition requesting custody of the child.
The agency in Union County had an interagency agreement with a local domestic violence program, through which there was a mutual commitment to share information and clients, as necessary, to protect children and the nonoffending parent.
The agency in La Crosse County initiated a process to improve cooperation between CPS and domestic violence programs. A workgroup developed a document recommending the creation of training for domestic violence staff on the CPS system; development of a memorandum of understanding between the two agencies; and revisionsand revisions to CPS investigation standards.
8.7 Addressing Substance Abuse
The impact upon children of substance abusing parents has been documented. 1 Because of this concern, some sites discussed changes that they were undertaking, particularly in working with Drug Courts...
In Ventura County, the Drug Court provided mothers and infants identified with positive toxicology prenatally or at birth with an average of 6 months inpatient treatment and supervision to help them maintain their families without the need for placement. The residential settings were facilities that supported both the mother and her infant. This process has been monitored intensively by the court, and the child would be placed if the mother was unable to complete the program successfully. In addition, an interagency case management council met weekly to assure that children and families received services to prevent removal or to speed reunification.
A Drug Dependency Court program was being used in Union County when a dependency petition had been filed when the caregiver was a substance abuser. The initial, intensive stage of the program took 90 to 120 days and required participation of a minimum of 4 times per day, 4 times per week in treatment groups, and drug testing. In addition to the substance abuse treatment, parents could attend parenting classes, anger management, and other services. The court maintained vigilant supervision of the caregiver's progress towards sobriety. Thus if the caregiver was not compliant or did not make progress, it was likely that parental rights would be terminated more quickly.
8.8 Accountability
In concert with the trend towards improving family relations with the CPS agency and extending CPS into the community, there was some evidence of increased attention to accountability. The increased attention to performance by local, State, and Federal agencies contributed to this trend.
Florida has instituted numerous reporting and practice requirements which were designed to increase accountability. In addition, the Department of Children and Families instituted tested a computerized case record system, which included case-level information for all reports of maltreatment. In Union County, caseworkers and supervisors could review the status of any case in the system. The system also allowed documentation of actions taken by other service providers who would be held accountable if they did not provide needed services in a timely way.
California implemented its Statewide Automated Child Welfare Information System within the past 3 years. The Ventura County agency — through its collaboration with the county's information technology department — prepared monthly management performance reports and responded to the needs of management for other data. These reports have become a part of the monitoring process the County uses to monitor specific performance goals such as reducing the numbers of reports that are screened out.
8.9 Summary of Reform Trends
Site visits to local jurisdictions that were reforming their CPS systems identified several trends. Table 8-1 provides a graphic summary of the main areas of change.
| County | Organizational and Administrative | Joint CPS and Law Enforcement Investigations | Alternative Response and Other Approaches | Changes in Working with Families | Community Collaborations | Attention to Domestic Violence | Addressing Substance Abuse |
|---|---|---|---|---|---|---|---|
| Brooks, GA | ü | ü | ü | ||||
| Butler, PA | ü | ü | ü | ü | |||
| Catawba, NC | ü | ü | ü | ||||
| Fairfax, VA | ü | ü | ü | ü | |||
| La Crosse, WI | ü | ü | ü | ü | |||
| Ventura, CA | ü | ü | ü | ü | |||
| Union, FL | ü | ü | ü | ü | ü | ||
| Utah, UT | ü | ü |
Understanding the impact of such changes on outcomes will require further evaluation. Many of the innovations are too new to be evaluated; some have not been evaluated for other reasons. In instances where changes are in different directions, it would be useful to have more systemic analysis of the impact of such reforms. For example, the relative merits of specialized versus generic staff providing CPS functions have been debated among CPS practitioners and managers since the inception of CPS, but have not been seriously evaluated.
It is possible, however, to identify some impacts on the child welfare organization. The agency in Ventura County reduced turnover of line staff from 20 percent to 4 percent over a 2-year period. Those interviewed attributed this to better pay, ongoing training, support for workers in providing input to management, alternative work schedules, opportunities for advancement, and other factors.
Training and cross-training, when collaborations are involved, were reported to help sustain reform efforts because training helped staff to understand their roles and responsibilities, as well as the goals of the reform efforts. Better pay was also cited as an assist in sustaining change — although it is not clear that it is sufficient without additional training. Ongoing support for workers was also reported to boost staff morale and commitment.
States and localities are motivated by several issues to reform CPS. States and localities are also being held more accountable for the interests of the community and for achieving desired outcomes for children. At the same time, the number of referrals alleging child maltreatment requiring a response by the local agency continues at a high level. Thus agencies are looking for ways in which to improve the efficiency and the effectiveness of their responses to the needs of children and their families.
Endnote
1 U. S. Department of Health and Human Services. (April 1999). Blending Perspectives and Building Common Ground: A Report to Congress on Substance Abuse and Child Protection. Washington, D.C.: Author.
Chapter 9. Conclusions
The Local Agency Survey (LAS) component of the National Study of Child Protective Services Systems and Reform Efforts provided a unique national perspective on CPS agency processes. The survey represented a pioneering effort in the field, as it was the first to gather information from a nationally representative sample of local CPS agencies about different aspects of how the agencies work. Despite a challenging research environment where many CPS agencies were being asked to participate in other concurrent Federally-sponsored initiatives, the study's data collection methodology achieved a high response rate.
9.1 Functions and Roles of CPS Agencies
A primary goal of the LAS was to gain a better understanding of the functions performed by CPS agencies. The findings revealed that almost all of the estimated 2,610 local CPS agencies in the nation performed screening and all of them conducted investigations. Two-thirds of CPS agencies also were estimated to perform some type of alternative response as part of their work. Alternative response was defined as a function of the agency that assesses the needs of the child or family without requiring a determination that maltreatment has occurred and/or that the child is at risk of maltreatment. However, agencies indicated that this definition was not the critical distinguishing characteristic of these alternative responses. Rather, two-thirds of agencies make a distinction among responses based on the type and severity of the alleged maltreatment.
Nationally, local agencies were responsible for screening of child abuse or neglect referrals for almost all children and were responsible for investigating child abuse or neglect for all children. However, just over one-half of children lived in jurisdictions served by agencies with alternative CPS responses. The difference between the percentage of agencies offering alternative responses (two-thirds) and the percentage of children under the jurisdiction of such agencies (just over
one-half) suggests that alternative responses were more often used in smaller agencies. Given their size, these agencies may have been able to operate more flexibly or be case-specific in response to allegations of maltreatment.
9.2 CPS Agency Staff
Nationally, most CPS agencies were relatively small. Staff size averaged about 26 persons, with 17 of them functioning as caseworkers or social workers, 3 as supervisors, and the remainder as support staff.
Very few agencies had vacancies at the time of the survey. Agencies in State-administered systems had larger staffs compared to agencies in county-administered.
On average more than one-half of all workers employed by CPS agencies were specialized in either screening/intake or investigations. Most agencies that offer an alternative response provide this response with the same workers who provide investigations. Based on the size of the agencies with the size of the population of children residing in locales that are served by the agencies, larger agencies had more specialized staffs. These findings undoubtedly reflect the relatively small size of agencies nationwide with smaller agencies being less specialized, compared to larger agencies with a greater number of specialized staff.
In terms of workload, CPS agencies handled an average of 64 referrals per month as part of the screening/intake response and completed an average of 43 investigations per month. For those agencies providing an alternative CPS response, an average of 16 were completed each month. The majority of CPS agencies were experiencing what they considered to be excessive workloads at the time of the study. Further, approximately three-quarters of children were in jurisdictions in which the agencies had excessive workloads. While recognizing that no objective measure of workload has been made, the existence of widespread concerns regarding excessive workload is important.
CPS agencies also provided followup services to children and families as part of their responses. Almost all agencies were allowed to provide services regardless of the result of investigations, but nearly one-quarter provided services only if a report was substantiated or did not provide followup services at all. The range of potential service offerings available to most agencies was quite extensive, with educational or therapeutic services most commonly available, and financial services less commonly available.
9.3 CPS Agency Practices
Overall, there was little variation across CPS agencies with how referrals entered the agency. Most CPS agencies screened locally, as opposed to only relying on State hotlines, and typically received referrals from individuals, schools, or hotlines. CPS agencies made widespread use of on-call staff to handle calls after-business hours, on weekends, and from non-English speakers. Some agencies were not at all able to accept referrals from non-English speakers because of a lack of appropriate staff or arrangements with interpreters to handle such calls.
CPS agencies had some flexibility in the processing of referrals. Agencies had multiple response options available for both screened-in and screened-out referrals. Further, agencies that received referrals from a State hotline were not bound to follow the Hotline's response recommendation or the timeframe for completing the referral. Agency screening activities generally involved paperwork; activities that required direct contact with the child, family, or reporter were conducted less frequently. CPS agencies almost always conducted such activities as searching CPS records, while they only sometimes conducted activities involving contact with individuals such as calling or visiting the family or calling collaterals during screening.
Once a referral was screened into the agency for further action, two-thirds of CPS agencies used an alternative response in combination with investigation. More response options were available for referrals on children with an open investigation or for referrals on children in foster care than for other types of screened-in referrals. Those referrals that were screened out by the agency were often referred elsewhere, many to the police, because they involved maltreatment by third-party perpetrators.
The survey found many similarities in the approaches and practices used to conduct the responses. The majority of agencies extended both the investigation response and the alternative response to all children in the household. In making determinations at the conclusion of the investigation response, most agencies made separate determinations for each child. Moreover, CPS agencies almost universally considered factors such as severity and policy standards during the investigation response. Fewer agencies required practices under alternative response related to imminent safety issues — such as removing the child — because such cases were handled by investigations.
Agencies carried out a wide range of activities while conducting both responses. During investigations, nearly all CPS agencies interviewed the child and caregiver, reviewed previous records, and interviewed witnesses. Some activities were less frequent during investigations, such as conducting family group conferencing and criminal background checks. During the alternative response, agencies almost always talked to the child and reviewed prior records. However, they focused less on gathering forensic evidence, and they less frequently used multidisciplinary teams, interviewed witnesses, gathered physical evidence, or conducted criminal background checks.
While a majority of agencies followed guidelines for conducting assessment during the investigation response, only a minority used formal assessment tools during the investigation to gauge the extent of risk, safety, substance abuse, or domestic violence. This finding may contradict what many in the field believe to be a more widespread use of these tools during investigations. Overall, there is less use of standard instruments and tools during the alternative CPS responses.
CPS agencies had access to a broad range of specialists while conducting investigation and other responses, particularly clinicians and substance abuse specialists. The analyses also revealed that the reliance on professionals might cause a bottleneck in completing the response. Access to professionals was frequently cited as a barrier to timely completion of both responses. These findings suggest that while CPS agencies may have had access to specialists, this access could be delayed or not prompt enough to fit into the timeline for responses.
Decisionmaking practices were similar for both responses where workers made decisions with supervisory review. At the conclusion of the response, notifications to the perpetrator and reporter were more common during the investigation response compared to the alternative response. For responses not completed during the required time frame, investigations typically remained open, while alternative responses had more flexible standards for concluding the case.
9.4 Role of Law Enforcement and Other Agencies in CPS
Another important aspect of how CPS agencies operate is their involvement with other agencies in the community. The study shows that few CPS agencies had lead responsibility for the investigation and alternative response functions across all types of maltreatment. Rather, agency responsibility for these functions typically varied depending on the type of maltreatment. Further, the findings reveal a distinction between the role of law enforcement and that of other agencies in CPS work. The specific circumstance of the maltreatment also shaped the role of CPS agencies with more sharing of lead responsibility for the more serious forms of maltreatment. At the same time, across the different types of perpetrators similar percentages of CPS agencies shared lead responsibility with other agencies.
The findings also reveal a distinction between the role of law enforcement and that of other agencies. Looking at the different types of maltreatment, CPS agencies reported sharing lead responsibility with law enforcement more often than with any other type of agency. The same pattern holds true for different types of perpetrators, with more sharing of lead responsibility with law enforcement agencies. This consistent pattern highlights the unique role of law enforcement in responding to different types of maltreatment and perpetrators.
9.5 Change Efforts in CPS Agencies
Overall, most agencies reported fairly stable processes for the screening and intake, investigation, and alternative response functions with about one-fifth reporting changes during the last 2 years.
However, when asked about specific changes in different areas, agencies reported a wide variety of changes and new developments. The most frequent changes came in the area of CPS organization. These included such efforts as improvement or expansion of staff training and increased use of information technology. CPS agencies were also working to increase collaboration with a variety of community partners such as domestic violence agencies, alcohol and drug agencies, and other agencies. While somewhat less frequent, changes were also evident in the specific functional areas. A number of CPS agencies had made changes in the use of assessments or other tools during the screening/intake function, had new efforts related to the use of multidisciplinary teams during the investigation function, and changed their use of risk assessments or other tools while conducting the alternative CPS response.
9.6 Conclusion
The LAS provides a rich source of information about the processes and practices of CPS agencies. The survey's focus on the different functional areas as well as reform efforts within the agencies contributes to the overall study's ability to describe the status of the CPS system nationally and to characterize the reform efforts underway. With a unique national perspective lacking in other research efforts, the LAS findings can help both policymakers and practitioners understand how CPS agencies nationwide operate.
The LAS findings provide concrete evidence of both the commonalities and diversity of CPS practices throughout the Nation. The diversity is at the very core of CPS practice. While all CPS agencies investigated child abuse and neglect, they did not all have the same lead responsibility. To a certain degree, the more serious the type of maltreatment, the more likely they were to share the responsibility for investigating the maltreatment. This obviously requires clear lines of responsibility and collaboration in order to be effective.
Furthermore the majority of CPS agencies conceptualized their practice as having different responses for different types of maltreatment. Not only were responsibilities shared, but the responses were different. In general these responses were less focused on obtaining forensic evidence, but the clear difference was that they focused on different types of maltreatment than did investigation.
At each level of practice, the areas of common practice could be identified. A few examples follow:
- More than two-thirds of agencies always searched CPS records on prior reports on children, searched CPS records related to alleged perpetrators, and used a safety protocol when screening. All other screening activities were conducted with less commonality.
- More than two-thirds of agencies always considered the severity of the case and the policy defined standards of evidence, reviewed prior records, interviewed or formally observed children, interviewed caretakers, always notified the perpetrator, and entered the name of the perpetrator in the Central Registry, when conducting an investigation.
- More than two-thirds of agencies always reviewed prior records, interviewed children, and interviewed caretakers when conducting alternative responses. All other possible activities were less consistently practiced.
- The only instrument that was used by more than two-thirds of agencies in conducting investigations was guidance for establishing risk or safety.
These findings raise important questions for the field. Is the field strengthened or weakened by this diversity? Can agencies be held accountable to their communities and to national standards without a greater understanding of what "should be" common practice? Can families have expectations from agencies that encourage individual assessments, but have few common standards of practice?
The LAS provides data on CPS practice as it existed during 2002. It is hoped that it will assist in planning for improved CPS practices in future years.
Appendix A. Methodology
This appendix describes the methodology for the LAS, including information on sampling, instrument design, data collection, database development, weighting, and analysis.
A.1 Sampling Procedures
The sampling procedures were designed to select a nationally representative sample of counties. The analysis unit was the local CPS agency, which in the majority of cases was operated at the county level. As a comprehensive listing of CPS agencies did not exist, the county was used as the primary sampling unit and a list of all U.S. counties was the sampling frame.
The sampling process incorporated two key features of the stratified systematic random sampling approach — the stratification structure used in the sampling process and differential sampling rates for different sectors of counties.1 Stratification and differential sampling rates were designed to ensure adequate representation of counties by the different categories of CPS administrative structure (either State- or county-administered) and urbanicity (urban or rural).
The stratification variables were selected based on their assumed underlying association with CPS system characteristics. The administrative structure variable mediated the degree to which State policy affects local CPS agency operations, while the urbanicity variable addressed different operational environments and resources. In addition, a Census geographic region variable was used to sort the sampling list to ensure that the sample was spread evenly across regions. Table A-1 lists the States in each of the four census regions.
| Region | States |
|---|---|
| 1 | CT, MA, ME, NH, NJ, NY, PA, RI, VT |
| 2 | IA, IL, IN, KS, MI, MN, MO, ND, NE, OH, SD, WI |
| 3 | AL, AR, DC, DE, FL, GA, KY, LA, MD, MS, NC, OK, SC, TN, TX, VA, WV |
| 4 | AK, AZ, CA, CO, HI, ID, MT, NM, NV, OR, UT, WA, WY |
Information about the type of CPS administrative structure reflects the classification of State child welfare systems as those that are county-administered and those that are State-administered, as categorized by the American Public Human Services Association (APHSA). This State-level classification was attached to all the counties within the State. Below is a list of the States in which CPS services are county-administered.
- California
- Colorado
- Georgia
- Maryland
- Minnesota
- Nevada
- New York
- North Carolina
- North Dakota
- Ohio
- Pennsylvania
- Virginia
- Wisconsin
The county urbanicity status was determined by the county's Metropolitan Statistical Area status (urban vs. rural) as classified by the Census Bureau. The following table provides the national distribution of counties by administrative structure and urbanicity (Table A-2).
| Administrative Structure | Urban | Rural | Total |
|---|---|---|---|
| County | 354 | 631 | 985 |
| State | 494 | 1,662 | 2,156 |
| Total | 848 | 2,293 | 3,141 |
The second key feature of the sampling process was the use of differential sampling rates. It was clear that the urban stratum was much smaller than the rural stratum, while the county-administered stratum was small compared to the State-administered stratum. The urban counties and the county-administered counties were oversampled (i.e. sampled at higher rates), which ensured that the data supported analyses within each stratum.
The sample allocation was carried out hierarchically. The total sample of 300 counties was allocated to the urban and rural strata by using sampling rates that differ by a ratio of 2:1. This means that the urban counties were selected with a sampling rate twice that of the rural counties. The sample was further allocated to the administrative structure strata by the same ratio of 2:1 in favor of the county-administered counties, which similarly oversampled those counties. The resulting sample target allocation is displayed in the first half of Table A-3. To achieve the targets in the final database, a larger sample was selected in order to allow for losses due to nonresponse or refusals to participate. In all, 375 counties were sampled. The fielded county sample sizes were calculated by assuming an expected response rate of 80 percent throughout all strata (bottom portion of Table A-3).
| Administration | Urban | Rural | Total |
|---|---|---|---|
| Target sample size | |||
| County | 74 | 72 | 146 |
| State | 58 | 96 | 154 |
| Total | 132 | 168 | 300 |
| Field sample size | |||
| County | 92 | 90 | 182 |
| State | 73 | 120 | 193 |
| Total | 165 | 210 | 375 |
With this sample size, it was estimated that the expected standard errors on estimates of national proportions would not exceed 3.4 percent, assuming a design effect of 1.35. This design effect was estimated with the formula, 1+C2, where C2 was the relative variance of the sampling weights of counties, and allowed 10 percent inflation to account for nonresponse adjustment and the difference between the sampling unit (county) and unit of analysis (agency).
A power analysis was also performed to ensure the sample size provided a reasonable power for statistical tests of subgroup comparisons. The power was calculated for a normal test of whether or not the proportions of the urban and rural strata were equal. Assuming that one proportion was 50 percent and the other was 65 percent, the expected power was 62 percent for the 5 percent significance level and 73 percent for the 10 percent significance level. This meant that a 15 percent difference in proportions would be detected with a similar level of probability (e.g., 62 percent probability if the significance level of the test was 5 percent).
A list of local CPS agencies was built, beginning with existing listings of these agencies, and verifying this information via phone calls to both State and local CPS authorities in the affected counties. All identified local CPS agencies that served the sample counties were recruited for data collection. Even in cases where one or more agencies served the sampled county (as well as other counties), all the agencies linked to the selected county were included in the agency sample. This resulted in 383 agencies being included in the survey. This sample design is a variant of the network sampling method, as sampled counties served as the network to identify local CPS agencies.2
A.2 Data Collection Instrument
The first step in designing the LAS was to map the functions, activities, and components that encompass the work of CPS agencies into a list of topics. The topical list was organized by CPS function, but also included issues of policy, implementation, problems, and solutions. Once the topical list was developed, candidate questions were developed for review. The candidate questions in each topical area included some that had been tested and utilized in other surveys of CPS and other areas of child welfare. These questions were either adopted in their original form or adapted to meet the needs of this study.
The final data collection instrument was comprised of five modules. The first module inquired about the overall administration and organization of CPS. The next two modules focused on the two primary functions of CPS agencies — screening and investigation. The screening module included questions about the process by which the agency receives a referral concerning the welfare of a child and how the determination is made whether and how to respond to the referral. The investigation module included questions about the process by which the agency determines whether child maltreatment has occurred and/or the child is at risk of maltreatment.
The fourth module only applied to those agencies that have an alternative response option in addition to investigation. The fifth module included questions about the future directions of the CPS agency's administration and procedures. The agencies were instructed to have the most knowledgeable person complete each module.
Prior to finalizing the survey instrument, the LAS was pilot tested with nine agencies and reviewed by a number of experts in CPS practices. The comments and suggestions from the pilot test and expert review were incorporated into the final survey instrument.
A.3 Data collection
The survey was mailed to all 383 CPS agencies that were identified as serving the 375 sampled counties. Data collection lasted for 19 weeks — beginning February 1, 2002, and ending June 14, 2002. The targeted response rate was achieved — 307 sampled agencies completed the survey, for a response rate of 80 percent.
To facilitate data collection, 6 groups of approximately 60 to 65 agencies were targeted each week for data collection. Four main activities were involved in data collection — State solicitation, agency solicitation, survey distribution and retrieval, and nonresponse followup.
Prior to data collection, State child welfare directors were contacted to request permission to contact the sampled counties. Seven States declined to participate in the survey during this phase, which resulted in a loss of 63 potential responding agencies. Next, an initial letter was mailed to the director of each local CPS agency that introduced the study and requested the agency's participation. In addition to the letter, a "Frequently Asked Questions" sheet and a 5-page overview of the study were sent.
A confirmation call was made to the local CPS agency directors approximately 1 week after the solicitation letters were sent. The purpose of the call was to confirm the agency's participation and to respond to any questions the agency director might have. Generally, the survey was well received and most agencies agreed to consider participating. However, 36 agencies initially declined to participate in the survey.
During the confirmation calls, participating agencies were given preliminary instructions on how to complete the surveys. Multicounty agencies (CPS agencies that provide services to more than one county) and agencies that served multiagency counties (CPS agencies that share responsibility with one or more other CPS agencies for serving a single county) were given instructions on how to complete the survey to accommodate their special circumstances. Multicounty agencies that provided services to more than one county in the sample were instructed to complete only one survey for all the counties they served as long as the same practices and procedures were used. Agencies that used different procedures for different counties were instructed to complete a separate survey for each county. Agencies in multiagency counties were instructed to respond to the survey based solely on the section of the county they served.
Given the number of initial State and agency refusals, special efforts were necessary to boost the number of participating agencies to reach the targeted response rate of 80 percent. Senior members of the research team contacted the seven States that had initially denied permission for sampled counties to be included. This effort was successful and enlisted 3 additional States for the survey, which increased the number of potential respondents by 34 agencies.
An additional effort was made to enlist the support of the County Welfare Director's Association in one large State where, despite State CPS agency approval of the study, some agencies would not participate without the endorsement of the State's County Welfare Director's Association. Contact was made with the director of that association who then agreed to support the survey effort. This increased the number of potential respondents by another 13 agencies.
A receipt control database was developed to assist in administering the LAS, primarily to monitor survey progress and to create mailing lists. The tracking database recorded all contact information and agency participation status. The database was updated after each contact with an agency, as well as whenever a completed survey was received.
Survey packages were sent to those agencies that initially agreed to participate. Survey packages were also sent to any agency that had not been reached after 1 week of confirmation calls. The survey packages consisted of a confirmation letter, the five survey modules, and a return Federal Express envelope. Participating agencies were given 3 weeks to complete and return the survey.
Participating local agencies were given a toll-free telephone number and an email address to contact the survey administration team if they had any questions about the survey. The toll-free telephone number and email address were checked for incoming messages at least twice daily.
A number of efforts were taken to increase the response rate among those agencies that had initially agreed to participate in the survey but had not returned a survey. First, reminder postcards were mailed to agencies that had not returned their completed surveys within 2 weeks of receiving the initial survey package. A second survey package was sent to nonresponding agencies 4 weeks after the initial survey packages were sent. Followup calls were made to agencies that had not returned completed surveys 6 weeks after receiving their initial survey package. In addition, at the end of the survey administration period, State child welfare directors were requested to encourage nonresponding counties (and counties that had originally declined to participate in the survey) to respond.
A.4 Database Development
This section discusses the activities involved in developing the LAS database, including database design, quality control checks, resolution of database errors, and coding of text responses.
A database was designed for data entry with numeric fields to capture nominal or scale responses and text fields for text responses. Survey data were entered into the database exactly as recorded on the survey forms. The database file was saved in comma-delimited format and exported into the Statistical Package for the Social Sciences™ (SPSS) program, along with variable and value labels.
Several steps were taken to ensure the accuracy, validity, and internal consistency of data in the LAS database. A quality control check was performed on all returned surveys to verify that all modules were returned and complete. Problems encountered during this check were recorded on a quality control sheet, for followup with respondents prior to data entry.
Problems encountered during data entry (e.g., illegible responses, questions responded to incorrectly, etc.) were also documented on the quality control sheet. In addition, the database was designed to limit data entry errors by only accepting valid responses. Finally, to check for errors and make corrections, quality control and validity checks were designed and run in SPSS.
To facilitate the resolution of quality control errors in the database, the errors were divided into the following categories:
- Skip pattern violations — a response when skip pattern question directed no response should be given;
- Multiple responses — more than one response when only one response was expected;
- Missing data — questions not completed by the respondent;
- Illegible responses — response could not be read;
- Internal inconsistency — response was inconsistent with another response in the survey. (This occurred primarily among questions asking the number of personnel employed at an agency.); and
- Out of range responses — response did not fit within the specified parameters.
Different mechanisms were employed to resolve errors depending on their type. First, the team checked all errors by reviewing the hardcopy survey. When an error could not be resolved by a review of the questionnaire, an attempt was made to contact the survey respondent for clarification for the following types of errors — multiple responses, missing data, illegible responses, internal inconsistency, and out of range responses, as well as for missing modules and incomplete modules.
Skip pattern errors were recoded in SPSS. The recode was designed to accept the most logical correct response, and recode, or deselect, the "root" or followup response. In some cases, the skip pattern errors resulted in the creation of new codes. For example, some questions were frequently answered with a multiple response, when only one response was expected. Because of the frequency of this error, an additional code was developed to capture both responses selected. This allowed the data to more accurately reflect the actual practice at CPS agencies.
Finally, some errors were resolved through followup with State-level child welfare agencies. For example, after several counties in one State completed and returned their surveys, the State child welfare director indicated that on a few variables, the agencies had provided incorrect statistics. The director wanted to review the completed surveys for these counties, and provide the correct information, if necessary. The survey administration team provided the State with copies of the completed surveys, and the State in turn provided corrected surveys.
Codes were established for text response questions in some of the survey modules and added to the database. All of the open-ended responses in the fifth module were coded. In Modules 2, 3, and 4, the text responses describing the agency's responsibility for different forms of maltreatment were coded. Otherwise, the remaining text response and other/specify fields were coded only if there were more than 45 responses.
A.5 Weighting
The weighting procedures included five steps — creating county-level base weights, creating agency-level weights, adjusting for nonresponse, creating replicate weights, and creating an agency-level analysis file. Each step is described in more detail below.
The 375 counties were selected with an equal probability within each of four strata defined by urbanicity (0 = rural, 1 = urban) and administration type (0 = state, 1 = county). The county-based weight was computed as the inverse of the county selection probability, that is, Nh/nh where Nh was the number of counties on the frame in stratum h; and nh was the number of sampled counties in stratum h. The county-based weights are shown in Table A-4.
| Stratum | Number of counties on frame | Number of sampled counties | County- based weight |
|---|---|---|---|
| 00 | 1,662 | 120 | 13.850 |
| 01 | 631 | 90 | 7.011 |
| 10 | 494 | 73 | 6.767 |
| 11 | 354 | 92 | 3.848 |
| Total | 3,141 | 375 |
All 383 agencies that served the sampled 375 counties were included in the survey. Each agency was asked to report on all counties served besides the county from which the agency was sampled. While most agencies reported that they served one county, some agencies reported that they served multiple counties including unsampled counties. There were also some counties that were served by more than one agency. A more complicated situation occurred when a county was served by more than one agency, and one of the agencies serving that county also served other counties. (For Example, agency X located in sampled County A reported that it also served sampled County B, as well as nonsampled County C. Moreover, County B was served by another agency (Y), which reported that it also served sampled County A.)
To handle these various cases, a counting rule that could take care of these complexities was needed. The counting rule proposed by Sirken for network sampling was used.3 The rule assigns to each sampled agency a multiplicity factor that is the number of all the counties the agency served regardless of whether the counties were sampled or not. In the above example the multiplicity factor for agency X would be 3 and the multiplicity factor for agency Y would be 2. The distribution of the multiplicity factors is shown in Table A-5.
| Multiplicity | Number of agencies | Number of counties served |
|---|---|---|
| 1 | 285 | 285 |
| 2 | 40 | 80 |
| 3 | 27 | 81 |
| 4 | 5 | 20 |
| 5 | 9 | 45 |
| 6 | 8 | 48 |
| 7 | 8 | 56 |
| 8 | 1 | 8 |
| Total | 383 | 623 |
To assign weights to the agencies selected through the sampled counties, a county and agency combined file was created with a separate record for each unique sampled county and agency combination. Therefore, a sampled county appeared in the file as many times as it was linked to a sampled agency and the agency appeared in the file as many times as the number of sampled counties it served. In the above example, the combined file would contain four separate records as shown in Table A-6.
| Agency ID | County ID | Multiplicity |
|---|---|---|
| X05 | 086 | 3 |
| X05 | 090 | 3 |
| Y09 | 090 | 2 |
| Y09 | 086 | 2 |
This file contained 425 records, of which each was assigned a multiplicity-adjusted weight established by dividing the county-level base weight by the multiplicity factor. Note that duplicate agency records were assigned their own weights, which could be different if the county-level base weights were different. These weights were adjusted for nonresponse as explained below.
Agency nonrespondents were those whose participation was declined by their States or by their counties and those who did not return their survey questionnaires (Table A-7).
| Agency disposition | Frequency |
|---|---|
| 1 (survey returned) | 307 |
| 2 (state declined) | 31 |
| 3 (county declined) | 36 |
| 4 (survey not returned) | 9 |
| Total | 383 |
The SPSS procedure called Chi-Square Automatic Interaction Detection (CHAID) was considered for determining the significant variables for predicting response; and the significant predictors would then be used to form weighting classes for nonresponse adjustment. The variables used as the predictors were county characteristics, including per capita income, urbanicity, administrative structure, and Census region. For agencies that served multiple counties, the predictor variables were based on the characteristics of the county with the largest population. The population data were obtained from the July 1, 2001, Census county population estimates. Table A-8 shows the distributions of response status of the sampled agencies by stratum. The overall response rate was the targeted 80 percent.
| Stratum | Respondents | Nonrespondents | Total | Sample distribution | Response rate |
|---|---|---|---|---|---|
| Rural/State-administered (00) | 97 | 26 | 123 | 32% | 79% |
| Rural/county-administered (01) | 74 | 16 | 90 | 24% | 82% |
| Urban/State-administered (10) | 59 | 19 | 78 | 20% | 76% |
| Urban/county-administered (11) | 77 | 15 | 92 | 24% | 84% |
| Total | 307 | 76 | 383 | 100% | 80% |
The CHAID analysis indicated that none of the predictor variables were significant in predicting agency response. Thus, a single nonresponse adjustment factor could be used for the whole sample. However, the sampling strata were still used to define the nonresponse adjustment cells as it is simpler for variance estimation to confine all weighting adjustments within the sampling strata. Within a nonresponse adjustment cell, the nonresponse adjustment factor was computed as:
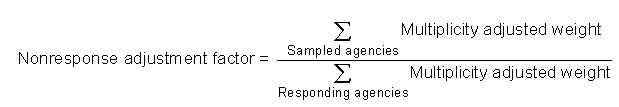
In the summations, all duplicate agency records were added separately. The nonresponse adjustment factors are shown in Table A-9.
| Stratum (adjustment cell) | Number of sampled agencies | Number of responding agencies | Nonresponse adjustment factor |
|---|---|---|---|
| 00 | 151 | 125 | 1.363 |
| 01 | 90 | 74 | 1.221 |
| 10 | 84 | 65 | 1.403 |
| 11 | 100 | 85 | 1.202 |
| Total | 425 | 349 |
The final agency-level weights were then computed as the product of the multiplicity adjusted weights and the nonresponse adjustment factor. The sum of all agency-level final weights provided an estimate of the number of CPS agencies in the nation equal to 2,607 agencies.
The jackknife (JKn) method for variance estimation was used for analyses. This method was implemented using WesVar.4 WesVar uses the JKn method for variance estimation, which requires replicate weights. The JKn method is appropriate for stratified sampling with more than two variance units per stratum.
The replicates for the JKn method were created by deleting one variance unit at a time and adjusting the weights for other variance units from the same variance stratum but leaving the other weights unchanged. The sampling strata constituted the variance strata but the variance units were formed by randomly grouping sampled counties within each stratum. Then, WesVar was used to create the replicate weights.
The variance units (VarUnits) were created to have five counties in each variance unit within each variance stratum (VarStrat). In the JKn method, the number of replicates, G, was equal to  where mh was the number of variance units in variance stratum h. There were 74 replicates, one replicate corresponding to each VarUnit. The replicate weights were formed by deleting one VarUnit at a time and adjust the weights for counties in other VarUnits in the same VarStrat. The deletion of a VarUnit was equivalent to assigning zero weight to the counties in the deleted VarUnit. For example, the replicate weights for the first replicate are defined as follows:
where mh was the number of variance units in variance stratum h. There were 74 replicates, one replicate corresponding to each VarUnit. The replicate weights were formed by deleting one VarUnit at a time and adjust the weights for counties in other VarUnits in the same VarStrat. The deletion of a VarUnit was equivalent to assigning zero weight to the counties in the deleted VarUnit. For example, the replicate weights for the first replicate are defined as follows:
- Zero for counties in VarUnit 1 in VarStrat 1;
 Times county-base weight for counties in other VarUnits 2-24 in VarStrat 1; and
Times county-base weight for counties in other VarUnits 2-24 in VarStrat 1; and- County-based weight for all others in VarStrat 2-4 (i.e., no change in their weights).
The remaining 73 replicates and their replicate weights were formed in the same manner. The replicate creation is summarized in Table A-10.
| Stratum | VarStrat | Number of counties | VarUnits | Number of replicates |
|---|---|---|---|---|
| 00 | 1 | 120 | 1 -24 | 24 |
| 01 | 2 | 90 | 1 -18 | 18 |
| 10 | 3 | 73 | 1 -14 | 14 |
| 11 | 4 | 92 | 1 -18 | 18 |
| Total | 375 | 74 |
Next, agency-level replicate weights were computed by dividing the county replicate weights by the multiplicity factor. Nonresponse adjusted agency level replicate weights were also computed.
The final step in the weighting process was to manipulate the weights to reconfigure the combined file into an agency-level file that contained only unique agency records. This was done by aggregating the weight fields at the agency level.
A.6 Analysis
Planning for the analysis began prior to data collection with the preparation of a detailed outline of the analyses to be performed. For each chapter of the final report, the outline listed the topics and tables that would appear in the chapter. For each table, the outline showed the section of the report, the specific variables needed for analysis, the topic of the table, the unit of analysis for the table, an indication of whether derived or recoded variables were needed to perform the analysis, an indication of whether the table required a subset of the data, and the statistics to be included in the table. The outline also included table shells to show how the table would appear in the final report.
The next step in preparing for analysis was to derive the variables needed for analysis. Using the outlines described above, programmer specifications were written with instructions on how to create all of the needed variables. Once the SAS program had been written and executed, the output was reviewed to check the accuracy of the derivations.
Before beginning the analysis, several sets of variables were merged onto the main database. First, the derived variables and the full sample and replicate weights were merged. Then, a select group of variables from the State policy analysis database were added to the analytic file. This included variables classifying the county as State administered, county administered or State administered with strong county structure, based upon the policy review analyses. Once all of the needed variables were merged onto the database, the analysis file was uploaded into WesVar.
In designing the analyses, the project team considered that specific subgroups of agencies could potentially provide quite different response profiles on the survey. A number of agency characteristics were identified as potentially important subgroup markers in this regard. The first analytic task was to test the utility of these candidate categorization schemes in relation to answers on a select set of survey items. The candidate schemes identified by the project team included number of CPS staff, average referrals per CPS worker, overall level of agency responsibility for functions, number of disposition categories, number of response types, administrative structure, metropolitan status, urbanicity, and median income. The project team conducted analyses on certain key tables to identify which scheme would be most informative. The tables that were examined included the following:
- Agencies that share lead responsibility with CPS for different functions;
- Involvement of law enforcement agencies for different CPS functions;
- Most common referral source;
- Overall level of responsibility for screening/intake function;
- Response options for screened-in referrals;
- Response options for screened-out referrals;
- Types of responses;
- Overall level of responsibility for functions;
- Scope of the investigation response;
- Scope of the alternative response;
- Length of time current processes in place; and
- Number of changes implemented in the last 6 months.
The categorizations schemes were tested by producing the crosstabulations necessary to complete the key tables. The project team reviewed these findings and found that income and administrative structure emerged as good candidates for further exploration. Chi-square tests were performed for most of the key tables to determine whether the distributions were significantly different for the various income categories and for the various administrative structure categories (see Table A-11). County per capita income was used for the income analysis. The agencies were divided into two groups — above the median and below the median. The chi-square analyses compared the two groups for each of the key items with the results in the table. The agency administrative structure classification used information from the State policy reviews to classify each agency into one of three groups — State-administered, county-administered, or State-administered with strong county structure. For each key item, the Chi-square analyses compared these three groups.
| Key Table* | Income | Structure | ||
|---|---|---|---|---|
| X2 Value | X2 Probability | X2 Value | X2 Probability | |
| Overall responsibility for Screening/intake | 5.893 | .253 | 22.729 | .012 |
| New referral alleging maltreatment | 20.195 | .000 | 7.633 | .470 |
| Referral for child/household with an open investigation | 6.196 | .123 | 7.577 | .476 |
| Referral for child/household with prior substantiated report | 18.142 | .001 | 7.389 | .495 |
| Referral for child/household with prior unsubstantiated report | 16.041 | .003 | 7.39 | .495 |
| Referral for child who is in foster or substitute care | 1.834 | .676 | 7.458 | .488 |
| Type of response | 1.829 | .401 | 4.62 | .329 |
| Overall responsibility for investigation response | 6.154 | .188 | 32.054 | .000 |
| Overall responsibility for alternative response | 2.238 | .815 | 11.137 | .347 |
| Scope of investigation response | 1.962 | .521 | 15.278 | .018 |
| Scope of alternative response | 1.664 | .609 | 3.631 | .534 |
| Length of time current process in place: screening/intake | 0.487 | .912 | 3.203 | .619 |
| Length of time current process in place: investigation | 2.716 | .444 | 24.414 | .000 |
| Length of time current process in place: alternative response | 2.592 | .484 | 15.772 | .009 |
| Number of changes in last 6 months | 4.26 | .284 | 5.738 | .432 |
| * Includes those key tables with mutually exclusive categories. | ||||
The objective of this report is to present estimates of the percentage and number of the Nation's 2,610 CPS agencies . The data in this report are presented in one of several formats. When the rows of a table are mutually exclusive and total to 100 percent, the estimate, confidence interval, and percentage are given for each row. The 95-percent confidence interval provides a lower and upper bound for the estimate. This means that if the current study were exactly replicated 100 times, 95 of the replications would produce an estimate within this range. For other tables, the rows of the table are not independent and thus an agency can appear in any applicable row. For these tables, estimates and/or percentages based on the total number of agencies are given. For all tables, the estimates were rounded to the nearest 10.
Endnotes
1 Sirken, M. G. (1972). Stratified Sample Surveys with Multiplicity. Journal of American Statistical Association, 67, 224-227.
2 Sirken, M. G. (1972). Stratified Sample Surveys with Multiplicity. Journal of American Statistical Association, 67, 224-227.
3 Sirken, M. G. (1972). Stratified Sample Surveys with Multiplicity. Journal of American Statistical Association, 67, 224-227.
4 Westat (2000). WesVar: WESVAR 4.0 User's Guide. Rockville, MD: Westat.
Background and Acknowledgements
This report is a component of the National Study of Child Protective Services Systems and Reform Efforts , which was conducted by Walter R. McDonald & Associates, Inc. (WRMA), in collaboration with the American Humane Association, KRA Corporation, and Westat, Inc., under contract number HHS-100-00-0017.
The authors of the report were Carol Bruce of Westat, Inc.; John Fluke of WRMA; Andrea Sedlak, and Dana Schultz of Westat, Inc.; and Ying-Ying Yuan of WRMA. Madonna Aveni and Laurie Maguire of WRMA provided technical support. Patrick Boxall and Robyn West of KRA Corporation led the data collection effort. Sampling design and statistical consultation was provided by Hyunshik Lee of Westat, Inc.
The authors wish to thank the local agencies and their staff for their contribution of time and effort to this survey.
For further information, contact the National Study of Child Protective Services Systems and Reform Efforts Federal Project Officers at the following addresses:
| Laura Radel, M.P.P. Senior Social Science Analyst Office of the Assistant Secretary for Planning and Evaluation U.S. Department of Health and Human Services 200 Independence Avenue, SW, Room 450-G Washington, DC 20201 202-690-5938 laura.radel@hhs.gov |
Catherine Nolan, M.S.W. Director, Office on Child Abuse and Neglect Children's Bureau Administration on Children, Youth and Families Administration for Children and Families U.S. Department of Health and Human Services 330 C Street, SW, Room 2419 Washington, DC 20447 202-560-5140 cnolan@acf.hhs.gov |
This publication also is available on the Internet at http://aspe.hhs.gov/hsp/cps-status03.
Material contained in this publication is in the public domain and may be reproduced, fully or partially, without permission of the Federal Government. The courtesy of attribution is requested. The recommended citation follows:
U.S. Department of Health and Human Services. Administration for Children and Families/Children's Bureau and Office of the Assistant Secretary for Planning and Evaluation. [HHS/ACF and OASPE] National Study of Child Protective Services Systems and Reform Efforts: Findings on Local CPS Practices. (Washington, DC: U.S. Government Printing Office, 2003).